
Ⅰ. Vad är kunskapsdestillation?
Kunskapsdestillation är en modellkomprimeringsteknik som används för att överföra kunskap från en stor, komplex modell (lärarmodellen) till en liten modell (studentmodellen).
Grundprincipen är att lärarmodellen undervisar studentmodellen genom att förutsäga resultat (t.ex. sannolikhetsfördelningar eller slutledningsprocesser), och studentmodellen förbättrar sin prestanda genom att lära sig av dessa förutsägelser.
Denna metod är särskilt lämplig för resursbegränsade enheter som mobiltelefoner eller inbäddade enheter.
II.Centrala begrepp
2.1 Utformning av mall
- Mall: Ett strukturerat format som används för att standardisera modellutdata. Till exempel
- : Markerar början på resonemangsprocessen.
- : Markerar slutet på resonemangsprocessen.
- : Markerar början på det slutliga svaret.
- : Markerar slutet på det slutliga svaret.
- Funktion:
- Tydlighet: Precis som "uppmaningsorden" i en fyll-i-blanketten-fråga talar det om för modellen att "tankeprocessen går hit och svaret går dit".
- Enhetlighet: Säkerställer att alla utdata följer samma struktur, vilket underlättar efterföljande bearbetning och analys.
- Läsbarhet: Människor kan enkelt skilja mellan resonemangsprocessen och svaret, vilket förbättrar användarupplevelsen.
2.2 Resonemangets bana: "Tankekedjan" för modellens lösning
- Resonemangets bana: De detaljerade steg som genereras av modellen när ett problem ska lösas visar modellens logiska kedja.
- Exempel:
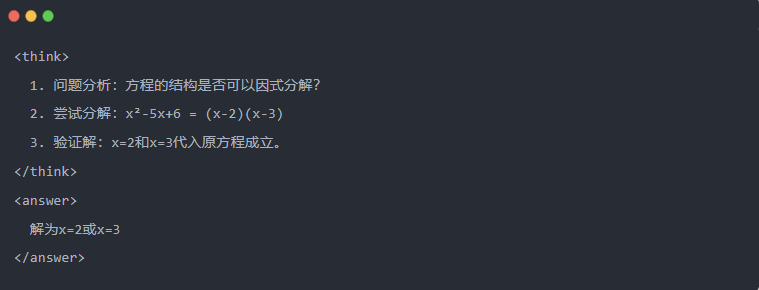
2.3 Avvisande provtagning: Filtrering av bra data från "trial and error
- Provtagning av avslag: Generera flera kandidaters svar och behåll de bra, ungefär som när man skriver ett utkast och sedan kopierar det rätta svaret på ett prov.
Generering av destillerade data (Ⅲ)
Det första steget i kunskapsdestillationen är att generera högkvalitativa "undervisningsdata" som små modeller kan lära sig av.
Datakällor:
- 80% från resonemangsdata som genererats av DeepSeek-R1
- 20% från DeepSeek-V3 allmän uppgiftsdata.
Process för generering av destillationsdata:
- Regel för filtrering: kontrollerar automatiskt att svaret är korrekt (t.ex. om det matematiska svaret överensstämmer med formeln).
- Kontroll av läsbarhet: eliminerar blandade språk (t.ex. kinesiska och engelska blandat) eller långa stycken.
- Mallstyrd generering: kräver att DeepSeek-R1 matar ut inferensbanor i enlighet med mallen.
- Filtrering av avvisningsprovtagning:
- Integration av data: 800.000 högkvalitativa prover genererades slutligen, inklusive cirka 600.000 inferensdata och cirka 200.000 allmänna data.
Ⅳ.Destillationsprocess
Lärar- och elevroller:
- DeepSeek-R1 som lärarmodell;
- Qwen-serien modellerar som studentmodell.
Utbildningssteg:
Först, datainmatning: du måste mata in frågedelen av de 800.000 proven i Qwen-modellen och be den generera en komplett slutledningsbana (tankeprocess + svar) enligt mallen. Detta är ett mycket viktigt steg
Därefter förlustberäkning: jämför utdata som genereras av studentmodellen med lärarmodellens inferensbana och anpassa textsekvensen genom övervakad finjustering (SFT). Om du inte är säker på vad SFT är hoppas jag att du kommer att söka efter det här nyckelordet för att lära dig mer
Slutför parameteruppdateringar för studentens större modell: Optimera parametrarna för Qwen-modellen genom backpropagation för att approximera utdata från lärarmodellen.
Genom att upprepa denna utbildningsprocess flera gånger säkerställs att kunskapen överförs i tillräcklig omfattning. Därmed uppnås det ursprungliga utbildningsmålet. Vi kommer att ge dig ett exempel för att visa detta, och vi hoppas att du kommer att förstå
Ⅴ. Exempel på demonstration
Artikeln visar destillationseffekten genom en specifik ekvationslösningsuppgift (solve equation):
- Standardutdata för lärarmodellen:
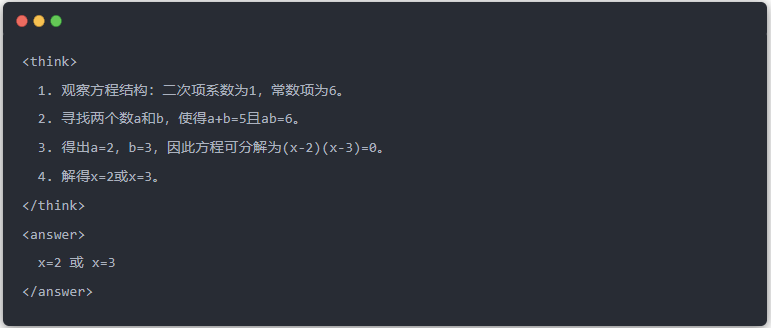
- Qwen-7B utgång före destillation:
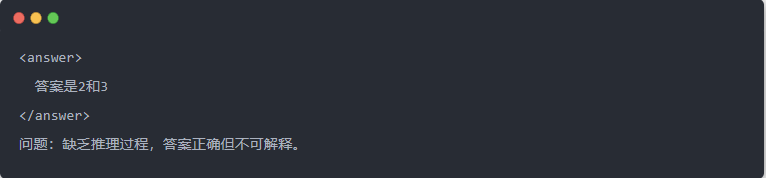
- Qwen-7B utgång efter destillation:
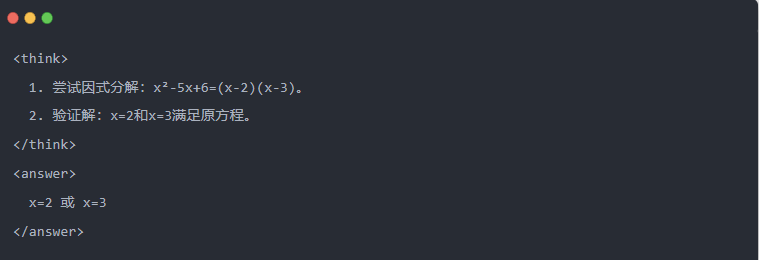
- Optimerad lösning: En strukturerad slutledningsprocess genereras och svaret är detsamma som lärarmodellen.
Ⅵ. Sammanfattning
Genom kunskapsdestillation överförs slutledningsförmågan hos DeepSeek-R1 effektivt till Qwen-serien med små modeller. Denna process fokuserar på mallar för utdata och urval av avslag. Genom strukturerad datagenerering och förfinad träning kan små modeller även utföra komplexa inferensuppgifter i resursbegränsade scenarier. Denna teknik utgör en viktig referens för lättviktig driftsättning av AI-modeller.



