
and the AI era has quietly arrived.
Probably no one expected that this Chinese New Year, the hottest topic would no longer be the traditional Internet red envelope battle, who partnered with the Spring Festival Gala, but AI companies.
As the Spring Festival approached, major model companies did not relax at all, updating a wave of models and products. However, the most talked about was DeepSeek, a “major model company” that emerged last year.
On the evening of January 20, DeepSeek released the official version of its reasoning model DeepSeek-R1. Using a low training cost, it directly trained a performance that is not inferior to the OpenAI reasoning model o1. Moreover, it is completely free and open source, which directly triggered an industry earthquake.
This is the first time that a domestic AI has caused a stir in the tech world on a large scale around the world, especially in the United States. Developers have expressed that they are considering using DeepSeek to “rebuild everything.” In the wake of this wave, after a week of fermentation, and even just released in January, the DeepSeek mobile app quickly reached the top of the free app rankings on the Apple App Store in the US, surpassing not only ChatGPT, but also other popular apps in the US.
The success of DeepSeek has even directly affected the US stock market. A model trained without using a huge amount of expensive GPUs has made people rethink the training path of AI, directly causing the biggest drop of 17% in the AI’s first stock, NVIDIA.
And that’s not all.
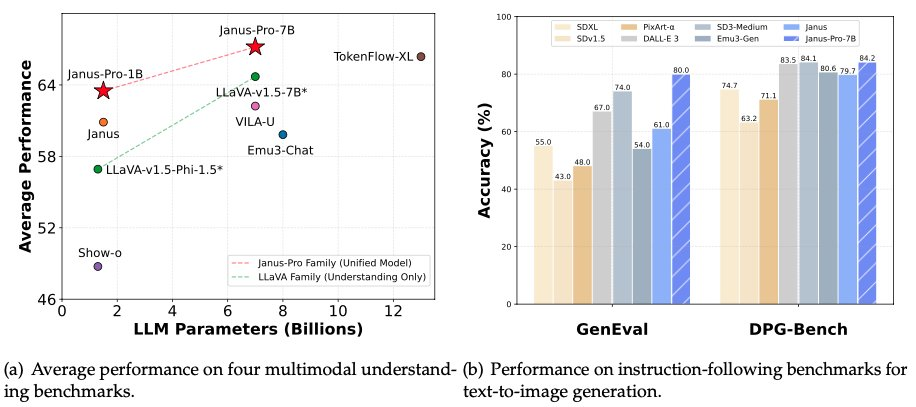
In the early morning of January 28, the night before New Year’s Eve, DeepSeek once again opened source its multimodal model Janus-Pro-7B, announcing that it had defeated DALL-E 3 (from OpenAI) and Stable Diffusion in the GenEval and DPG-Bench benchmark tests.
Is DeepSeek really going to sweep the AI community? From inference models to multimodal models, is DeepSeek restructuring everything the first topic of the Year of the Snake?
Janus Pro, the validation of an innovative multimodal model architecture
DeepSeek released a total of two models late at night this time: Janus-Pro-7B and Janus-Pro-1B (1.5B parameters).
As the name suggests, the model itself is an upgrade from the previous Janus model.
DeepSeek only released the Janus model for the first time in October 2024. As usual with DeepSeek, the model adopts an innovative architecture. In many vision generation models, the model adopts a unified Transformer architecture that can simultaneously process the tasks of text-to-image and image-to-text.
DeepSeek proposes a new idea, decoupling the visual encoding of the understanding (graph-to-text) and generation tasks (text-to-graph), which improves the flexibility of model training and effectively alleviates the conflicts and performance bottlenecks caused by using a single visual encoding.
This is why DeepSeek named the model Janus. Janus is the ancient Roman god of doors and is depicted with two faces facing opposite directions. DeepSeek said that the model is named Janus because it can look at visual data with different eyes, encode features separately, and then use the same body (Transformer) to process these input signals.
This new idea has produced good results in the Janus series of models. The team says that the Janus model has strong command following capabilities, multilingual capabilities, and the model is smarter, able to read meme images. It can also handle tasks such as converting latex formulas and converting graphs to code.
In the Janus Pro series of models, the team has partially modified the training process of the model, which has directly achieved results that beat DALL-E 3 and Stable Diffusion in the GenEval and DPG-Bench benchmark tests.
Along with the model itself, DeepSeek has also released the new multimodal AI framework Janus Flow, which aims to unify image understanding and generation tasks.
The Janus Pro model can provide more stable output using short prompts, with better visual quality, richer details, and the ability to generate simple text.
The model can generate images and describe pictures, identify landmark attractions (such as Hangzhou’s West Lake), recognize text in images, and describe knowledge in pictures (such as “Tom and Jerry” cakes).
One x.com, Many people have already started experimenting with the new model.

The image recognition test is shown on the left in the figure above, while the image generation test is shown on the right.

