

DelaGPT-4o-bild är en storskalig, högkvalitativ bildgenereringsdatauppsättning där alla bilder genereras med hjälp av GPT-4os bildgenereringsfunktioner.
Denna dataset syftar till att kombinera fördelarna med multimodala modeller med öppen källkod med GPT-4os styrkor inom skapande av visuellt innehåll.
Den innehåller 45 000 text-till-bild- och 46 000 bild-till-text-exempel, vilket gör den till en praktisk resurs för att förbättra multimodala modeller vid bildgenerering och redigering.

Janus-4o är en multimodal LLM som kan generera text-till-bild och text+bild-till-bild. Den är baserad på Janus-Pro och finjusterad med hjälp av datasetet ShareGPT-4o-Image. Jämfört med Janus-Pro introducerar Janus-4o text+bild-till-bild-genereringsfunktioner och uppnår betydande förbättringar i text-till-bild-generering.
Översikt över datamängden
Datasetet ShareGPT-4o-Image innehåller 91 000 exempel på GPT-4o-bilder, kategoriserade enligt följande:
- Text-till-bild: 45 717
- Text-plus-bild-till-bild: 46 539
Relaterade länkar
Koda: github klicka här
Modell: hämta ShareGPT-4o-Image-modellen
Papper: klicka här
Introduktion till dokumentet
Nya framsteg inom multimodala genereringsmodeller har öppnat upp för realistisk, instruktionsanpassad bildgenerering. Ledande system som GPT-4o-Image är dock fortfarande proprietära och oåtkomliga.
För att göra dessa funktioner tillgängliga för allmänheten introducerar artikeln ShareGPT-4o-Image, den första datamängden som innehåller 45 000 text-till-bild- och 46 000 text-plus-bild-till-bild-exempel, alla syntetiserade med hjälp av GPT-4os bildgenereringsfunktioner för att förfina dess avancerade bildgenereringsförmåga. Med hjälp av denna datamängd utvecklade artikeln Janus-4o, en multimodal stor språkmodell som kan generera text-till-bild och text-plus-bild-till-bild.
