DeepSeek har uppdaterat sin hemsida.
Under de tidiga timmarna på nyårsafton meddelade DeepSeek plötsligt på GitHub att Janus-projektutrymmet hade öppnat källan till Janus-Pro-modellen och den tekniska rapporten.
Låt oss först lyfta fram några viktiga punkter:
- Den Janus-Pro-modell som släpps denna gång är en multimodal modell som kan samtidigt utföra multimodala förståelse- och bildgenereringsuppgifter. Den har totalt två parameterversioner, Janus-Pro-1B och Janus-Pro-7B.
- Kärninnovationen i Janus-Pro är att frikoppla multimodal förståelse och generering, två olika uppgifter. Detta gör att dessa två uppgifter kan utföras på ett effektivt sätt i samma modell.
- Janus-Pro är förenlig med Janus modellarkitektur som DeepSeek släppte i oktober förra året, men vid den tidpunkten hade Janus inte så stor volym. Dr. Charles, en algoritmexpert inom synområdet, berättade för oss att den tidigare Janus var "genomsnittlig" och "inte lika bra som DeepSeeks språkmodell".

Den är avsedd att lösa branschens svåra problem: att balansera multimodal förståelse och bildgenerering
Enligt den officiella introduktionen av DeepSeek, Janus-Pro kan inte bara förstå bilder, extrahera och förstå texten i bilderna, utan också generera bilder på samma gång.
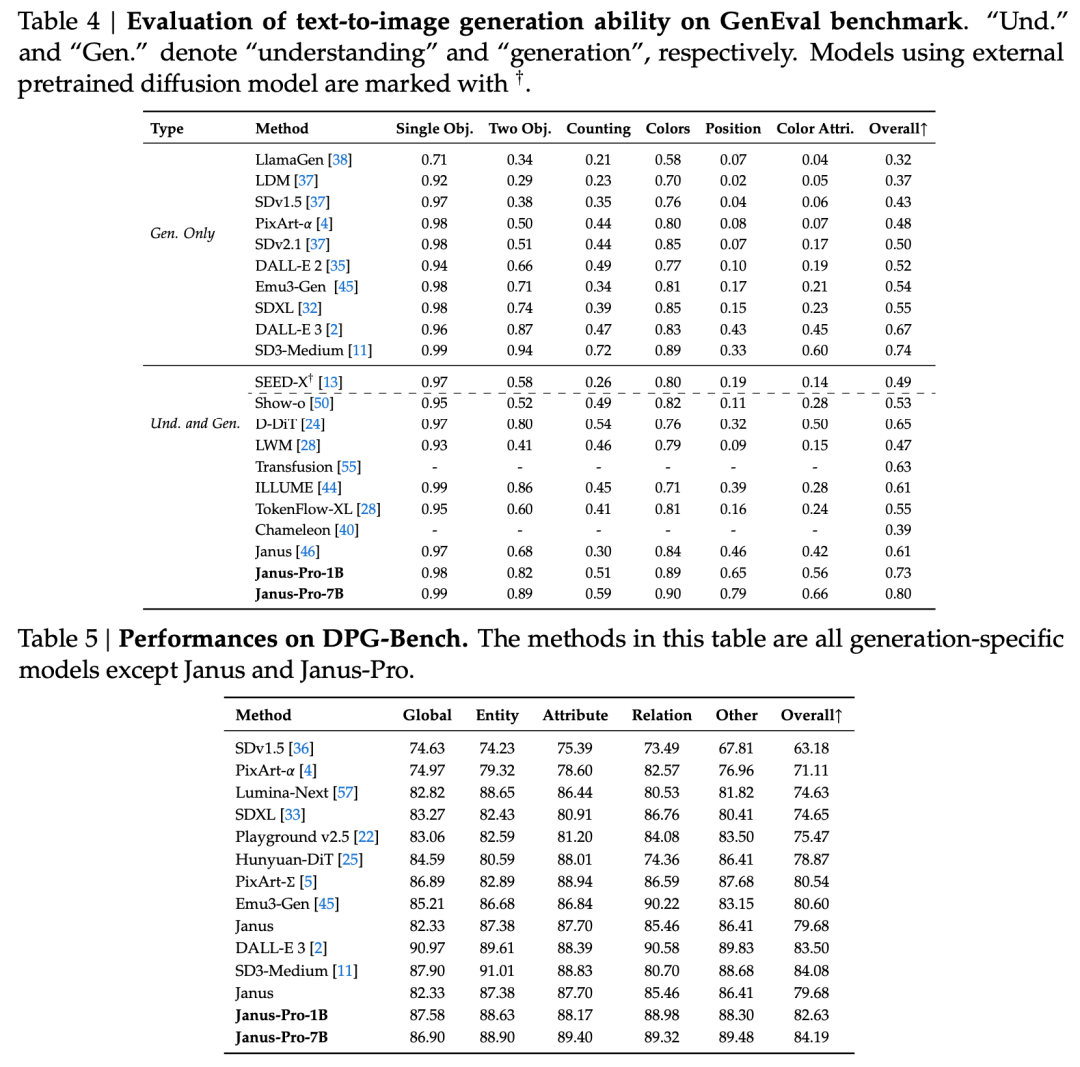
I den tekniska rapporten nämns att jämfört med andra modeller av samma typ och storleksordning, fick Janus-Pro-7B:s resultat på testuppsättningarna GenEval och DPG-Bench är högre än för andra modeller som SD3-Medium och DALL-E 3.
