
Ⅰ. Co je destilace znalostí?
Destilace znalostí je technika komprese modelu, která se používá k přenosu znalostí z velkého, komplexního modelu (model učitele) do malého modelu (model studenta).
Základní princip spočívá v tom, že učitelský model učí žákovský model předpovídáním výsledků (například rozdělení pravděpodobnosti nebo odvozovacích procesů) a žákovský model zlepšuje svůj výkon učením se z těchto předpovědí.
Tato metoda je vhodná zejména pro zařízení s omezenými zdroji, jako jsou mobilní telefony nebo vestavěná zařízení.
II.Základní pojmy
2.1 Návrh šablony
- Šablona: Šablona: strukturovaný formát používaný ke standardizaci výstupu modelu. Například
- : Označuje začátek procesu uvažování.
- : Označuje konec procesu uvažování.
- : Označuje začátek konečné odpovědi.
- : Označuje konec závěrečné odpovědi.
- Funkce:
- Jasnost: Stejně jako "podnětná slova" v otázce na vyplnění prázdného políčka říká modelu "proces přemýšlení probíhá zde a odpověď probíhá zde".
- Důslednost: Zajišťuje, že všechny výstupy mají stejnou strukturu, což usnadňuje následné zpracování a analýzu.
- Čitelnost: Lidé mohou snadno rozlišit proces uvažování a odpověď, což zlepšuje uživatelský zážitek.
2.2 Trajektorie uvažování: "Myšlenkový řetězec" řešení modelu
- Trajektorie uvažování: Podrobné kroky generované modelem při řešení problému ukazují logický řetězec modelu.
- Příklad:
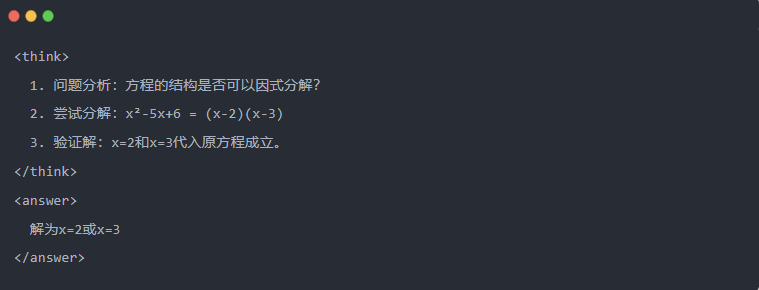
2.3 Odběr vzorků: Filtrování dobrých dat z "pokusů a omylů
- Odběr vzorků pro odmítnutí: Generování více kandidátských odpovědí a ponechání těch dobrých, podobně jako při psaní návrhu a následném kopírování správné odpovědi při zkoušce.
Ⅲ.Generování destilovaných dat
Prvním krokem při destilaci znalostí je vytvoření vysoce kvalitních "výukových dat", ze kterých se budou malé modely učit.
Zdroje dat:
- 80% z argumentačních dat vygenerovaných pomocí DeepSeek-R1
- 20% z obecných dat úlohy DeepSeek-V3.
Proces generování destilačních dat:
- Filtrování pravidel: automaticky kontroluje správnost odpovědi (např. zda matematická odpověď odpovídá vzorci).
- Kontrola čitelnosti: eliminuje smíšené jazyky (např. smíšenou čínštinu a angličtinu) nebo dlouhé odstavce.
- Generování řízené šablonou: vyžaduje, aby DeepSeek-R1 vytvářel inferenční trajektorie podle šablony.
- Filtrování s výběrem vzorků:
- Integrace dat: nakonec bylo vygenerováno 800 000 vysoce kvalitních vzorků, z toho asi 600 000 inferenčních dat a asi 200 000 obecných dat.
Ⅳ.Destilační proces
Role učitele a žáka:
- DeepSeek-R1 jako model učitele;
- Modely řady Qwen jako studentský model.
