Společnost DeepSeek aktualizovala své webové stránky.
V časných hodinách na Silvestra společnost DeepSeek na GitHubu náhle oznámila, že v prostoru projektu Janus byl otevřen zdrojový kód modelu Janus-Pro a technická zpráva.
Nejprve zdůrazněme několik klíčových bodů:
- Na stránkách Model Janus-Pro je multimodální model, který může současně provádět úlohy multimodálního porozumění a generování obrazu. Má celkem dvě verze parametrů, Janus-Pro-1B a Janus-Pro-7B.
- Základní inovací Janus-Pro je oddělit multimodální porozumění a generování, což jsou dva různé úkoly. To umožňuje efektivní řešení těchto dvou úloh v rámci jednoho modelu..
- Janus-Pro je v souladu s architekturou modelu Janus, který společnost DeepSeek zveřejnila v říjnu loňského roku, ale v té době neměl Janus velký objem. Dr. Charles, odborník na algoritmy v oblasti vidění, nám řekl, že předchozí Janus byl "průměrný" a "nebyl tak dobrý jako jazykový model společnosti DeepSeek".

Má vyřešit obtížný problém v oboru: vyvážit multimodální porozumění a tvorbu obrazu.
Podle oficiálního představení DeepSeek, Janus-Pro dokáže nejen porozumět obrázkům, extrahovat a pochopit text na obrázcích, ale také současně vytvářet obrázky.
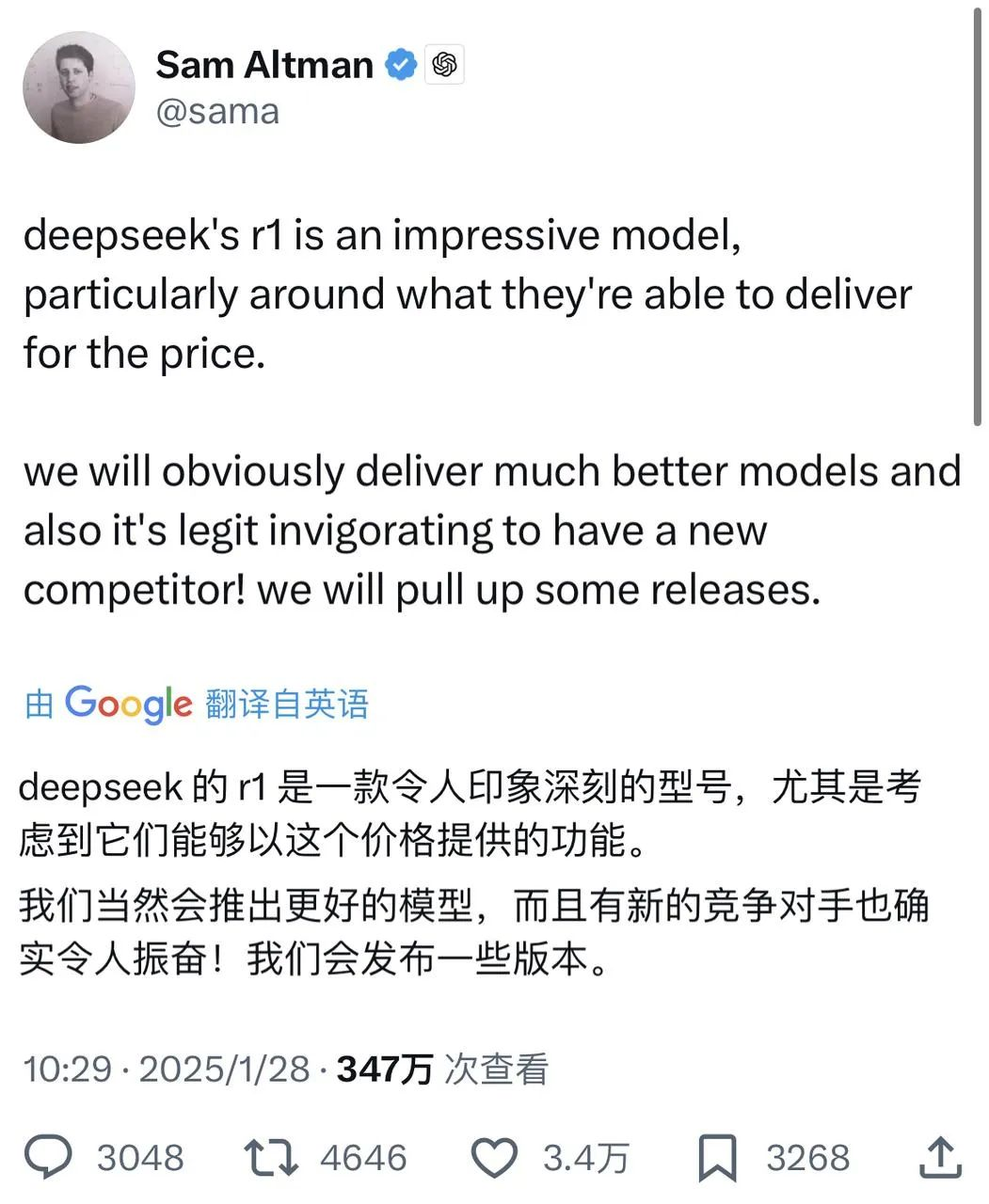
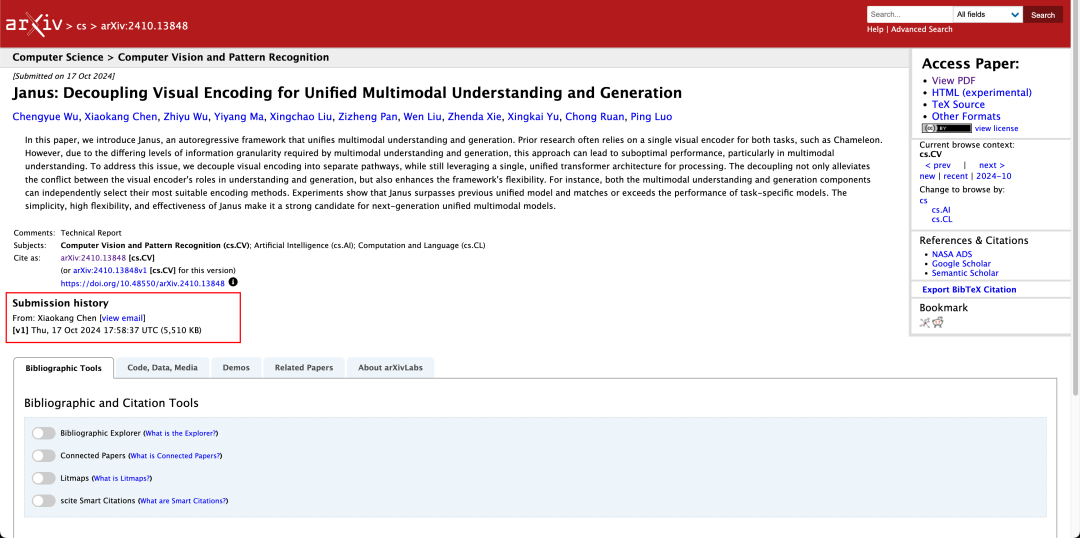
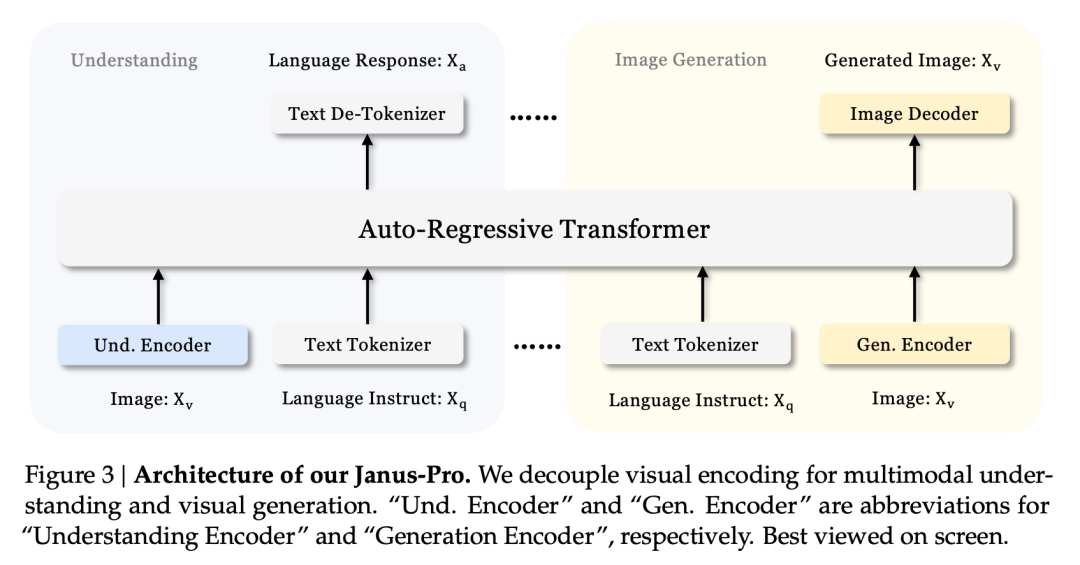
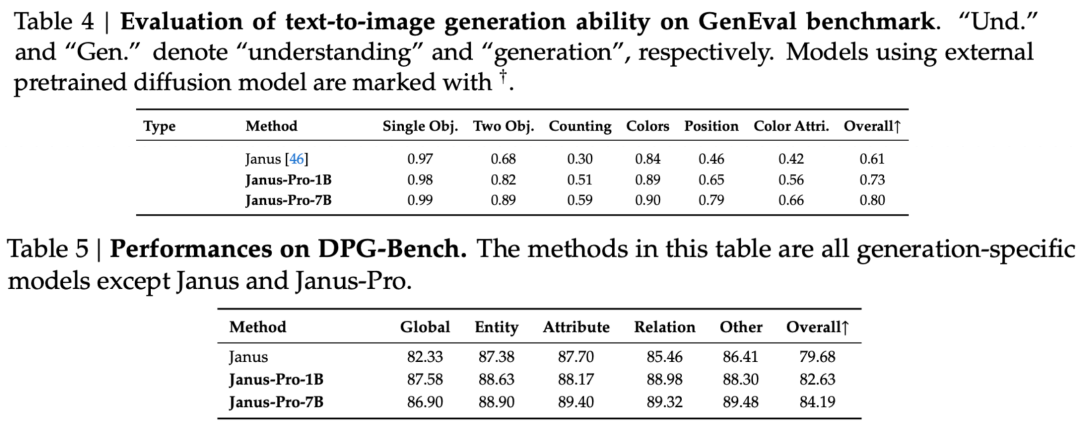
V technické zprávě se uvádí, že ve srovnání s jinými modely stejného typu a řádu dosáhl Janus-Pro-7B v testovacích sadách GenEval a DPG-Bench výsledků předčí ostatní modely, jako jsou SD3-Medium a DALL-E 3.