Tjänstemannen ger också exempel 👇:
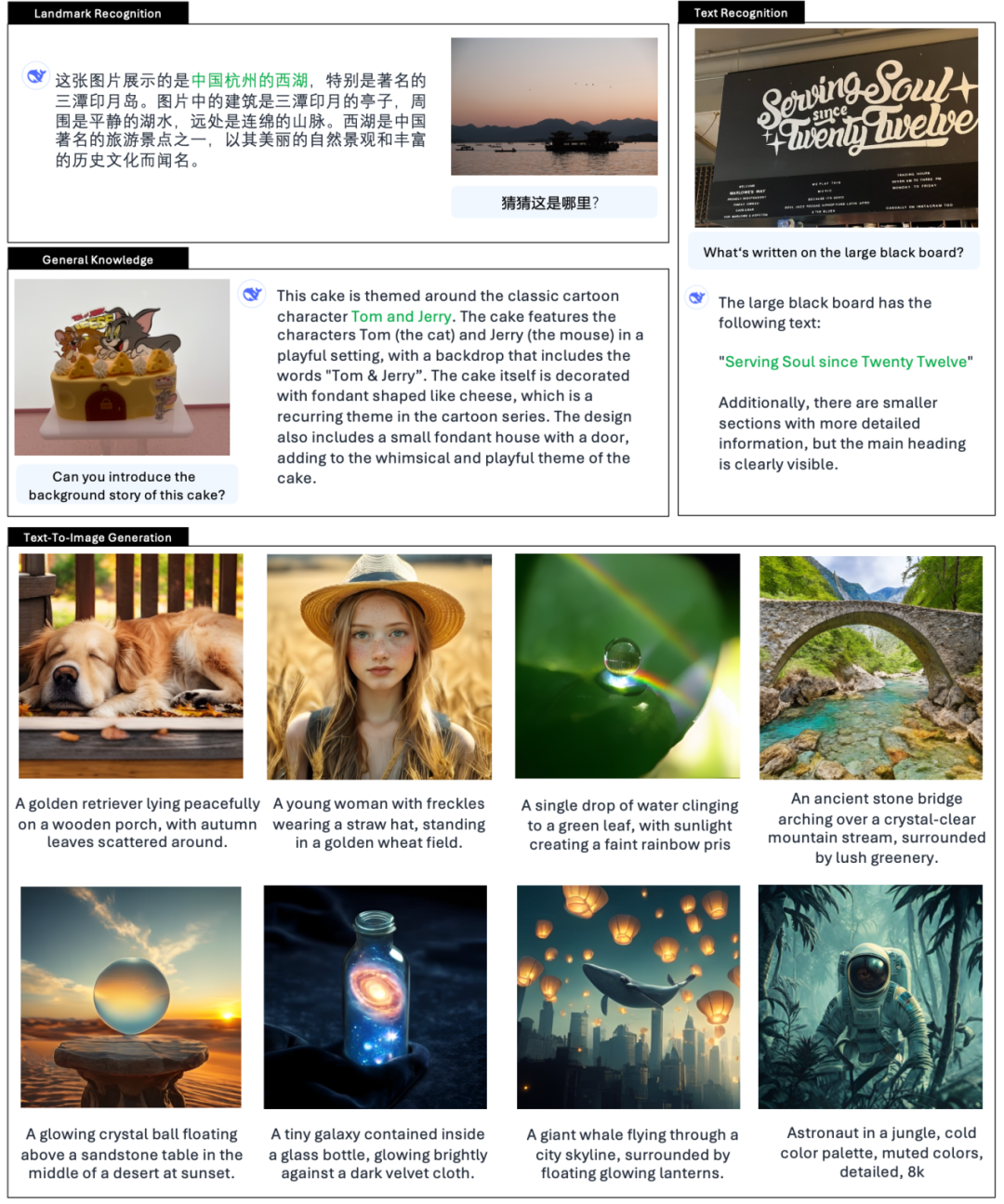
Det finns också många nätanvändare på X som testar de nya funktionerna.

