
Ⅰ. 什么是知识蒸馏?
知识蒸馏是一种模型压缩技术,用于将知识从复杂的大型模型(教师模型)转移到小型模型(学生模型)。
其核心原理是,教师模型通过预测结果(如概率分布或推理过程)来教授学生模型,而学生模型则通过学习这些预测结果来提高自己的性能。
这种方法尤其适用于资源有限的设备,如移动电话或嵌入式设备。
二. 核心概念
2.1 模板设计
- 模板:用于标准化模型输出的结构化格式。例如
- :标志着推理过程的开始。
- :标志着推理过程的结束。
- :标志着最终答案的开始。
- :标志着最终答案的结束。
- 功能
- 清晰:就像填空题中的 "提示语 "一样,它告诉模型 "思考过程在这里,答案在那里"。
- 一致性:确保所有输出都遵循相同的结构,便于后续处理和分析。
- 可读性:人类可以轻松区分推理过程和答案,从而改善用户体验。
2.2 推理轨迹:模型解决方案的 "思维链"
- 推理轨迹:模型在解决问题时产生的详细步骤,显示了模型的逻辑链。
- 例如
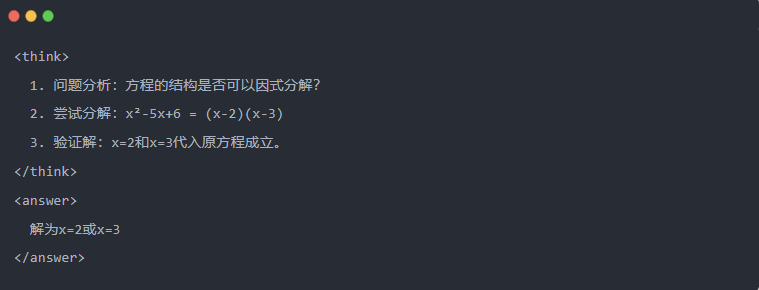
2.3 拒绝采样:从 "试错 "中筛选出好数据
- 拒绝抽样:生成多个候选答案,保留好的答案,类似于考试时先写草稿,然后抄写正确答案。
Ⅲ.生成提炼数据
知识提炼的第一步是生成高质量的 "教学数据",供小型模型学习。
数据来源:
- 80% 的推理数据。 DeepSeek-R1
- 20% 来自 DeepSeek-V3 一般任务数据。
蒸馏数据生成过程:
- 规则过滤自动检查:自动检查答案的正确性(例如,数学答案是否符合公式)。
- 可读性检查消除混合语言(如中英文混合)或冗长段落。
- 模板引导生成推理轨迹:要求 DeepSeek-R1 根据模板输出推理轨迹。
- 剔除采样滤波:
- 数据整合最终生成 800 000 个高质量样本,包括约 600 000 个推理数据和约 200 000 个一般数据。
Ⅳ.蒸馏过程
教师和学生的角色:
- DeepSeek-R1 作为教师模型;
- Qwen 系列模型作为学生模型。
培训步骤:
首先是数据输入:您需要将 800,000 个样本中的问题部分输入 Qwen 模型,并要求它根据模板生成完整的推理轨迹(思考过程 + 答案)。这是非常重要的一步
接下来是损失计算:将学生模型生成的输出与教师模型的推理轨迹进行比较,并通过监督微调(SFT)对齐文本序列。如果您不清楚什么是 SFT,我希望您能搜索这个关键词了解更多信息
完成学生较大模型的参数更新:通过反向传播优化 Qwen 模型的参数,以逼近教师模型的输出。
多次重复这一培训过程可确保知识得到充分传授。这就达到了最初的培训目的。我们将举例说明,希望大家能够理解
Ⅴ.实例演示
文章通过一个具体的解方程任务(解方程)展示了蒸馏效应:
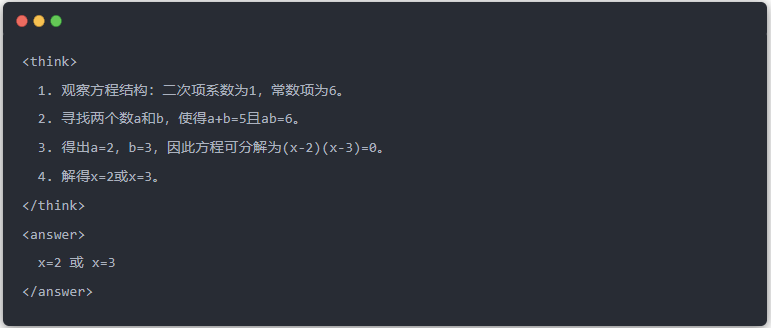
- 教师模型的标准输出:
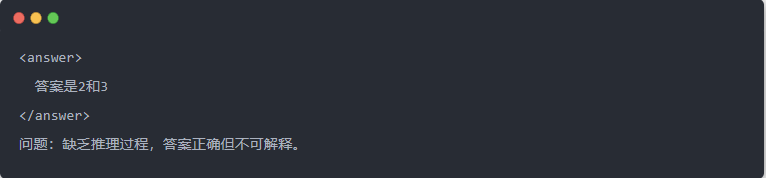
- 蒸馏前的 Qwen-7B 输出:
- 蒸馏后的 Qwen-7B 输出:
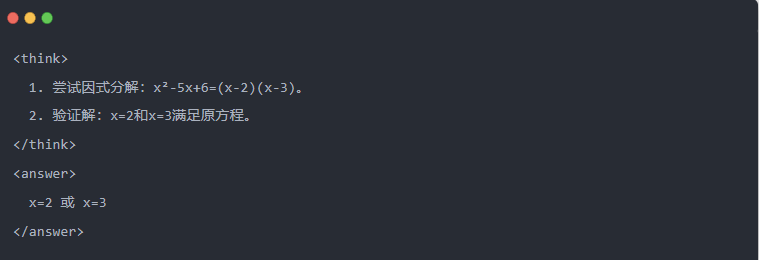
- 优化解决方案:生成结构化推理过程,答案与教师模型相同。
Ⅵ.总结
通过知识提炼,DeepSeek-R1 的推理能力被有效地移植到 Qwen 系列小型模型中。这一过程的重点是模板化输出和拒绝采样。通过结构化数据生成和精细化训练,小型模型也能在资源有限的情况下执行复杂的推理任务。这项技术为人工智能模型的轻量级部署提供了重要参考。




