
Ⅰ. Bilgi damıtma nedir?
Bilgi damıtma, bilgiyi büyük ve karmaşık bir modelden (öğretmen modeli) küçük bir modele (öğrenci modeli) aktarmak için kullanılan bir model sıkıştırma tekniğidir.
Temel ilke, öğretmen modelinin sonuçları (olasılık dağılımları veya çıkarım süreçleri gibi) tahmin ederek öğrenci modeline öğretmesi ve öğrenci modelinin bu tahminlerden öğrenerek performansını geliştirmesidir.
Bu yöntem özellikle cep telefonları veya gömülü cihazlar gibi kaynakları kısıtlı cihazlar için uygundur.
II.Temel kavramlar
2.1 Şablon tasarımı
- Şablon: Model çıktısını standartlaştırmak için kullanılan yapılandırılmış bir format. Örneğin
- : Muhakeme sürecinin başlangıcını işaret eder.
- : Muhakeme sürecinin sonunu işaretler.
- : Nihai cevabın başlangıcını işaretler.
- : Son cevabın sonunu işaretler.
- Fonksiyon:
- Netlik: Boşluk doldurma sorusundaki "ipucu kelimeleri" gibi, modele "düşünme süreci buraya, cevap da şuraya gider" der.
- Tutarlılık: Tüm çıktıların aynı yapıyı takip etmesini sağlayarak sonraki işlem ve analizleri kolaylaştırır.
- Okunabilirlik: İnsanlar muhakeme süreci ile cevabı kolayca ayırt edebilir ve bu da kullanıcı deneyimini iyileştirir.
2.2 Akıl yürütme yörüngesi: Modelin çözümünün "düşünme zinciri"
- Muhakeme yörüngesi: Bir problemi çözerken model tarafından oluşturulan ayrıntılı adımlar, modelin mantıksal zincirini gösterir.
- Örnek:
2.3 Reddetme örneklemesi: İyi verilerin "deneme yanılma" yöntemiyle filtrelenmesi
- Reddetme örneklemesi: Bir sınavda taslak yazıp ardından doğru cevabı kopyalamaya benzer şekilde birden fazla aday cevabı oluşturun ve iyi olanları saklayın.
Ⅲ.Damıtılmış verilerin oluşturulması
Bilgi damıtmanın ilk adımı, küçük modellerin öğrenmesi için yüksek kaliteli 'öğretim verileri' üretmektir.
Veri kaynakları:
- 80% tarafından üretilen muhakeme verilerinden DeepSeek-R1
- DeepSeek-V3 genel görev verilerinden 20%.
Distilasyon verisi oluşturma süreci:
- Kural filtreleme: cevabın doğruluğunu otomatik olarak kontrol eder (örneğin matematiksel cevabın formüle uygun olup olmadığı).
- Okunabilirlik kontrolü: karışık dilleri (örneğin Çince ve İngilizce karışık) veya uzun paragrafları ortadan kaldırır.
- Şablon güdümlü üretim: DeepSeek-R1'in şablona göre çıkarım yörüngeleri üretmesini gerektirir.
- Reddetme örnekleme filtreleme:
- Veri entegrasyonu: Sonunda yaklaşık 600.000 çıkarım verisi ve yaklaşık 200.000 genel veri dahil olmak üzere 800.000 yüksek kaliteli örnek üretildi.
Ⅳ.Damıtma işlemi
Öğretmen ve öğrenci rolleri:
- Öğretmen modeli olarak DeepSeek-R1;
- Öğrenci modeli olarak Qwen serisi modeller.
Eğitim adımları:
İlk olarak, veri girişi: 800.000 örneğin soru kısmını Qwen modeline girmeniz ve ondan şablona göre eksiksiz bir çıkarım yörüngesi (düşünme süreci + cevap) oluşturmasını istemeniz gerekir. Bu çok önemli bir adımdır
Ardından, kayıp hesaplaması: öğrenci modeli tarafından üretilen çıktıyı öğretmen modelinin çıkarım yörüngesiyle karşılaştırın ve metin dizisini denetimli ince ayar (SFT) yoluyla hizalayın. SFT'nin ne olduğundan emin değilseniz, daha fazla bilgi edinmek için bu anahtar kelimeyi arayacağınızı umuyorum
Öğrencinin daha büyük modeli için parametre güncellemelerini tamamlayın: Öğretmen modelinin çıktısına yaklaşmak için Qwen modelinin parametrelerini geri yayılım yoluyla optimize edin.
