
Ⅰ. What is knowledge distillation?
Knowledge distillation is a model compression technique used to transfer knowledge from a large, complex model (the teacher model) to a small model (the student model).
The core principle is that the teacher model teaches the student model by predicting results (such as probability distributions or inference processes), and the student model improves its performance by learning from these predictions.
This method is particularly suitable for resource-constrained devices such as mobile phones or embedded devices.
II.Core concepts
2.1 Template design
- Template: A structured format used to standardize model output. For example
- : Marks the beginning of the reasoning process.
- : Marks the end of the reasoning process.
- : Marks the beginning of the final answer.
- : Marks the end of the final answer.
- Function:
- Clarity: Like the “prompt words” in a fill-in-the-blank question, it tells the model “the thinking process goes here, and the answer goes there.”
- Consistency: Ensures that all outputs follow the same structure, facilitating subsequent processing and analysis.
- Readability: Human beings can easily distinguish between the reasoning process and the answer, improving the user experience.
2.2 Reasoning trajectory: The “thinking chain” of the model’s solution
- Reasoning trajectory: The detailed steps generated by the model when solving a problem show the logical chain of the model.
- Example:
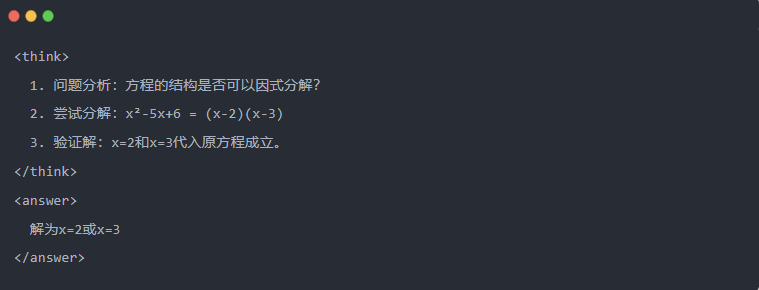
2.3 Rejection sampling: Filtering good data from “trial and error
- Rejection sampling: Generate multiple candidate answers and retain the good ones, similar to writing a draft and then copying the correct answer in an exam.
Ⅲ.Generation of distilled data
The first step in knowledge distillation is to generate high-quality ‘teaching data’ for small models to learn from.
Data sources:
- 80% from the reasoning data generated by DeepSeek-R1
- 20% from DeepSeek-V3 general task data.
Distillation data generation process:
- Rule filtering: automatically checks the correctness of the answer (e.g. whether the mathematical answer conforms to the formula).
- Readability check: eliminates mixed languages (e.g. Chinese and English mixed) or lengthy paragraphs.
- Template-guided generation: requires DeepSeek-R1 to output inference trajectories according to the template.
- Rejection sampling filtering:
- Data integration: 800,000 high-quality samples were finally generated, including about 600,000 inference data and about 200,000 general data.
Ⅳ.Distillation process
Teacher and student roles:
- DeepSeek-R1 as the teacher model;
- Qwen series models as the student model.
Training steps:
First, data input: you need to input the question part of the 800,000 samples into the Qwen model and ask it to generate a complete inference trajectory (thinking process + answer) according to the template. This is a very important step
Next, loss calculation: compare the output generated by the student model with the inference trajectory of the teacher model, and align the text sequence through supervised fine-tuning (SFT). If you are not sure what SFT is, I hope you will search for this keyword to learn more
Complete parameter updates for the student’s larger model: Optimize the parameters of the Qwen model through backpropagation to approximate the output of the teacher model.
Repeating this training process multiple times ensures that knowledge is sufficiently transferred. This achieves the original training objective. We will give you an example to demonstrate this, and we hope you will understand
Ⅴ. Example demonstration
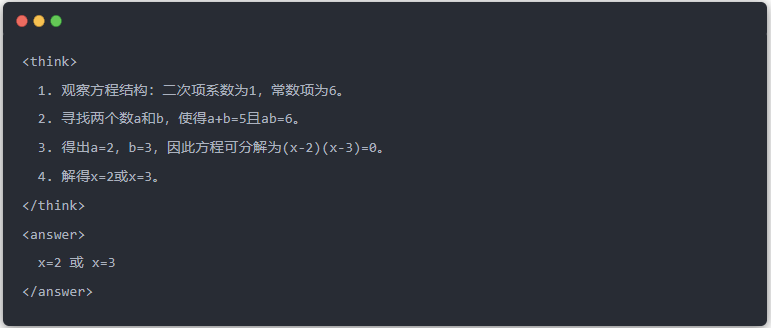
The article demonstrates the distillation effect through a specific equation solving task (solve equation):
- Standard output of the teacher model:
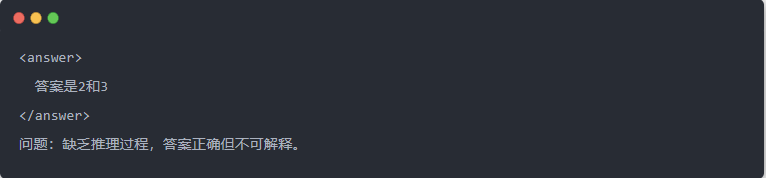
- Qwen-7B output before distillation:
- Qwen-7B output after distillation:
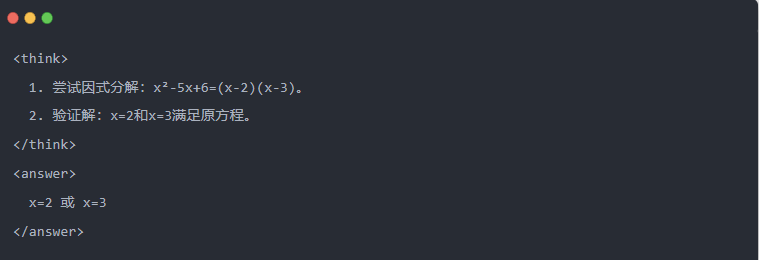
- Optimized solution: A structured inference process is generated, and the answer is the same as the teacher model.
Ⅵ. Summary
Through knowledge distillation, the inference ability of DeepSeek-R1 is efficiently migrated to the Qwen series of small models. This process focuses on templated output and rejection sampling. Through structured data generation and refined training, small models can also perform complex inference tasks in resource-constrained scenarios. This technology provides an important reference for lightweight deployment of AI models.



