

deepseekの低価格で高性能なオープンソースモデルが流行している。大量の新規ユーザーがdeepseekのウェブサイトに登録したため、ウェブサイトが何度もクラッシュした。
人工知能技術の急速な発展により、大規模言語モデル(LLM)は私たちの仕事や生活のあらゆる側面を変えつつある。
しかし、過去一定期間、多くの困難や課題も見てきた。そしてこの分野において、DeepSeekはその革新的な技術と卓越したパフォーマンスで際立っている。
最新のAIモデルであり、DeepSeekのオープンソース・マルチモーダルラージモデルであるJanus Pro DeepSeekを深掘りします。その技術的な特徴、開発の歴史、実用的な応用価値について学びます。
何なのか? Janus Pro ディープシーク?
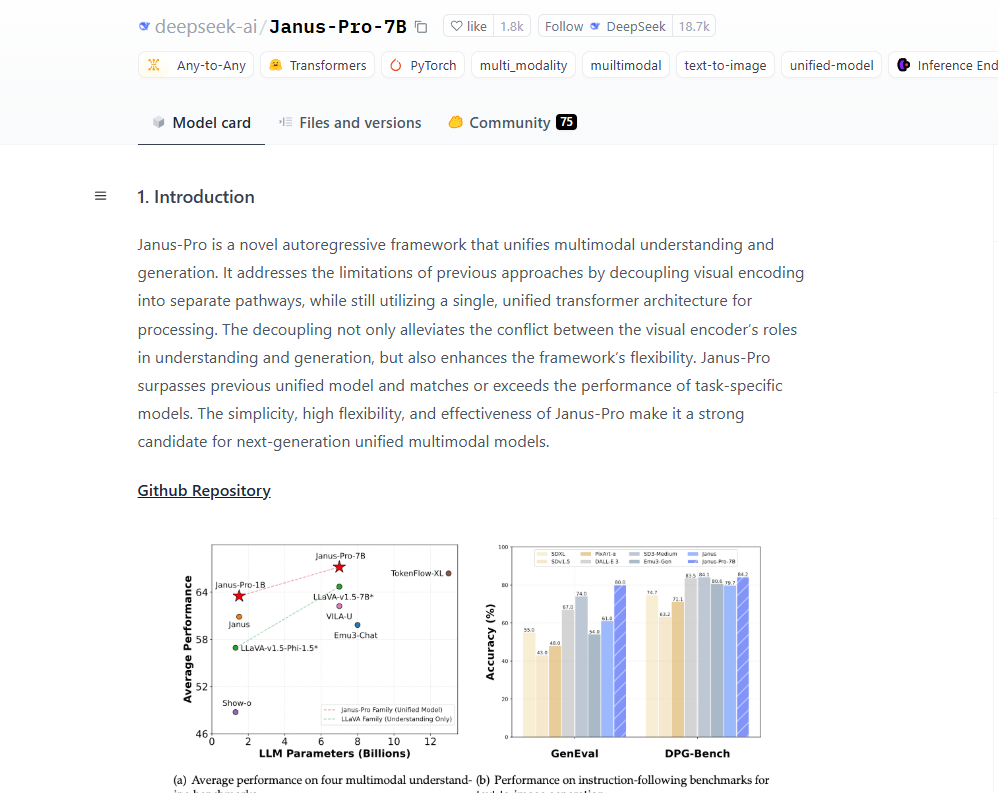
Janus Proは、DeepSeekチームによって公開されたオープンソースのマルチモーダルAIモデルで、主に画像理解と画像生成に使用される。
コア機能
- マルチモーダルな理解と生成:Janus Proは、テキストと画像を同時に処理することができ、画像の内容を理解し、テキストの記述に基づいて画像を生成することができます。
- オープンソースと大規模モデル:1Bと7Bの2種類のパラメータサイズがあり、オープンソースで市販されている。
開発 Janus Pro ディープシーク
設立と発展
- 2023年7月:ディープシークは正式に設立され、杭州に本社を置き、一般人工知能(AGI)分野の研究開発に注力しています。
- 2023年11月2日:複数のプログラミング言語でのコード生成、デバッグ、データ分析タスクをサポートする初のオープンソース・コード大規模モデルDeepSeek Coderをリリース。
- 2023年11月29日:パラメータスケール670億の汎用ラージモデルDeepSeek LLMを発表。7Bと670Bのベースバージョンとチャットバージョンを含む。
技術的ブレークスルーと製品の反復
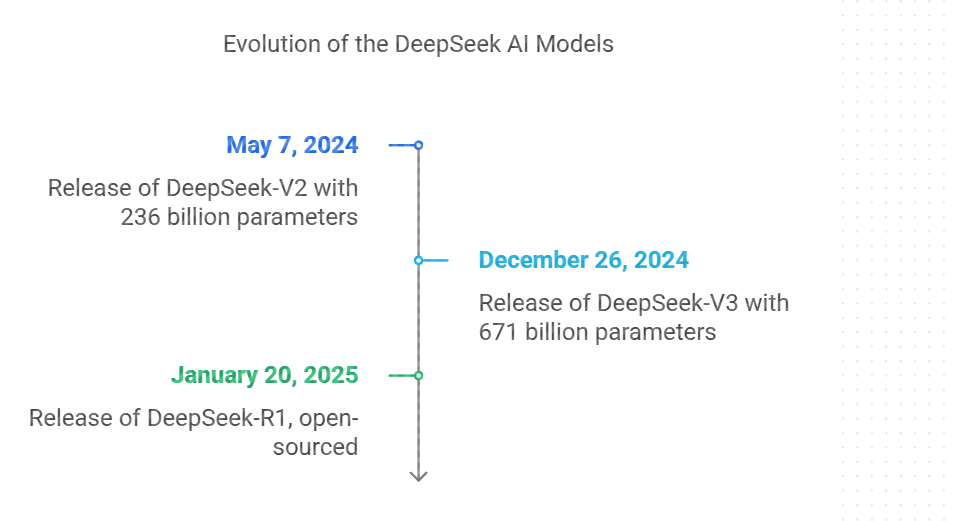
- 2024年5月7日:第2世代のオープンソースハイブリッドエキスパート(MoE)モデルであるDeepSeek-V2がリリースされ、総パラメータ数は2360億、推論コストは100万トークンあたりわずか1元に削減された。
- 2024年12月26日:DeepSeek-V3がリリースされ、総パラメータ数は6710億。革新的なMoEアーキテクチャとFP8混合精度トレーニングを採用し、トレーニングコストはわずか557万USドル。
- 2025年1月20日:新世代の推論モデル「DeepSeek-R1」がリリース。OpenAIのo1正式版と同等の性能を持ち、オープンソース化もされている。
