
Ⅰ. Ce este distilarea cunoștințelor?
Distilarea cunoștințelor este o tehnică de comprimare a modelelor utilizată pentru a transfera cunoștințe de la un model mare și complex (modelul profesorului) la un model mic (modelul elevului).
Principiul de bază este că modelul profesor îl învață pe modelul elev prin prezicerea rezultatelor (cum ar fi distribuțiile de probabilități sau procesele de inferență), iar modelul elev își îmbunătățește performanța învățând din aceste preziceri.
Această metodă este potrivită în special pentru dispozitive cu resurse limitate, cum ar fi telefoanele mobile sau dispozitivele integrate.
II.Concepte de bază
2.1 Proiectarea șablonului
- Șablon: Un format structurat utilizat pentru standardizarea rezultatelor modelului. De exemplu
- : Marchează începutul procesului de raționament.
- : Marchează sfârșitul procesului de raționament.
- : Marchează începutul răspunsului final.
- : Marchează sfârșitul răspunsului final.
- Funcție:
- Claritate: La fel ca "cuvintele cheie" dintr-o întrebare de completat spațiile goale, aceasta spune modelului "procesul de gândire merge aici, iar răspunsul merge acolo".
- Coerență: Asigură faptul că toate rezultatele urmează aceeași structură, facilitând prelucrarea și analiza ulterioară.
- lizibilitate: ființele umane pot distinge cu ușurință între procesul de raționament și răspuns, îmbunătățind experiența utilizatorului.
2.2 Traiectoria raționamentului: "Lanțul de gândire" al soluției modelului
- Traiectoria raționamentului: Etapele detaliate generate de model atunci când rezolvă o problemă arată lanțul logic al modelului.
- Exemplu:
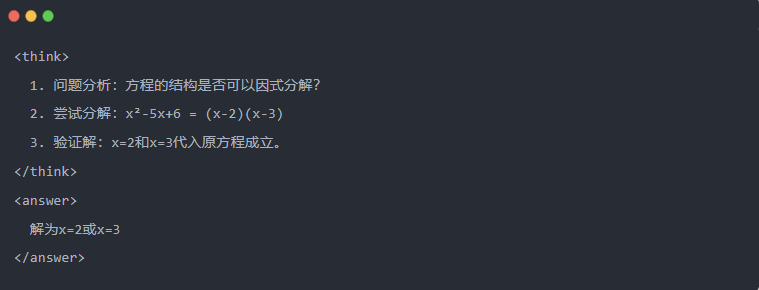
2.3 Eșantionarea de respingere: Filtrarea datelor bune din "încercări și erori
- Eșantionare de respingere: Generarea mai multor răspunsuri ale candidaților și reținerea celor bune, similar cu scrierea unui proiect și apoi copierea răspunsului corect la un examen.
Ⅲ.Generarea de date distilate
Primul pas în distilarea cunoștințelor este de a genera "date de predare" de înaltă calitate din care modelele mici să învețe.
Surse de date:
- 80% din datele de raționament generate de DeepSeek-R1
- 20% din datele generale ale sarcinii DeepSeek-V3.
Procesul de generare a datelor de distilare:
- Filtrarea regulilor: verifică automat corectitudinea răspunsului (de exemplu, dacă răspunsul matematic este conform formulei).
- Verificarea lizibilității: elimină limbile mixte (de exemplu, chineză și engleză mixte) sau paragrafele lungi.
- Generarea ghidată de șablon: necesită ca DeepSeek-R1 să producă traiectorii de inferență în conformitate cu modelul.
- Filtrarea eșantionării de respingere:
- Integrarea datelor: 800.000 de probe de înaltă calitate au fost generate în cele din urmă, inclusiv aproximativ 600.000 de date de inferență și aproximativ 200.000 de date generale.
Ⅳ.Procesul de distilare
Rolurile profesorului și ale elevului:
- DeepSeek-R1 ca model de profesor;
- Modele din seria Qwen ca model de student.
