
Ⅰ. ما هو تقطير المعرفة؟
تقطير المعرفة هو تقنية ضغط النموذج المستخدمة لنقل المعرفة من نموذج كبير ومعقد (نموذج المعلم) إلى نموذج صغير (نموذج الطالب).
يتمثل المبدأ الأساسي في أن نموذج المعلم يعلّم نموذج الطالب من خلال التنبؤ بالنتائج (مثل التوزيعات الاحتمالية أو عمليات الاستدلال)، ويحسّن نموذج الطالب أداءه من خلال التعلم من هذه التنبؤات.
هذه الطريقة مناسبة بشكل خاص للأجهزة ذات الموارد المحدودة مثل الهواتف المحمولة أو الأجهزة المدمجة.
ثانياً- المفاهيم الأساسية
2.1 تصميم القالب 2.1
- قالب: تنسيق منظم يستخدم لتوحيد مخرجات النموذج. على سبيل المثال
- : يمثل بداية عملية الاستدلال.
- : يمثل نهاية عملية الاستدلال.
- : يمثل بداية الإجابة النهائية.
- : يشير إلى نهاية الإجابة النهائية.
- الوظيفة:
- الوضوح: مثل "الكلمات الموجّهة" في سؤال ملء الفراغ، فهي تخبر النموذج "عملية التفكير تجري هنا، والإجابة تجري هنا".
- الاتساق: يضمن أن جميع المخرجات تتبع نفس الهيكل، مما يسهل المعالجة والتحليل اللاحقين.
- سهولة القراءة: يمكن للبشر التمييز بسهولة بين عملية التفكير والإجابة، مما يحسن من تجربة المستخدم.
2.2 مسار التفكير: "سلسلة التفكير" الخاصة بحل النموذج
- مسار التفكير المنطقي: تُظهر الخطوات التفصيلية التي يولدها النموذج عند حل مشكلة ما التسلسل المنطقي للنموذج.
- مثال على ذلك:
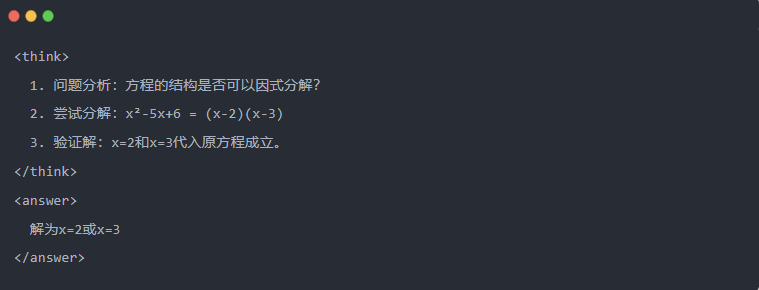
2.3 أخذ عينات الرفض: تصفية البيانات الجيدة من "التجربة والخطأ
- أخذ عينات الرفض: توليد العديد من الإجابات المرشحة والاحتفاظ بالإجابات الجيدة، على غرار كتابة مسودة ثم نسخ الإجابة الصحيحة في الامتحان.
Ⅲ توليد البيانات المقطرة
تتمثل الخطوة الأولى في عملية تقطير المعرفة في توليد "بيانات تعليمية" عالية الجودة لتتعلم منها النماذج الصغيرة.
مصادر البيانات:
- 80% من البيانات المنطقية الناتجة عن ديبسيك-آر1
- 20% من بيانات المهمة العامة DeepSeek-V3.
عملية توليد بيانات التقطير:
- تصفية القواعد:: يتحقق تلقائيًا من صحة الإجابة (على سبيل المثال ما إذا كانت الإجابة الرياضية مطابقة للصيغة).
- التحقق من سهولة القراءة:: التخلص من اللغات المختلطة (مثل الصينية والإنجليزية المختلطة) أو الفقرات الطويلة.
- التوليد الموجه بالقالب:: يتطلب من DeepSeek-R1 إخراج مسارات الاستدلال وفقًا للقالب.
- تصفية أخذ العينات المرفوضة:
- تكامل البيانات:: تم أخيرًا توليد 800,000 عينة عالية الجودة، بما في ذلك حوالي 600,000 بيانات استدلالية وحوالي 200,000 بيانات عامة.
Ⅳ عملية التقطير
أدوار المعلم والطالب:
- DeepSeek-R1 كنموذج المعلم;
- نماذج سلسلة Qwen كنموذج الطالب.