1月27日 janus proマルチモーダルモデル より多くの人々が大規模なAIモデルの開発プロセスに参加し、限られたリソースで最新のAI技術を利用・学習できるようにするためだ。
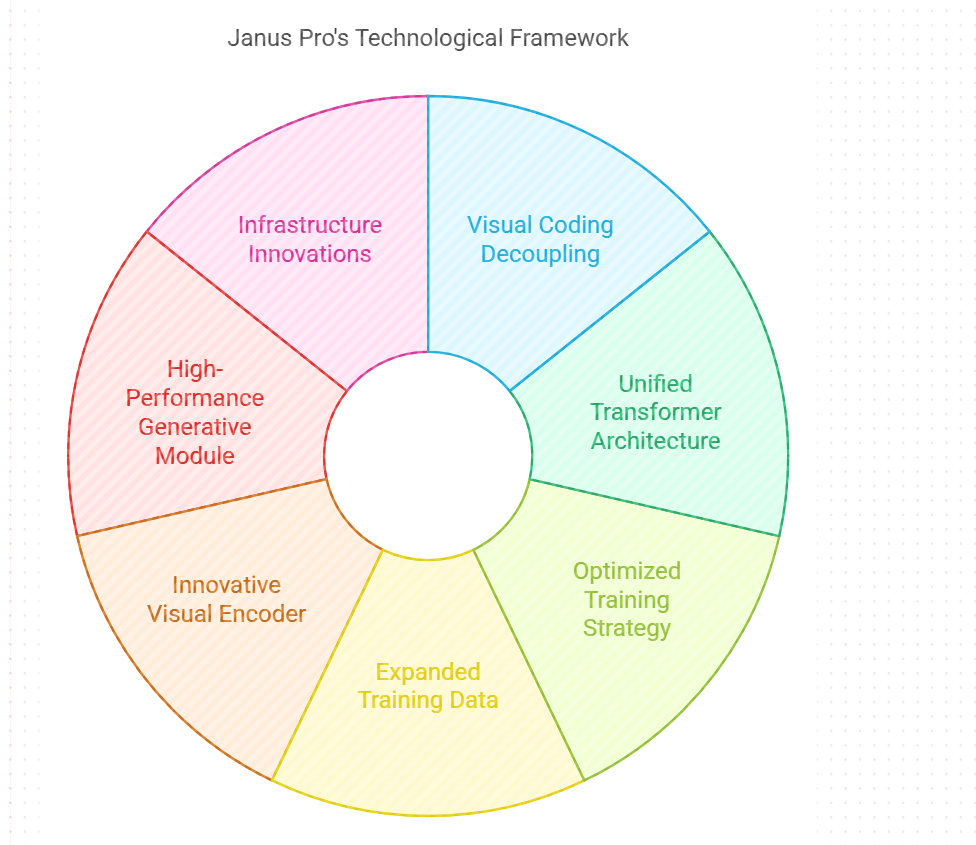
Janus Pro ディープシークのコア技術
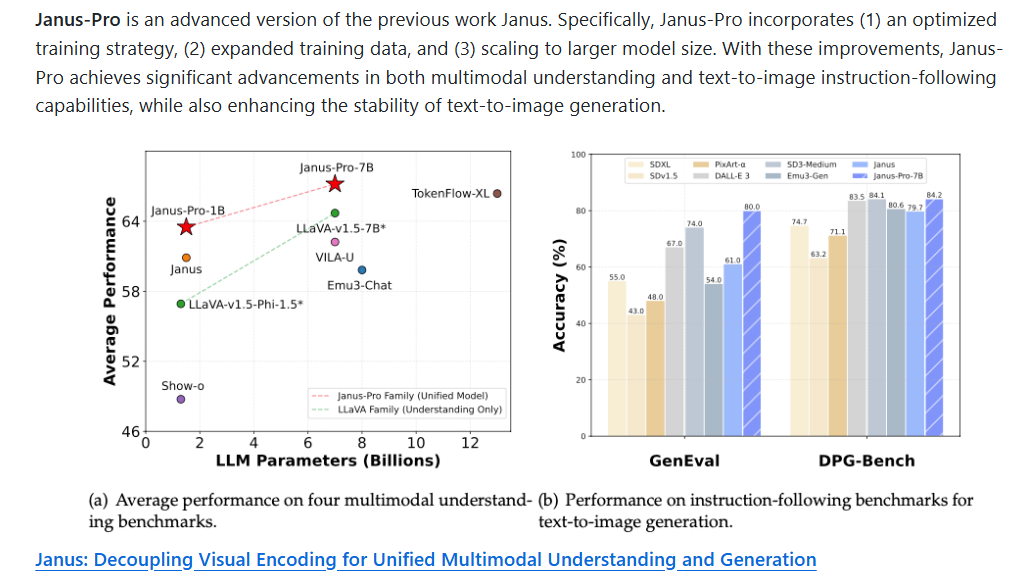
ビジュアル・コーディングのデカップリング
Janus Proは、視覚エンコーディング経路を独立した処理経路に分割し、それぞれをマルチモーダル理解タスクと生成タスクに使用する視覚エンコーディングデカップリング技術を採用しています。この設計により、従来のマルチモーダルモデルにおける理解タスクと生成タスクの視覚エンコーダ間の機能衝突の問題を効果的に解決し、モデルの柔軟性とタスク適応性を向上させている。
ユニファイド・トランスフォーマー・アーキテクチャ
ビジュアルエンコーディングパスの切り離しにもかかわらず、Janus Proはマルチモーダルなタスクを処理するために単一のトランスフォーマーアーキテクチャを使用しています。この統一されたアーキテクチャは、モデルの設計を簡素化すると同時に、モデルのスケーラビリティと、タスク間で連携するモデルの能力を向上させます。
最適化されたトレーニング戦略
Janus Proは、トレーニング戦略に以下のような最適化を行った。
- ImageNetデータセットの学習時間を延長し、モデルの画像理解能力を向上させる。
- テキストから画像への学習データに焦点を当て、モデルの生成能力を最適化する。
- 学習データの割合を調整することで、モデルはマルチモーダルなタスクでより安定した効率的なパフォーマンスを発揮する。
拡張トレーニングデータ
Janus Proは、マルチモーダル理解データや視覚生成データなど、大規模かつ多様な学習データを使用する。このようなデータの拡充は、モデルの理解能力を向上させるだけでなく、生成品質も高める。
革新的なビジュアル・エンコーダ
マルチモーダル理解タスクのために、Janus Proは視覚エンコーダーとしてSigLIP-Lを使用し、最大384×384の解像度の画像入力をサポートしています。この高解像度サポートにより、モデルはより多くの画像の詳細を捉えることができ、視覚理解の精度が向上します。
高性能生成モジュール
画像生成タスクのために、Janus Proはより詳細な画像を生成するためにダウンサンプリングレート16のLlamaGen Tokenizerを使用しています。この設計により、生成される画像はよりリアルで詳細になります。
インフラ革新