Etape de formare:
În primul rând, introducerea datelor: trebuie să introduceți partea de întrebare din cele 800 000 de eșantioane în modelul Qwen și să îi cereți să genereze o traiectorie de inferență completă (proces de gândire + răspuns) în conformitate cu modelul. Acesta este un pas foarte important
În continuare, calculul pierderilor: comparați rezultatul generat de modelul elevului cu traiectoria de inferență a modelului profesorului și aliniați secvența de text prin reglarea fină supravegheată (SFT). Dacă nu sunteți sigur ce este SFT, sper că veți căuta acest cuvânt-cheie pentru a afla mai multe
Completați actualizările parametrilor pentru modelul mai mare al elevului: Optimizați parametrii modelului Qwen prin retropropagare pentru a aproxima rezultatul modelului profesorului.
Repetarea acestui proces de formare de mai multe ori asigură un transfer suficient de cunoștințe. Astfel se atinge obiectivul inițial al formării. Vă vom da un exemplu pentru a demonstra acest lucru și sperăm că veți înțelege
Ⅴ. Exemplu demonstrativ
Articolul demonstrează efectul de distilare prin intermediul unei sarcini specifice de rezolvare a unei ecuații (rezolvarea ecuației):
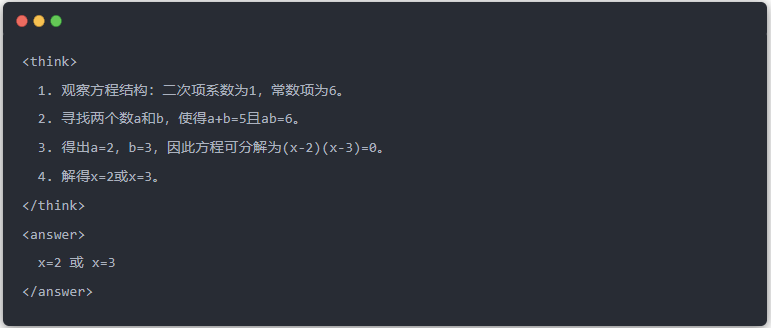
- Rezultat standard al modelului profesorului:
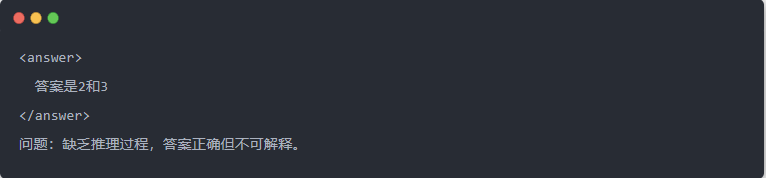
- Producția Qwen-7B înainte de distilare:
- Qwen-7B rezultat după distilare:
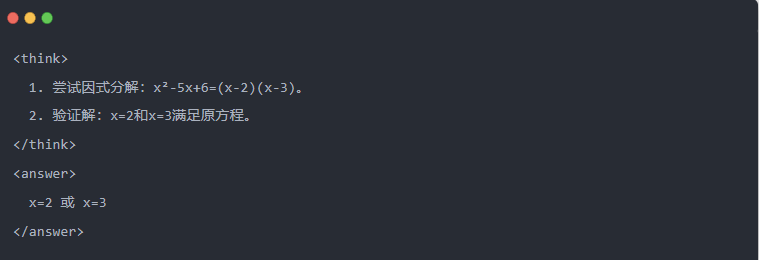
- Soluție optimizată: Este generat un proces de inferență structurat, iar răspunsul este același cu modelul profesorului.
Ⅵ. Rezumat
Prin distilarea cunoștințelor, capacitatea de inferență a DeepSeek-R1 este transferată eficient către seria Qwen de modele mici. Acest proces se concentrează pe ieșirea șablonată și pe eșantionarea respingerii. Prin generarea de date structurate și formarea rafinată, modelele mici pot efectua, de asemenea, sarcini complexe de inferență în scenarii cu resurse limitate. Această tehnologie oferă o referință importantă pentru implementarea ușoară a modelelor AI.