خطوات التدريب:
أولاً، مدخلات البيانات: تحتاج إلى إدخال جزء السؤال من الـ 800,000 عينة في نموذج Qwen وتطلب منه توليد مسار استدلالي كامل (عملية التفكير + الإجابة) وفقًا للقالب. هذه خطوة مهمة للغاية
بعد ذلك، حساب الخسارة: قارن المخرجات الناتجة عن نموذج الطالب مع مسار الاستدلال لنموذج المعلم، وقم بمحاذاة تسلسل النص من خلال الضبط الدقيق تحت الإشراف (SFT). إذا لم تكن متأكدًا من ماهية SFT، آمل أن تبحث عن هذه الكلمة الرئيسية لمعرفة المزيد
استكمال تحديثات المعلمات لنموذج الطالب الأكبر: قم بتحسين معلمات نموذج كوين من خلال الترحيل العكسي لتقريب مخرجات نموذج المعلم.
يضمن تكرار عملية التدريب هذه عدة مرات نقل المعرفة بشكل كافٍ. وهذا يحقق هدف التدريب الأصلي. سنعطيك مثالاً لتوضيح ذلك، ونأمل أن تفهم ما يلي
Ⅴ. مثال توضيحي
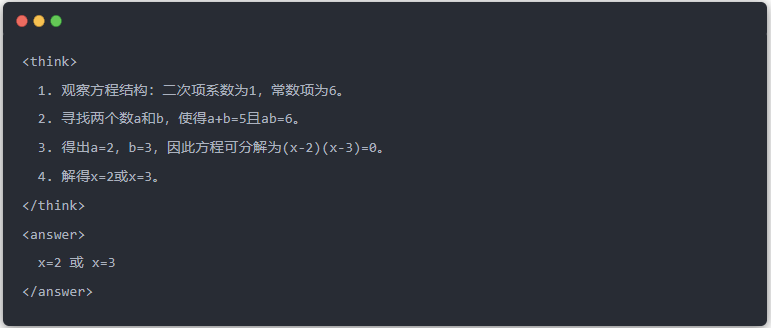
يوضح المقال تأثير التقطير من خلال مهمة حل معادلة محددة (حل المعادلة):
- المخرجات القياسية لنموذج المعلم:
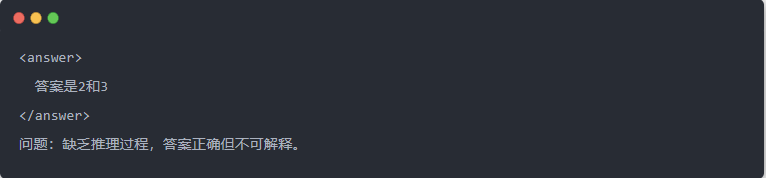
- ناتج Qwen-7B قبل التقطير:
- ناتج Qwen-7B بعد التقطير:
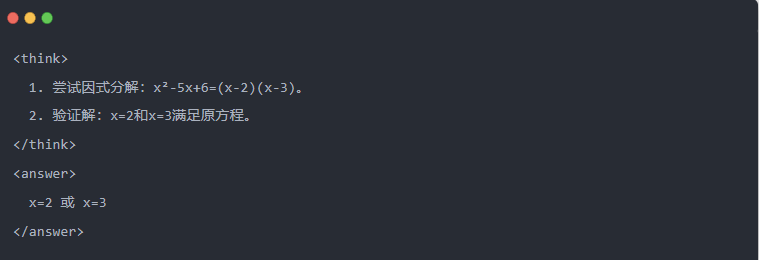
- الحل الأمثل: يتم إنشاء عملية استدلال منظمة، وتكون الإجابة هي نفس نموذج المعلم.
Ⅵ. ملخص
من خلال التقطير المعرفي، يتم ترحيل القدرة الاستدلالية لـ DeepSeek-R1 بكفاءة إلى سلسلة Qwen للنماذج الصغيرة. تركز هذه العملية على المخرجات النموذجية وأخذ عينات الرفض. ومن خلال توليد البيانات المهيكلة والتدريب المحسّن، يمكن للنماذج الصغيرة أيضًا أداء مهام الاستدلال المعقدة في سيناريوهات محدودة الموارد. توفر هذه التقنية مرجعًا مهمًا للنشر الخفيف لنماذج الذكاء الاصطناعي.