Men det förekommer också enstaka krascher.
Genom att konsultera de tekniska dokumenten om DeepSeekkonstaterade vi att Janus Pro är en optimering baserad på Janus, som släpptes för tre månader sedan.
Den viktigaste innovationen i denna serie modeller är att frikoppla uppgifter för visuell förståelse från uppgifter för visuell generering, så att effekterna av de två uppgifterna kan balanseras.
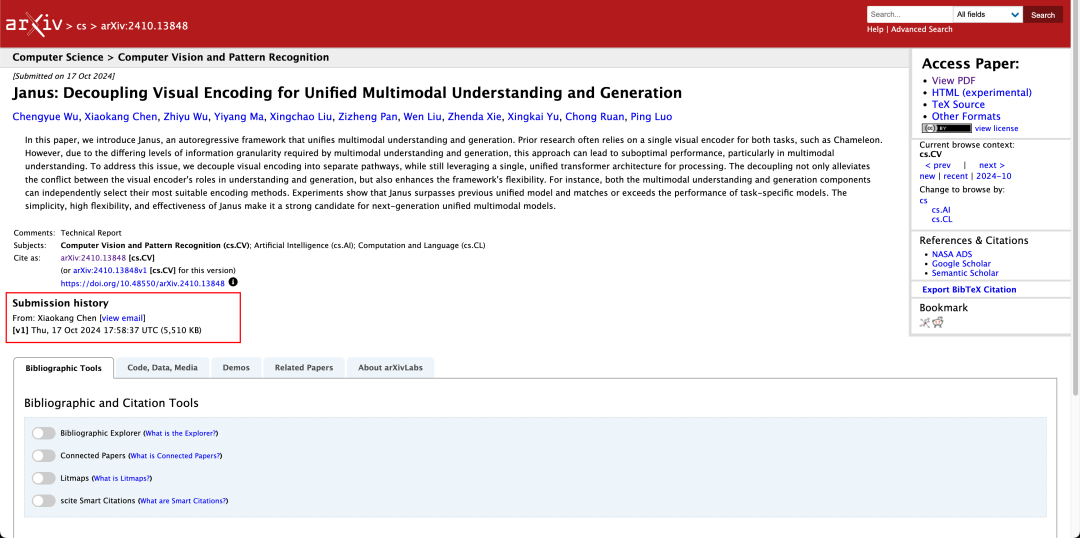
Det är inte ovanligt att en modell kan utföra multimodal förståelse och generering på samma gång. D-DiT och TokenFlow-XL i denna testuppsättning har båda denna förmåga.
Det som är utmärkande för Janus är dock att genom att frikoppla bearbetningen, en modell som kan utföra multimodal förståelse och generering balanserar effektiviteten hos de två uppgifterna.
Att balansera effektiviteten i de två uppgifterna är ett svårt problem i branschen. Tidigare var tanken att använda samma kodare för att implementera multimodal förståelse och generering i så stor utsträckning som möjligt.
Fördelarna med detta tillvägagångssätt är en enkel arkitektur, ingen överflödig distribution och en anpassning till textmodeller (som också använder samma metoder för att uppnå textgenerering och textförståelse). Ett annat argument är att denna sammansmältning av flera förmågor kan leda till en viss grad av emergens.
Efter att generering och förståelse har slagits samman kommer de två uppgifterna dock att stå i konflikt med varandra - bildförståelse kräver att modellen abstraherar i höga dimensioner och extraherar bildens kärnsemantik, som är inriktad på det makroskopiska. Bildgenerering, å andra sidan, fokuserar på uttryck och generering av lokala detaljer på pixelnivå.
Branschens vanliga praxis är att prioritera förmågan att generera bilder. Detta resulterar i multimodala modeller som kan generera bilder av högre kvalitet, men resultatet av bildförståelsen är ofta mediokert.