Bu eğitim sürecinin birçok kez tekrarlanması bilginin yeterince aktarılmasını sağlar. Bu, asıl eğitim hedefine ulaşılmasını sağlar. Bunu göstermek için size bir örnek vereceğiz ve anlayacağınızı umuyoruz
Ⅴ. Örnek gösterim
Makale, damıtma etkisini belirli bir denklem çözme görevi (denklem çözme) aracılığıyla göstermektedir:
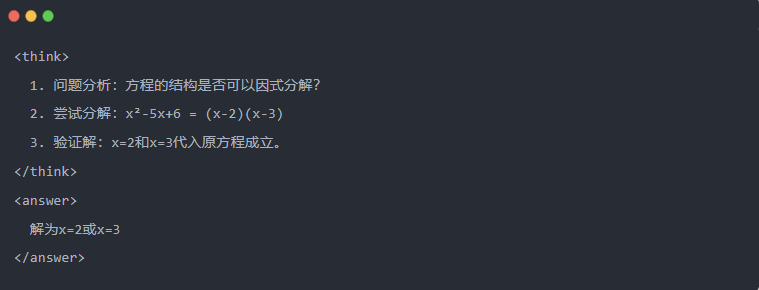
- Öğretmen modelinin standart çıktısı:
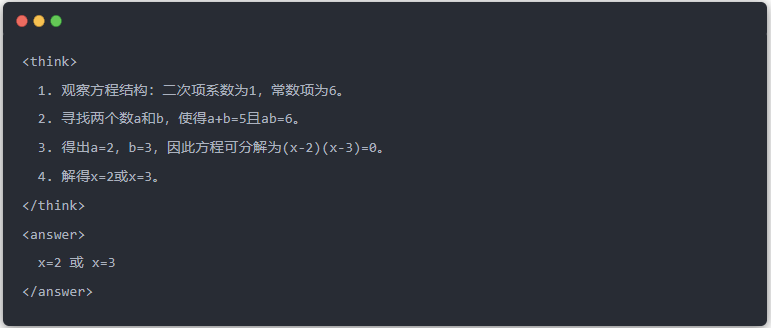
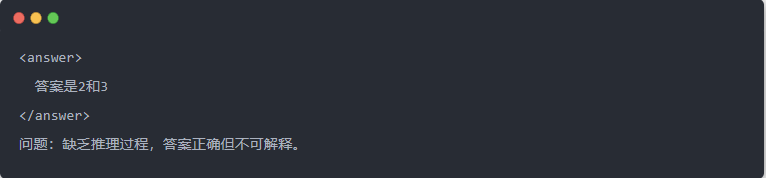
- Damıtmadan önce Qwen-7B çıktısı:
- Damıtmadan sonra Qwen-7B çıktısı:
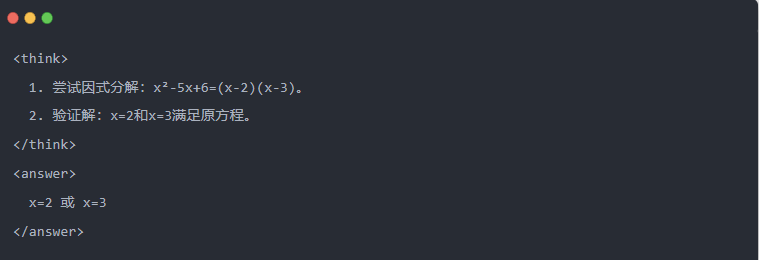
- Optimize edilmiş çözüm: Yapılandırılmış bir çıkarım süreci oluşturulur ve cevap öğretmen modeliyle aynıdır.
Ⅵ. Özet
Bilgi damıtma yoluyla, DeepSeek-R1'in çıkarım yeteneği verimli bir şekilde Qwen serisi küçük modellere taşınır. Bu süreç, şablonlaştırılmış çıktı ve reddetme örneklemesine odaklanır. Yapılandırılmış veri üretimi ve rafine eğitim sayesinde, küçük modeller kaynak kısıtlı senaryolarda karmaşık çıkarım görevlerini de yerine getirebilir. Bu teknoloji, yapay zeka modellerinin hafif bir şekilde konuşlandırılması için önemli bir referans sağlamaktadır.


