V předvečer jarního festivalu byl vydán model DeepSeek-R1. Díky své čistě RL architektuře se poučil z velkých inovací společnosti CoT a překonává ji. ChatGPT v matematice, kódu a logickém uvažování.
Kromě toho se DeepSeek díky svým otevřeným modelovým váhám, nízkým nákladům na trénink a levným cenám API stal hitem na internetu, což dokonce způsobilo, že ceny akcií společností NVIDIA a ASML na čas prudce klesly.
Společnost DeepSeek vydala také aktualizovanou verzi multimodálního velkého modelu Janus (Janus), Janus-Pro, který zdědil jednotnou architekturu předchozí generace multimodálního porozumění a generování a optimalizoval strategii trénování, škálování tréninkových dat a velikosti modelu, což přináší vyšší výkon.

Janus-Pro
Janus-Pro je jednotný multimodální jazykový model (MLLM), který dokáže současně zpracovávat úlohy multimodálního porozumění a úlohy generování, tj. dokáže porozumět obsahu obrázku a zároveň generovat text.
Odděluje vizuální kodéry pro multimodální porozumění a generování (tj. pro vstup porozumění obrazu a vstup a výstup generování obrazu se používají různé tokenizéry) a zpracovává je pomocí jednotného autoregresního transformátoru.
Jako pokročilý multimodální model porozumění a generování je vylepšenou verzí předchozího modelu Janus.
Janus (Janus) je v římské mytologii bůh strážce se dvěma tvářemi, který symbolizuje rozpor a přechod. Má dvě tváře, což také naznačuje, že model Janus dokáže chápat a vytvářet obrazy, což je velmi vhodné. Co přesně tedy PRO inovoval?
Janus jako malý model 1.3B je spíše náhledovou verzí než oficiální verzí. Zkoumá jednotné multimodální porozumění a generování, ale má mnoho problémů, jako jsou nestabilní efekty generování obrázků, velké odchylky od uživatelských pokynů a nedostatečné detaily.
Verze Pro optimalizuje strategii trénování, zvětšuje soubor tréninkových dat a poskytuje větší model (7B), ze kterého lze vybírat, a zároveň poskytuje model 1B.
Architektura modelu
Jaus-Pro a Janus jsou z hlediska architektury modelu totožné. (Pouze 1,3B! Janus sjednocuje multimodální porozumění a generování)
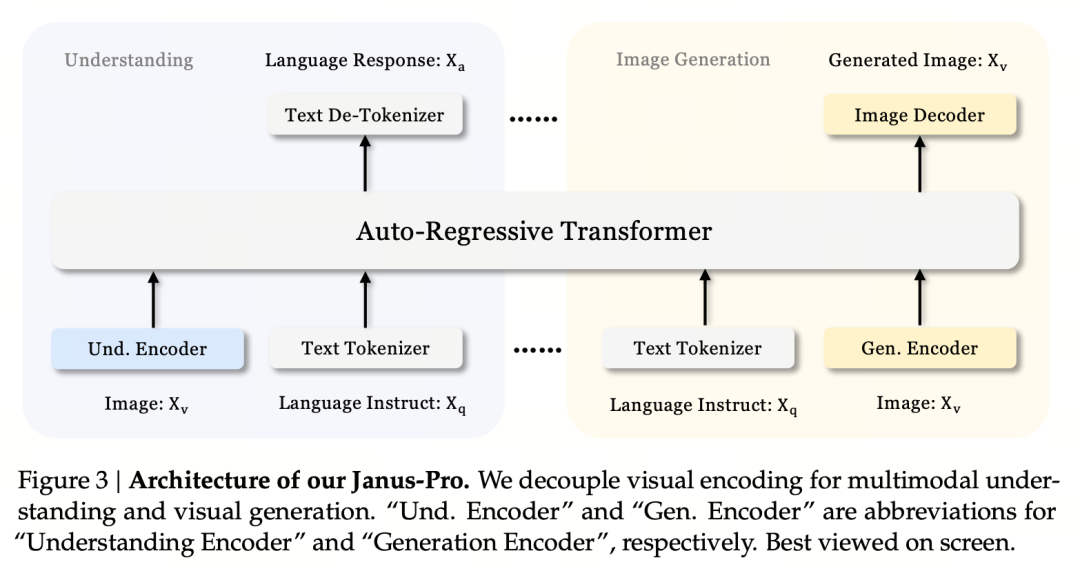
Hlavním principem návrhu je oddělit vizuální kódování a podpořit multimodální porozumění a generování. Janus-Pro kóduje původní obrazový/textový vstup odděleně, extrahuje z něj vysokorozměrné rysy a zpracovává je prostřednictvím jednotného autoregresního transformátoru.