Janus frikopplade arkitektur och Janus-Pro:s optimerade träningsstrategi
Janus frikopplade arkitektur gör att modellen kan balansera uppgifterna att förstå och generera på egen hand.
Enligt resultaten i den officiella tekniska rapporten, oavsett om det gäller multimodal förståelse eller bildgenerering, presterar Janus-Pro-7B bra på flera testuppsättningar.

För multimodal förståelse, Janus-Pro-7B uppnådde förstaplatsen i fyra av de sju utvärderingsdataseten och andraplatsen i de återstående tre, strax bakom den högst rankade modellen.
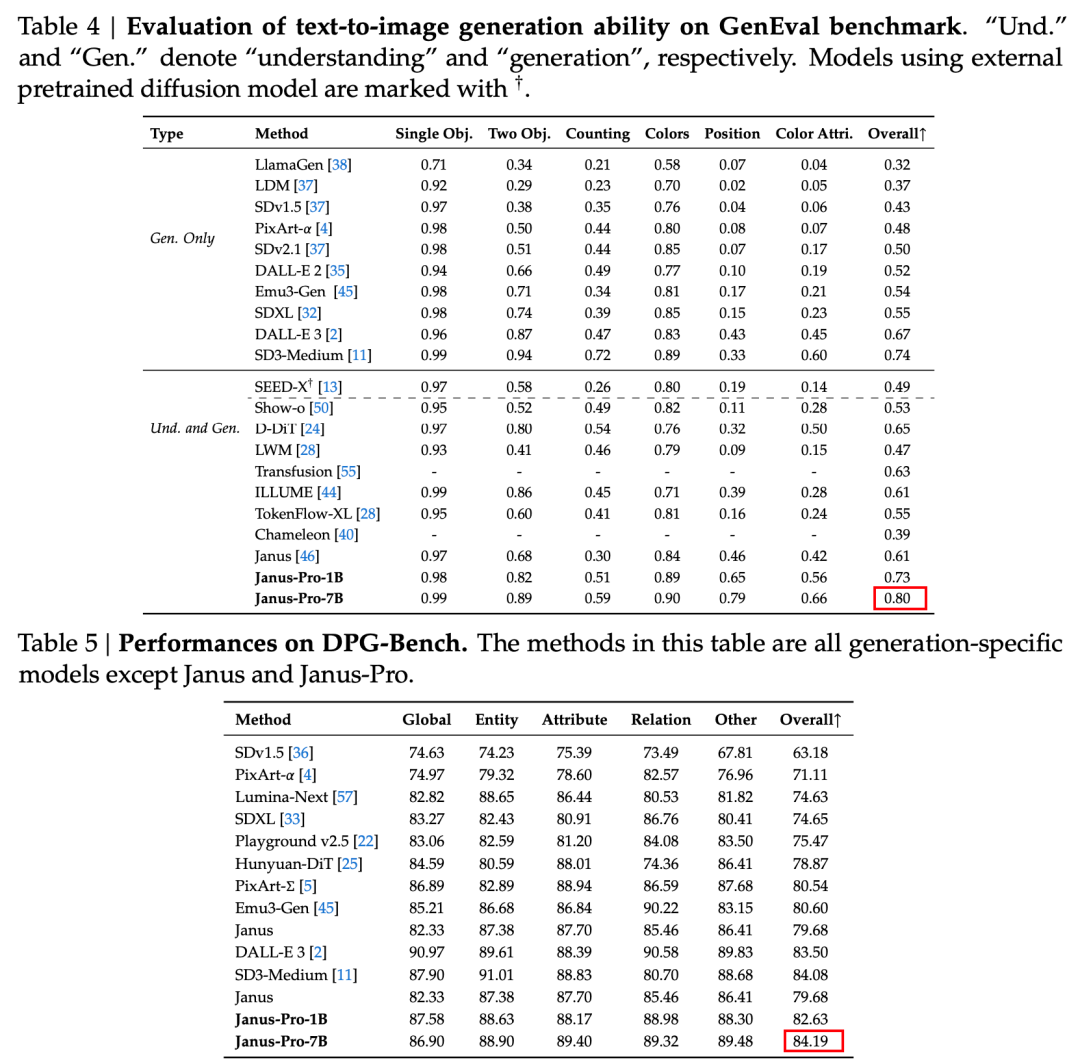
För bildgenerering, Janus-Pro-7B uppnådde första plats i den totala poängen på både GenEval och DPG-Bench utvärderingsdataset.