Janus Proは、DeepSeek-LLM-1.5bおよびDeepSeek-LLM-7bモデルに基づいて構築されており、強力なマルチモーダル処理機能を備えているため、マルチモーダル理解と生成タスクに優れています。
マルチモーダルな理解と生成能力
Janus Proは、マルチモーダルな理解タスク(視覚的質問応答や画像キャプション付けなど)を処理できるだけでなく、テキスト記述から高品質の画像を生成することもできる。この能力により、Janus Proはマルチモーダルシナリオに優れています。
Janus Pro DeepSeekのパフォーマンス
DeepSeekのJanus-Proモデルは、マルチモーダル理解と生成タスクに優れています。以下は、その性能の詳細な分析である:
マルチモーダル理解パフォーマンス
- MMBenchベンチマークJanus-Pro-7Bは、マルチモーダル理解のMMBenchベンチマークで79.2点を達成し、Janus(69.4点)、TokenFlow(68.9点)、MetaMorph(75.2点)など、既存の最先端の統一マルチモーダルモデルを上回った。
- 視覚的な質問回答Janus-Proの視覚的質問回答精度はGPT-4Vを上回り、画像の詳細を正確に識別し、関連する質問に回答する。
テキストから画像へのコマンドトラッキング
- GenEval ベンチマークテスト:Janus-Pro-7Bは、GenEvalテストにおいて80%の総合精度を達成し、DALL-E 3(67%)やStable Diffusion 3 Medium(74%)といった他のモデルを大きく上回った。
複雑なコマンドの理解DPG-Benchテストにおいて、Janus-Pro-7Bは84.19ポイントという素晴らしいスコアを記録し、「頂上に青い湖がある雪山」といった複雑なシーンを正確に生成することができた。
テキストから画像への生成パフォーマンス
- 画質と安定性:出力解像度は384×384であるにもかかわらず、Janus-Pro-7Bが生成する画像は高いリアリズムと豊かなディテールを示し、特に想像力豊かで創造的なシーンを処理する場合に優れている。プロンプトワードの意味情報を正確に理解し、論理的に合理的で首尾一貫した画像を生成できる。
- 生成速度:Janus-Proは1枚のカードで4K画像の生成をサポートし、これはStable Diffusion 3より2倍速い。
モデル・アーキテクチャとトレーニング
- 視覚エンコーディングのデカップリングJanus-Proは、マルチモーダル理解・生成タスクにおける視覚的エンコーディングのデカップリングを実現するために、元の入力を特徴量に変換する独立したエンコーディング手法を使用します。
- トレーニングデータJanus-Proは、実データと合成データの比率を1:1にするため、7200万枚の高品質な合成画像をトレーニングに組み込んでいます。また、約9,000万サンプルのマルチモーダル理解トレーニングデータを追加し、モデルのパフォーマンスを大幅に向上させます。