Multimodální porozumění obrazu používá SigLIP ke kódování obrazových prvků (modrý kodér na obrázku výše) a úloha generování používá tokenizátor VQ k diskretizaci obrazu (žlutý kodér na obrázku výše). Nakonec jsou všechny posloupnosti rysů vloženy do LLM ke zpracování
Strategie školení
Pokud jde o strategii vzdělávání, společnost Janus-Pro dosáhla dalších zlepšení. Stará verze systému Janus používala třístupňovou tréninkovou strategii, v níž se v etapě I trénuje vstupní adaptér a hlava pro generování obrazu pro porozumění obrazu a generování obrazu, v etapě II se provádí jednotné předtrénování a v etapě III se na tomto základě dolaďuje kódovač porozumění. (Tréninková strategie systému Janus je znázorněna na obrázku níže.)
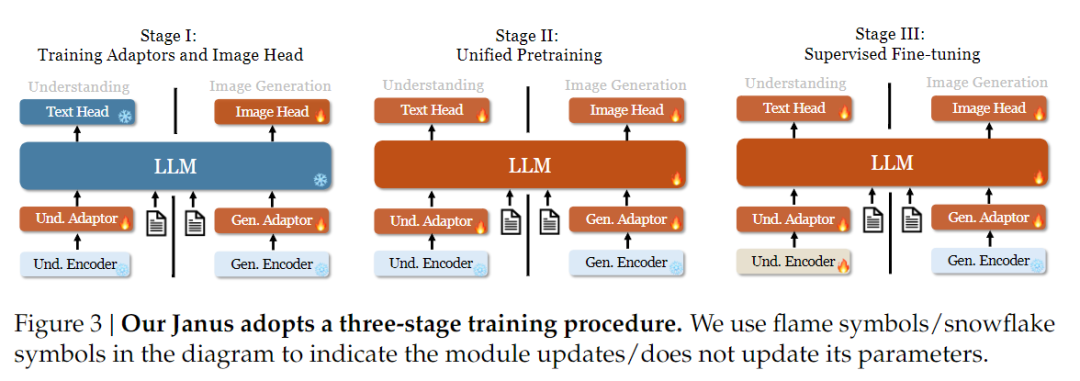
Tato strategie však používá metodu PixArt k rozdělení trénování generování textu na obraz ve fázi II, což má za následek nízkou výpočetní účinnost.
Za tímto účelem jsme prodloužili dobu tréninku v první fázi a přidali trénink s daty sítě ImageNet, aby model mohl efektivně modelovat závislosti pixelů s pevnými parametry LLM. V etapě II jsme vyřadili data sítě ImageNet a k trénování jsme použili přímo data dvojic text-obrázek, což zlepšuje efektivitu trénování. Kromě toho jsme v etapě III upravili poměr dat (multimodální:pouze textová:vizuálně-sémantická grafická data ze 7:3:10 na 5:1:4), čímž jsme zlepšili multimodální porozumění při zachování schopnosti vizuálního generování.
Škálování tréninkových dat
Janus-Pro také škáluje tréninková data systému Janus, pokud jde o multimodální porozumění a vizuální generování.
Multimodální porozumění: Předtréninková data fáze II jsou založena na DeepSeek-VL2 a zahrnují přibližně 90 milionů nových vzorků, včetně dat pro popisky obrázků (například YFCC) a dat pro porozumění tabulkám, grafům a dokumentům (například Docmatix).
Fáze III dolaďování pod dohledem dále zavádí porozumění MEME, čínská dialogová data atd., aby se zlepšil výkon modelu při zpracování více úloh a schopnosti dialogu.
Vizuální generování: Předchozí verze používaly reálná data s nízkou kvalitou a vysokým šumem, což ovlivňovalo stabilitu a estetiku generovaných textů.
Janus-Pro zavádí přibližně 72 milionů syntetických estetických dat, čímž se poměr reálných a syntetických dat dostává na hodnotu 1:1. Experimenty ukázaly, že syntetická data urychlují konvergenci modelu a výrazně zlepšují stabilitu a estetickou kvalitu generovaných snímků.
Modelové škálování
Janus Pro rozšiřuje velikost modelu na 7B, zatímco předchozí verze Janusu používala 1,5B DeepSeek-LLM k ověření účinnosti oddělování vizuálního kódování. Experimenty ukazují, že větší LLM výrazně urychluje konvergenci multimodálního porozumění a vizuálního generování, což dále ověřuje silnou škálovatelnost metody.