Denna multi-tasking-effekt beror främst på att Janus-serien använder två visuella kodare för olika uppgifter:
- Förståelse för kodare: används för att extrahera semantiska egenskaper i bilder för bildförståelseuppgifter (t.ex. frågor och svar om bilder, visuell klassificering etc.)
- Generativ kodare: konverterar bilder till en diskret representation (t.ex. med hjälp av en VQ-kodare) för text-till-bild-genereringsuppgifter.
Med denna arkitektur, kan modellen självständigt optimera prestandan för varje kodare, så att multimodala förståelse- och genereringsuppgifter var och en kan uppnå bästa möjliga prestanda.
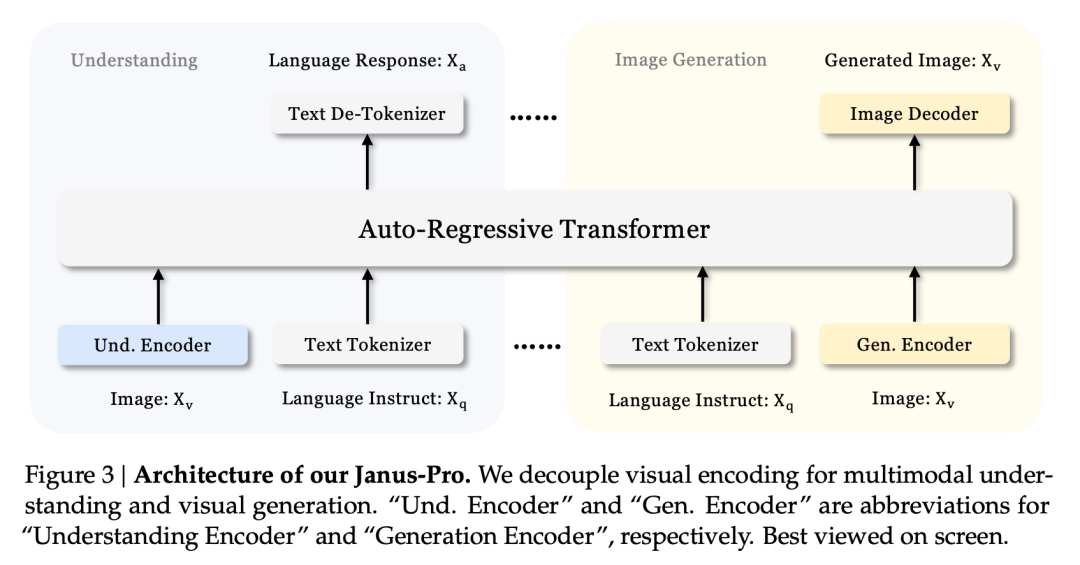
Denna frikopplade arkitektur är gemensam för Janus-Pro och Janus. Så, vilka iterationer har Janus-Pro haft under de senaste månaderna?
Som framgår av resultaten från utvärderingsuppsättningen har den aktuella utgåvan av Janus-Pro-1B en förbättring på cirka 10% till 20% i poängen för olika utvärderingsuppsättningar jämfört med den tidigare Janus. Janus-Pro-7B har den högsta förbättringen på cirka 45% jämfört med Janus efter att antalet parametrar har utökats.

När det gäller utbildningsdetaljer anges i den tekniska rapporten att den nuvarande versionen av Janus-Pro, jämfört med den tidigare Janus-modellen, behåller den centrala frikopplade arkitekturdesignen och dessutom itererar på parameterstorlek, träningsstrategi och träningsdata.
Låt oss först titta på parametrarna.
Den första versionen av Janus hade endast 1,3B parametrar, och den nuvarande versionen av Pro innehåller modeller med 1B och 7B parametrar.
Dessa två storlekar återspeglar skalbarheten i Janus-arkitekturen. 1B-modellen, som är den lättaste, har redan använts av externa användare för att köras i webbläsaren med hjälp av WebGPU.
Det finns också den utbildningsstrategi.
I linje med Janus uppdelning i utbildningsfaser har Janus Pro totalt tre utbildningsfaser, och tidningen delar direkt in dem i steg I, steg II och steg III.