Janus-4o förbättrar inte bara text-till-bild-genereringsfunktionerna avsevärt jämfört med föregångaren Janus-Pro, utan introducerar även text-plus-bild-till-bild-genereringsfunktioner. Det är värt att notera att den uppnår imponerande prestanda när det gäller att generera bilder från text och bilder från grunden med endast 91 000 syntetiska samplingar och tränad i 6 timmar på en 8×A800 GPU-maskin.
Vi hoppas att lanseringen av ShareGPT-4o-Image och Janus-4o kommer att främja öppen forskning inom fotorealistisk, instruktionsanpassad bildgenerering.
Metodöversikt
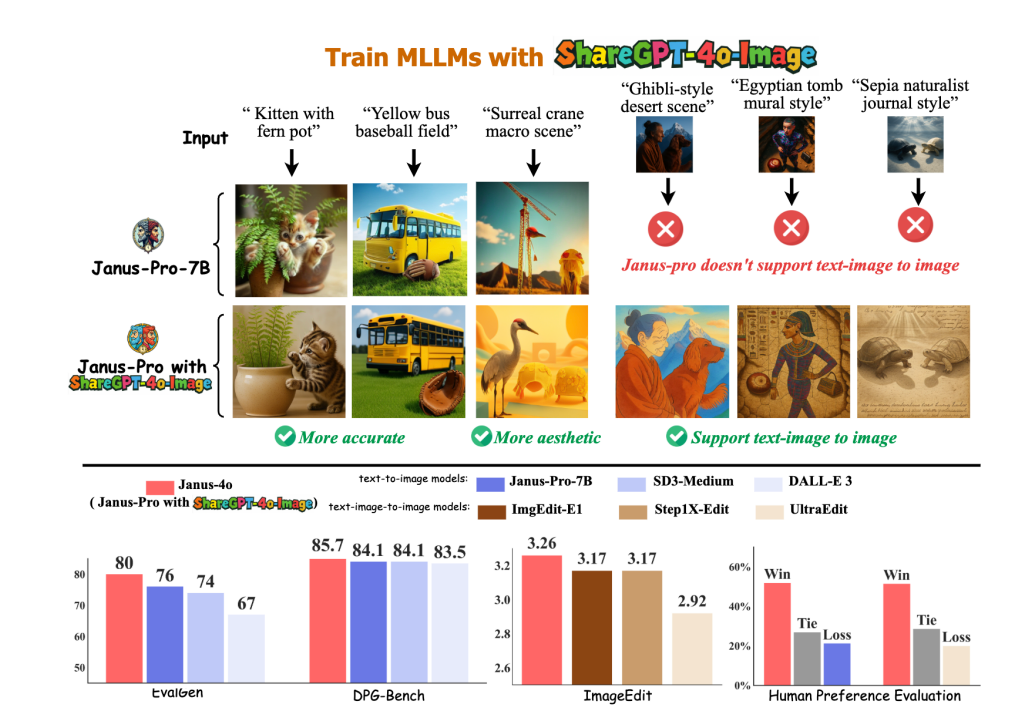
ShareGPT-4o-Image förbättrar prestandan för bildgenerering. Genom att finjustera Janus-Pro med ShareGPT-4o-Image genererade vi Janus-4o, vilket visar avsevärt förbättrad bildgenereringsprestanda. Janus-4o stöder även text-till-bild- och bild-till-bild-generering, vilket överträffar andra riktmärken med endast 91 000 träningsprover.
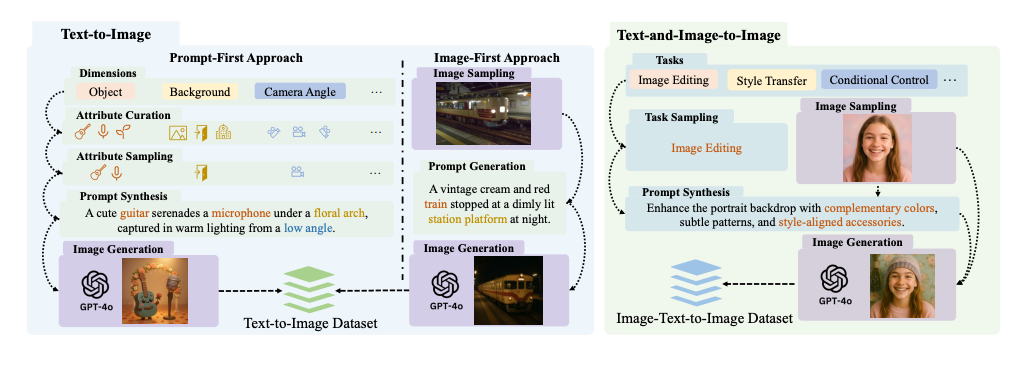
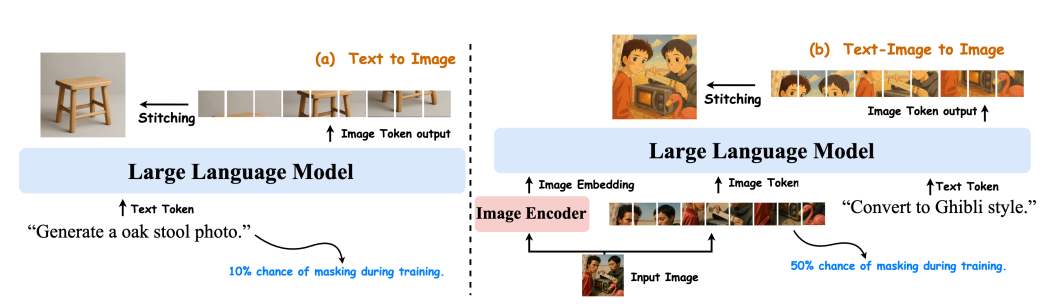
Översikt över Janus-4o-modellen. Modellen är baserad på Janus-Pro och konstruerad genom finjustering på ShareGPT-4o-Image. Den innehåller förbättringar för att stödja text-till-bild- och bild-till-bild-generering. Både text-till-bild- och text-till-bild-uppgifter tränas gemensamt.
Experimentella resultat

Slutsatser
ShareGPT-4o-Image är den första storskaliga datamängden som kan fånga GPT-4os avancerade bildgenereringsfunktioner inom text-till-bild- och text-till-bild-generering. Baserat på denna datamängd utvecklade artikeln Janus-4o, en maskininlärningsmodell (MLLM) som kan generera högkvalitativa bilder från ren text eller bild-text-kombinationer.
Janus-4o uppnår betydande förbättringar i text-till-bild-generering och mycket konkurrenskraftiga resultat i text-till-bild-uppgifter, vilket demonstrerar den höga kvaliteten och praktiska användbarheten hos ShareGPT-4o-Image.
Tack vare effektiviteten hos självregressiv bildgenerering baserad på MLLM kan Janus-4o tränas på bara 6 timmar på en 8×A800 GPU-maskin och uppnår betydande prestandaförbättringar med extremt låga beräkningskrav.