拡張性と展開
モデルサイズJanus-Proシリーズは、性能と計算コストの両方を考慮し、より多くのユースケースに適した1Bと7Bのパラメータサイズのモデルを提供しています。
最小限のデプロイメントJanus-ProはMITライセンスでリリースされ、商用利用をサポートし、2つのバージョンを提供しています:1.5B(16GBのVRAMが必要)と7B(24GBのVRAMが必要)の2つのバージョンがあり、標準的なGPUで動作する。
Janus Pro DeepSeekの実用化シナリオ
AIマルチモーダルモデル、特にテキストから画像へのモデルは、商業分野での発展に大きな可能性を秘めている。長い開発期間を経て、AIテキスト画像モデルはすでに大きな進歩を遂げている。
広告やポスターデザインの最も一般的なシナリオでは、デザイナーやユーザーはJanus proを使用してテキスト説明を入力し、高品質のポスターをすばやく生成できます。ポスターのプロトタイプを繰り返し作成することで、デザイン時間を節約し、クリエイティブ効率を向上させることができます。これにより、デザイナーの作業効率が大幅に向上し、より有意義なことに時間を費やすことができます。
aiラージモデルは、従来のポスターデザインや広告デザインに加え、昨今人気のゲームシーンにおいても、デザイナーがゲームシーンやキャラクター、アイテムをリアルタイムに生成することで、開発コストや難易度を抑えつつ、ゲームのビジュアル効果を向上させることができます。私たちは、aiラージモデルがクリエイターの可能性と想像力を引き出し続け、より面白いプロダクトを実現できると信じています。
デザインの分野だけでなく、学習、教育、医療という専門的な垂直分野においても、マルチモーダルモデルは大きな発展を遂げるだろう。
将来的には、私たちの生活の効率と質を大幅に向上させる非常に興味深いアプリケーションが出現するかもしれない。
一方、Janus-Proのオープンソース機能(MITライセンス)と最小限の導入方法(標準GPUでの実行をサポート)は、さらに参入障壁を下げ、上記の分野に広く適用できる。
これにより、より多くのユーザーが開発に参加できるようになり、より多くの人々がこれらの機能を向上させ、コミュニティ全体の能力を高めることができる。
Janus Pro DeepSeekの適切なバージョンの選択方法を教えてください。
Janus-Proは2つのバージョンでオープンソース化されている:Janus-Pro-1BとJanus-Pro-7Bです。どちらのバージョンを選択するかは、特定のニーズ、コンピューティングリソース、アプリケーションシナリオに依存します。以下は、詳細な比較と推奨事項です:
適用シナリオ
Janus-Pro-1B:
- 軽量アプリケーション:モバイルデバイス、ブラウザ、またはリソースが制限された環境での使用に適しています。これにより、より多くのユーザーが最新のヤヌス・プロを体験することができます。
- ラピッドプロトタイピング:多くのコンピューティングリソースを必要とせず、マルチモーダル機能の迅速な開発とテストに適している。これはAIの愛好家にとって非常に重要であり、多くのコンピューティングリソースを必要とすることなく、研究において遭遇する問題を素早く反復し、発見することができる。
Janus-Pro-7B:
- 高画質画像生成:広告デザイン、ゲーム開発、芸術的創作など、複雑なシーンの高画質画像生成を必要とする用途に適しています。このモデルは、より強力なハードウェア機能とより強力なコンピューティング能力を必要とする、より専門的なデザインシナリオに適している
- 複雑な命令の理解:バーチャルリアリティ(VR)や拡張現実(AR)など、複雑なテキスト命令を処理し、正確な画像を生成する必要があるシナリオに適している。
配備要件
Janus-Pro-1B:
- ハードウェア要件:16GBのVRAMを必要とするGPUなど、リソースに制約のあるデバイスでの実行に適しています。以前のグラフィックカードしかお持ちでない場合は、こちらの方が適しているかもしれません。
- アプリケーション・シナリオ:ブラウザでの実行や軽量デバイスでの展開に適している。
Janus-Pro-7B:
- ハードウェア要件:24GBのVRAMを搭載したGPUなど、より高いコンピューティングリソースが必要です。これは、新しいグラフィックカードを使用しているユーザーに適しています。
- アプリケーションシナリオ:標準的なGPUでの実行や、高いパフォーマンスを必要とするシナリオに適している。
概要
アプリケーション・シナリオが高画質と複雑な命令理解を必要とし、十分なコンピューティング・リソースがある場合は、Janus-Pro-7Bをお勧めします。
軽量な導入が必要な場合やコンピューティングリソースが限られている場合は、Janus-Pro-1Bをお勧めします。
地域社会の支援とリソース
DeepSeekは、開発者に豊富なリソースとサポートを提供します:
- 公式ドキュメントでは、APIインターフェースの詳細な説明や、モデルの微調整、デプロイメントチュートリアルなどのテクニカルガイドを提供しています。
- 開発者コミュニティは、開発者間の経験交流を促進するためのフォーラムやディスカッショングループを提供しています。定期的な技術共有セッションやハッカソンも開催されています。
- テクニカルサポートは、ユーザーが使用中に遭遇した問題を解決するための専門的な技術サポートサービスを提供します。