Samtidigt som de grundläggande utbildningsidéerna och utbildningsmålen för varje fas har behållits, har Janus-Pro gjort förbättringar av utbildningens längd och utbildningsdata i de tre faserna. Följande är de specifika förbättringarna i de tre faserna:
Steg I - Längre utbildningstid
Jämfört med Janus har Janus-Pro förlängt träningstiden i steg I, särskilt när det gäller träning av adaptrar och bildhuvuden i den visuella delen. Detta innebär att inlärningen av visuella egenskaper har fått mer träningstid, och förhoppningen är att modellen fullt ut ska kunna förstå bilders detaljerade egenskaper (t.ex. pixel-till-semantisk mappning).
Denna utökade utbildning bidrar till att säkerställa att utbildningen av den visuella delen inte störs av andra moduler.
Steg II - ImageNet-data tas bort och multimodala data läggs till
I steg II refererade Janus tidigare till PixArt och tränade i två delar. Den första delen tränades med hjälp av ImageNet-datasetet för bildklassificeringsuppgiften och den andra delen tränades med vanliga text-till-bild-data. Ungefär två tredjedelar av tiden i steg II ägnades åt träning i den första delen.
Janus-Pro tar bort ImageNet-träningen i steg II. Denna design gör att modellen kan fokusera på text-till-bild-data under steg II-utbildningen. Enligt experimentella resultat kan detta avsevärt förbättra utnyttjandet av text-till-bild-data.
Utöver justeringen av utbildningsmetodens utformning är den uppsättning utbildningsdata som används i steg II inte längre begränsad till en enda bildklassificeringsuppgift, utan innehåller också fler andra typer av multimodala data, såsom bildbeskrivning och dialog, för gemensam utbildning.
Steg III - Optimering av dataförhållandet
I steg III-utbildningen justerar Janus-Pro förhållandet mellan olika typer av utbildningsdata.
Tidigare var förhållandet mellan multimodal förståelsedata, vanlig textdata och text-till-bild-data i de träningsdata som Janus använde i steg III 7:3:10. Janus-Pro minskar förhållandet mellan de två senare typerna av data och justerar förhållandet mellan de tre typerna av data till 5:1:4, det vill säga lägger större vikt vid den multimodala förståelsen.
Låt oss titta på träningsdata.
Jämfört med Janus ökar Janus-Pro den här gången avsevärt mängden högkvalitativa syntetiska data.
Den utökar mängden och variationen av träningsdata för multimodal förståelse och bildgenerering.
Utökning av multimodala förståelsedata:
Janus-Pro hänvisar till DeepSeek-VL2-datasetet under träningen och lägger till cirka 90 miljoner ytterligare datapunkter, inklusive inte bara bildbeskrivningsdataset, utan även dataset med komplexa scener som tabeller, diagram och dokument.
Under det övervakade finjusteringssteget (steg III) fortsätter det att lägga till dataset relaterade till MEME-förståelse och dialog (inklusive kinesisk dialog) för att förbättra erfarenheten.
Utökning av visuell generationsdata:
De ursprungliga verkliga data hade dålig kvalitet och höga brusnivåer, vilket ledde till att modellen producerade instabila resultat och bilder med otillräcklig estetisk kvalitet i text-till-bild-uppgifter.
Janus-Pro lade till cirka 72 miljoner nya syntetiska data med hög estetisk kvalitet i träningsfasen, vilket innebar att förhållandet mellan verkliga data och syntetiska data i förträningsfasen blev 1:1.
Uppmaningarna för de syntetiska data hämtades alla från offentliga resurser. Experiment har visat att modellen konvergerar snabbare när dessa data läggs till, och de genererade bilderna har uppenbara förbättringar när det gäller stabilitet och visuell skönhet.
Fortsättningen på en effektivitetsrevolution?
Sammantaget har DeepSeek med den här versionen tagit effektivitetsrevolutionen till visuella modeller.
Till skillnad från visuella modeller som fokuserar på en enda funktion eller multimodala modeller som gynnar en specifik uppgift, balanserar Janus-Pro effekterna av de två stora uppgifterna bildgenerering och multimodal förståelse i samma modell.
Trots sina små parametrar slog den dessutomOpenAI DALL-E 3 och SD3-Medium i utvärderingen.
Förlängt till marken behöver företaget bara distribuera en modell för att direkt implementera de två funktionerna för bildgenerering och förståelse. Tillsammans med en storlek på endast 7B är svårigheten och kostnaden för utplacering mycket lägre.