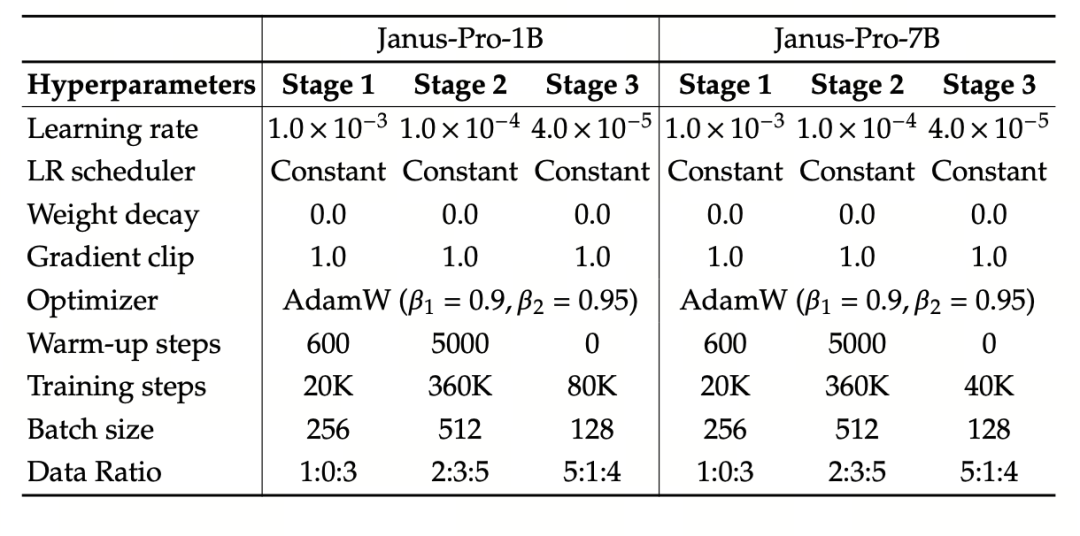
Experiment používá jako základní jazykový model DeepSeek-LLM (1.5B a 7B, podporující maximální sekvenci 4096). Pro multimodální úlohu porozumění je jako vizuální kodér použit SigLIP-Large-Patch16-384, velikost slovníku kodéru je 16384, násobek snížení vzorkování obrazu je 16 a adaptéry pro porozumění i generování jsou dvouvrstvé MLP.
Ve druhé fázi tréninku se používá strategie včasného zastavení 270K, všechny snímky jsou jednotně upraveny na rozlišení 384 × 384 a pro zvýšení efektivity tréninku se používá balení sekvencí . Janus-Pro je trénován a vyhodnocován pomocí HAI-LLM. Verze 1,5B/7B byly trénovány na 16/32 uzlech (8×Nvidia A100 40GB na uzel) po dobu 9/14 dní, v tomto pořadí.
Hodnocení modelu
Janus-Pro byl hodnocen samostatně v multimodálním porozumění a generování. Celkově může být porozumění mírně slabé, ale mezi open source modely stejné velikosti je považováno za vynikající (hádejte, že je do značné míry omezeno pevným vstupním rozlišením a možnostmi OCR).
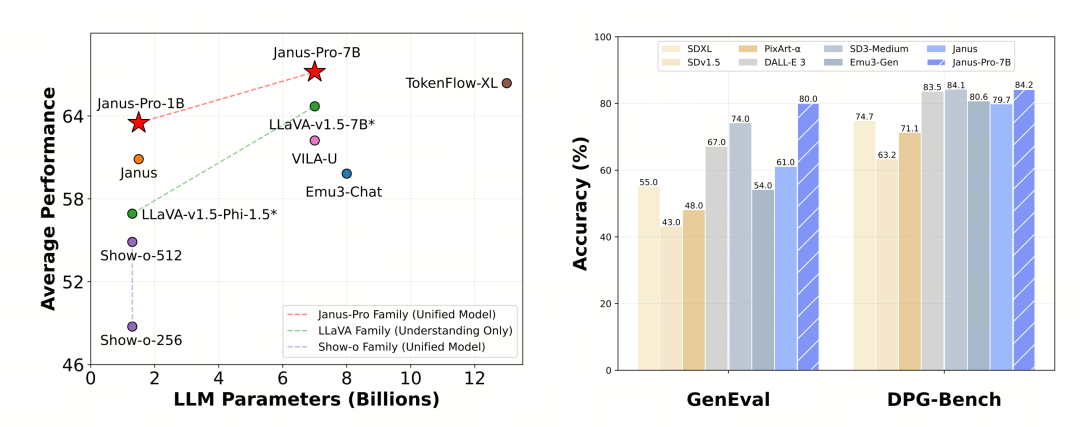
Janus-Pro-7B dosáhl v benchmarkovém testu MMBench skóre 79,2 bodů, což se blíží úrovni open source modelů první úrovně (stejná velikost InternVL2.5 a Qwen2-VL se pohybuje kolem 82 bodů). Oproti předchozí generaci Janusu se však jedná o dobré zlepšení.
Z hlediska generování obrázků je zlepšení oproti předchozí generaci ještě výraznější a mezi open source modely je považováno za vynikající úroveň. Skóre Janus-Pro ve srovnávacím testu GenEval (0,80) rovněž překonává modely jako DALL-E 3 (0,67) a Stable Diffusion 3 Medium (0,74).