Kroky školení:
Nejprve vstup dat: do modelu Qwen je třeba zadat část otázky z 800 000 vzorků a požádat jej o vygenerování kompletní inferenční trajektorie (proces myšlení + odpověď) podle šablony. To je velmi důležitý krok
Dále výpočet ztráty: porovnání výstupu generovaného žákovským modelem s inferenční trajektorií učitelského modelu a zarovnání textové sekvence pomocí dolaďování pod dohledem (SFT). Pokud si nejste jisti, co je to SFT, doufám, že vyhledáte toto klíčové slovo, abyste se dozvěděli více.
Dokončení aktualizace parametrů většího modelu studenta: Optimalizujte parametry modelu Qwen pomocí zpětného šíření, abyste aproximovali výstup modelu učitele.
Několikanásobné opakování tohoto procesu školení zajišťuje dostatečný přenos znalostí. Tím je dosaženo původního cíle školení. Uvedeme vám příklad, na kterém to demonstrujeme, a doufáme, že to pochopíte.
Ⅴ. Příklad demonstrace
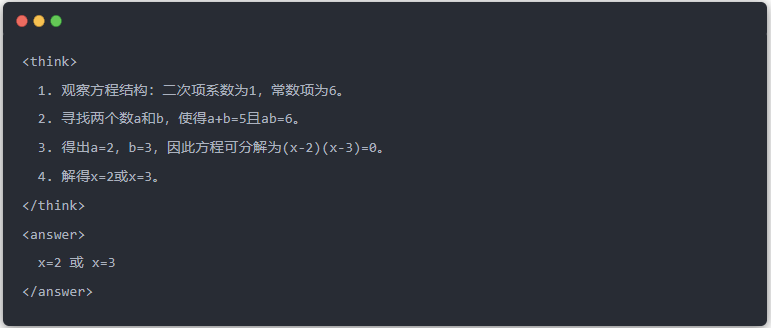
Článek demonstruje destilační efekt na konkrétní úloze řešení rovnice (solve equation):
- Standardní výstup modelu učitele:
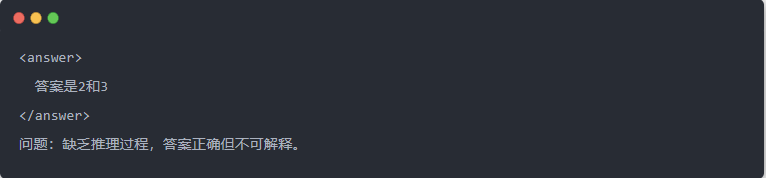
- Výstup Qwen-7B před destilací:
- Výstup Qwen-7B po destilaci:
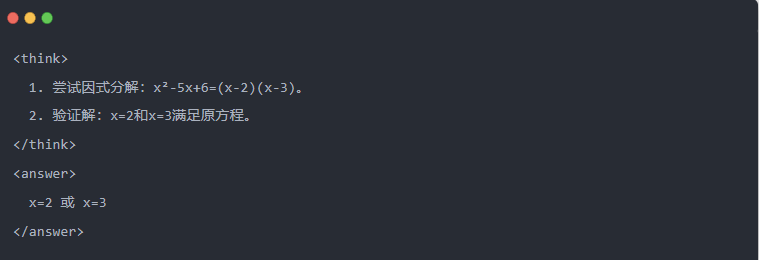
- Optimalizované řešení: Odpověď je stejná jako u modelu učitele.
Ⅵ. Shrnutí
Prostřednictvím destilace znalostí se schopnost odvozování DeepSeek-R1 efektivně přenáší do řady malých modelů Qwen. Tento proces se zaměřuje na šablonovitý výstup a vzorkování odmítnutí. Díky strukturovanému generování dat a zdokonalenému tréninku mohou malé modely provádět složité inferenční úlohy i ve scénářích s omezenými zdroji. Tato technologie poskytuje důležitou referenci pro odlehčené nasazení modelů umělé inteligence.