I samband med de tidigare lanseringarna av R1 och V3 utmanar DeepSeek de befintliga spelreglerna med "kompakt arkitektonisk innovation, lättviktsmodeller, modeller med öppen källkod och extremt låga utbildningskostnader". Detta är anledningen till paniken bland västerländska teknikjättar och till och med Wall Street.
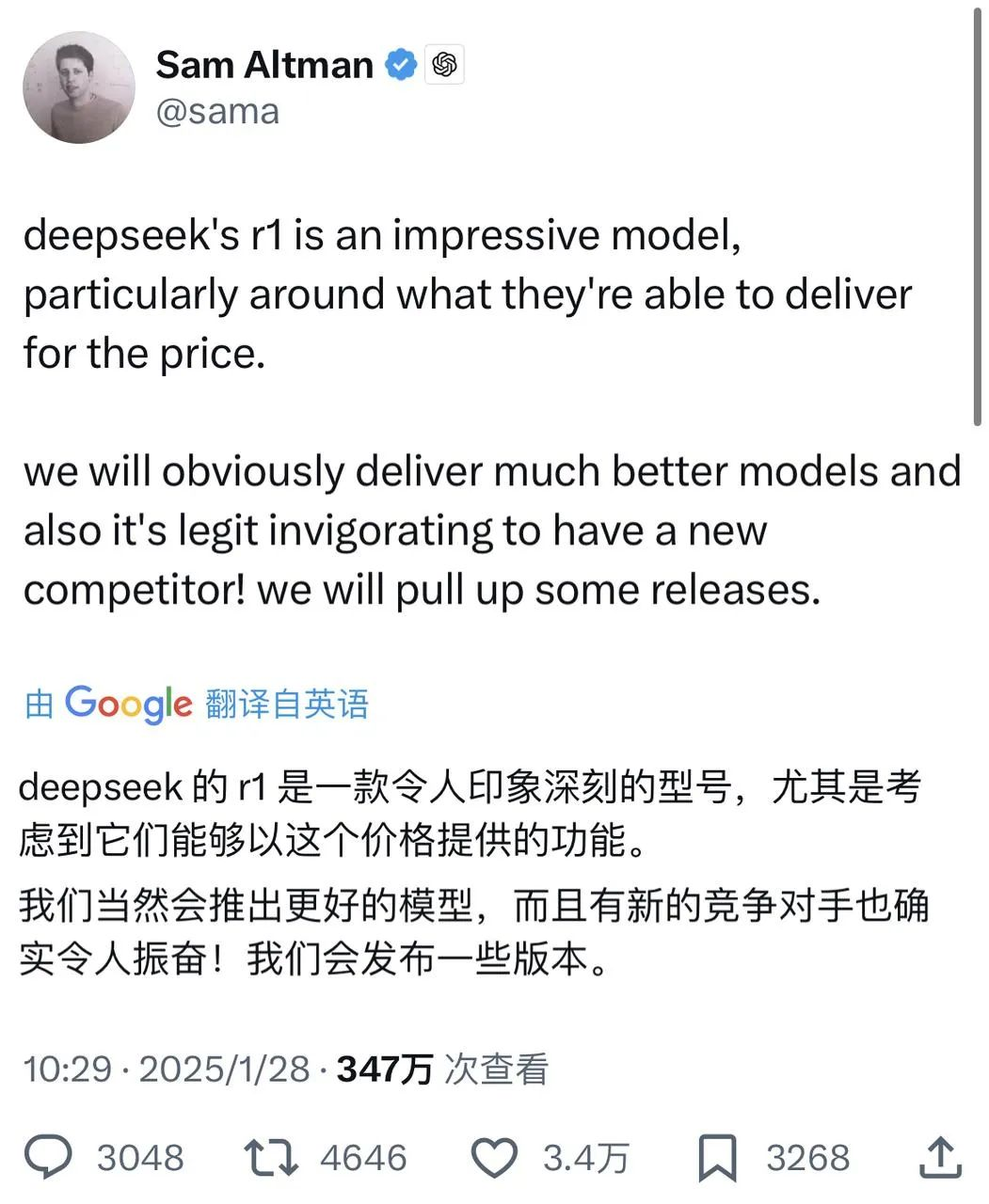
Just nu svarade Sam Altman, som har svepts med av den allmänna opinionen i flera dagar, äntligen positivt på information om DeepSeek på X - samtidigt som han berömde R1 sa han att OpenAI kommer att göra några tillkännagivanden.