As can be seen, Janus Pro also does a good job of reading images with high precision. It can recognize mixed typesetting of mathematical expressions and text. In the future, it may be of greater significance to use it with a reasoning model.
The parameters of 1B and 7B may unlock new application scenarios
In multimodal understanding tasks, the new model Janus-Pro uses SigLIP-L as the visual encoder and supports image inputs of 384 x 384 pixels. In image generation tasks, Janus-Pro uses a tokenizer from a specific source with a downsampling rate of 16.
This is still a relatively small image size. X On the user analysis, the Janus Pro model is more of a directional verification. If the verification is reliable, a model that can be put into production will be released.
However, it is worth noting that the new model released by Janus this time is not only architecturally innovative for multimodal models, but also a new exploration in terms of the number of parameters.
The model compared by DeepSeek Janus Pro this time, DALL-E 3, previously announced that it had 12 billion parameters, while the large-size model of Janus Pro only has 7 billion parameters. With such a compact size, it is already very good that Janus Pro can achieve such results.
In particular, the 1B model of Janus Pro only uses 1.5 billion parameters. Users have already added support for the model to transformers.js on the external network. This means that the model can now run 100% in browsers on WebGPU!
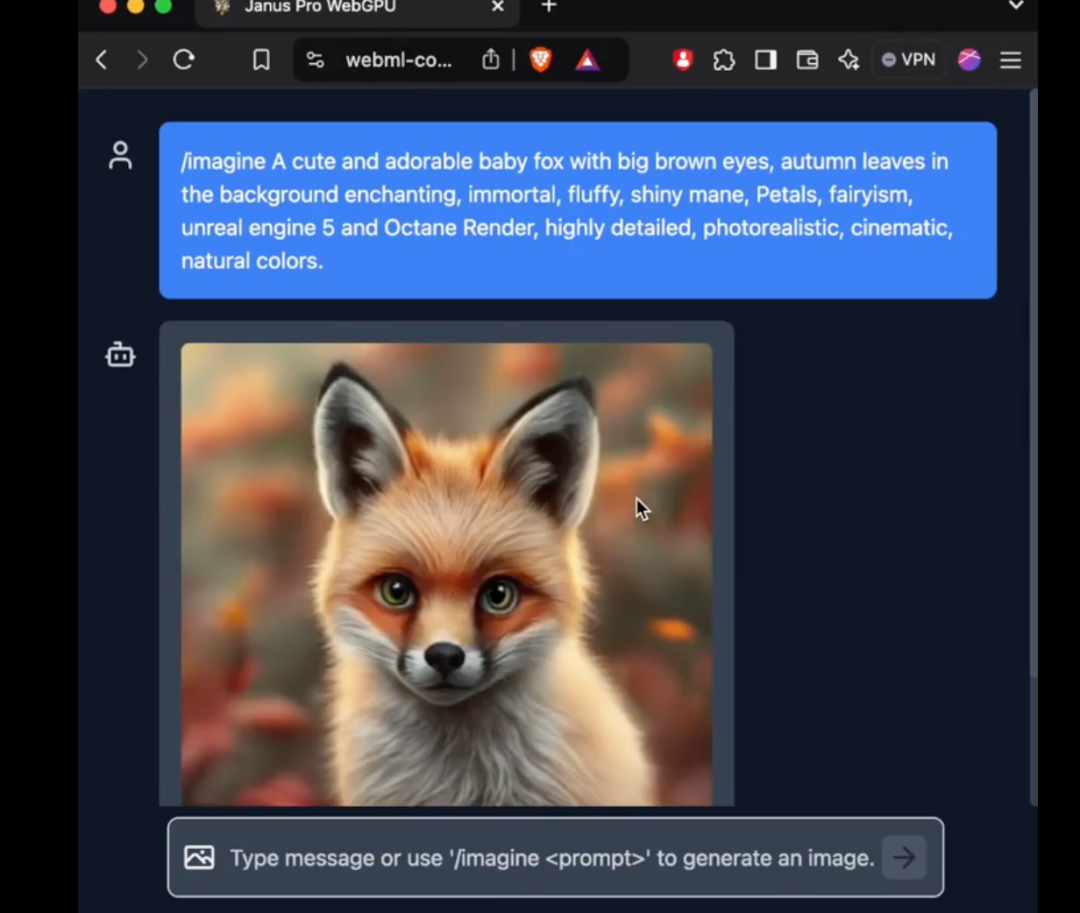
Although as of press time, the author has not yet been able to successfully use the new model of Janus Pro on the web version, the fact that the number of parameters is small enough to run directly on the web side is still an amazing improvement.
This means that the cost of image generation/image understanding is continuing to decline. We have the opportunity to see the use of AI in more places where raw images and image understanding could not be used before, changing our lives.
A major hotspot in 2024 lies in how AI hardware with added multimodal understanding can intervene in our lives. Multimodal understanding models with increasingly lower parameters, or models that can be expected to run on the edge, may enable AI hardware to further explode.
DeepSeek has stirred up the new year. Can everything be re-done with Chinese AI?
The world of AI is changing by the day.
Around the Spring Festival last year, what stirred up the world was OpenAI’s Sora model. However, over the course of the year, Chinese companies have completely caught up in terms of video generation, making the release of Sora at the end of the year seem a bit bleak.
This year, what has stirred up the world has become China’s DeepSeek.
DeepSeek is not a traditional technology company, but it has made extremely innovative models at a cost far lower than that of major American model companies’ GPU cards, which has directly shocked its American counterparts. Americans have exclaimed: “The training of the R1 model only cost 5.6 million US dollars, which is even equivalent to the salary of any executive in the Meta GenAI team. What is this mysterious Eastern power?”
A parody account imitating DeepSeek founder Liang Wenfeng posted an interesting picture directly on X:

The picture used the trending meme of the world-famous Turkish shooter in 2024.
In the 10-meter air pistol final of the shooting events at the Paris Olympics, 51-year-old Turkish shooter Mithat Dikec, wearing only a pair of ordinary myopic glasses and a pair of sleep earplugs, calmly pocketed the silver medal with a single hand in his pocket. All the other shooters present needed two professional lenses for focusing and light blocking and a pair of noise-cancelling earplugs to start the competition.
Since DeepSeek “cracked” OpenAI’s reasoning model, major US technology companies have come under intense pressure. Today, Sam Altman finally responded with an official statement.

Will 2025 be the year that Chinese AI impacts American perceptions?
DeepSeek still has some secrets up its sleeve – this is destined to be an extraordinary Spring Festival.