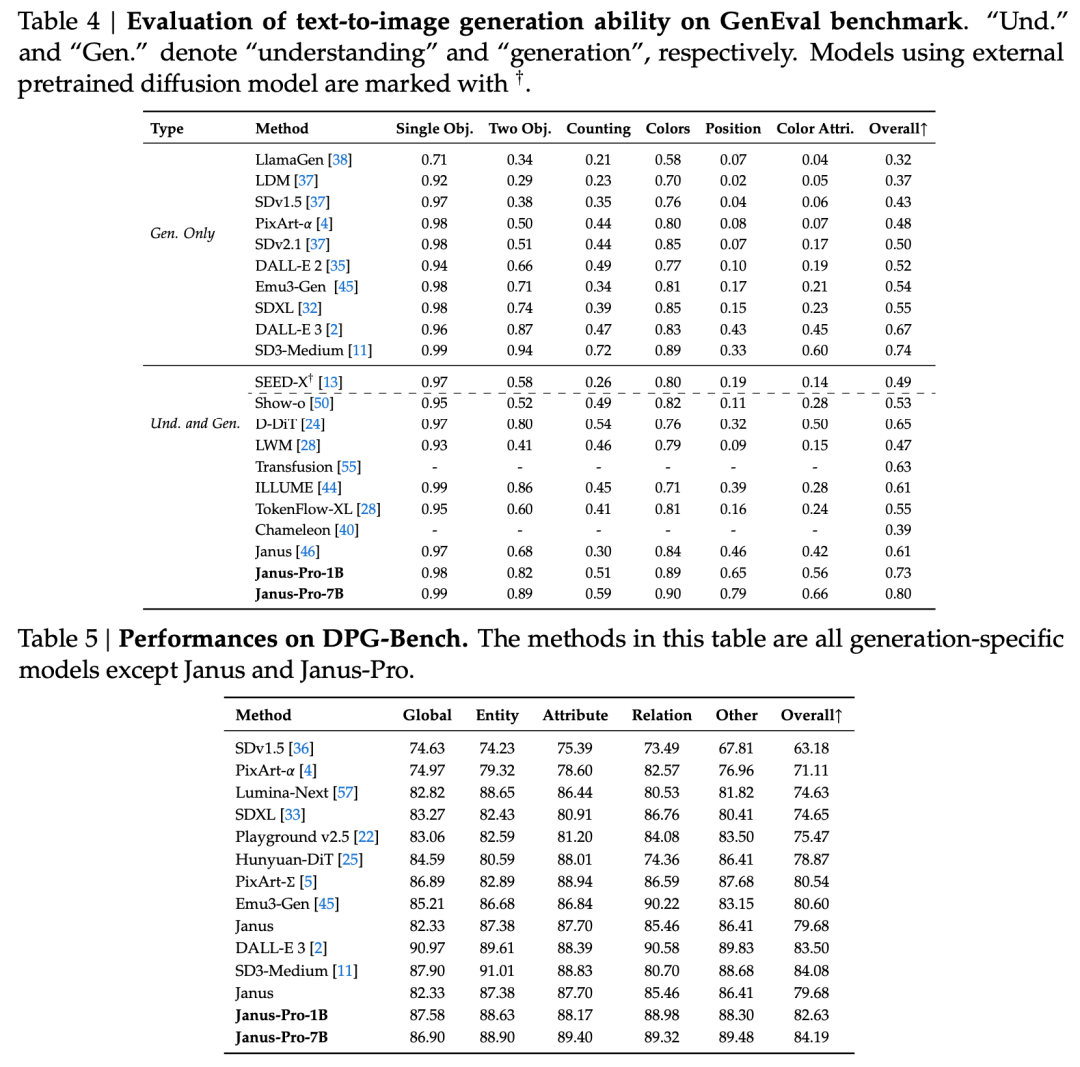
Úředník uvádí i příklady 👇:
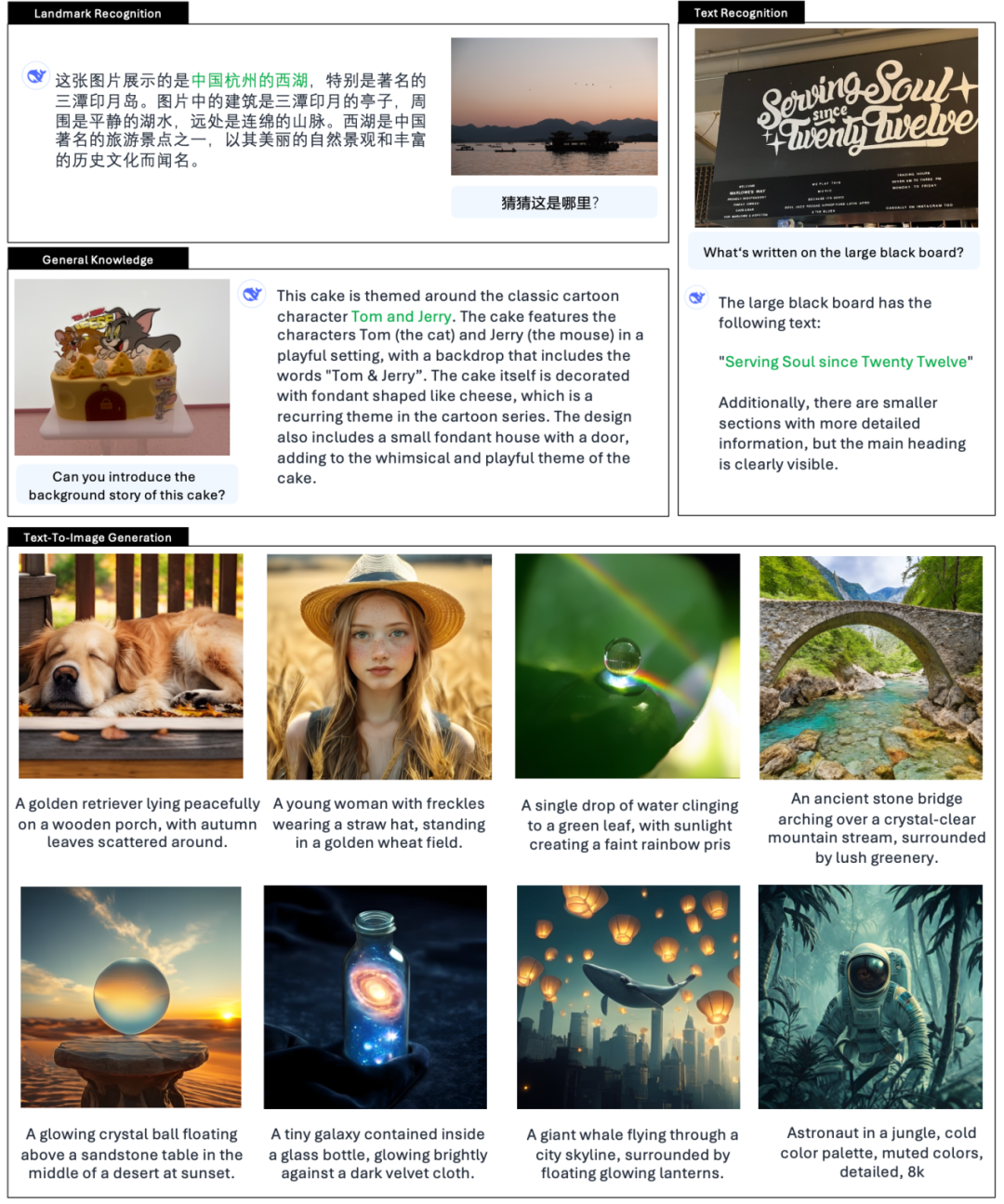
Nové funkce zkouší také mnoho uživatelů sítě X.

Občas však dochází i k pádům.
Nahlédnutím do technických dokumentů na DeepSeek, jsme zjistili, že Janus Pro je optimalizace založená na systému Janus, který byl vydán před třemi měsíci.
Hlavní inovací této řady modelů je oddělit úlohy vizuálního porozumění od úloh vizuální tvorby, aby bylo možné vyvážit účinky obou úloh.
Není neobvyklé, že model provádí multimodální porozumění a generování současně. D-DiT i TokenFlow-XL v této testovací sadě tuto schopnost mají.
Pro Janus je však charakteristické, že oddělením zpracování model, který dokáže provádět multimodální porozumění a generování, vyrovnává efektivitu obou úkolů.
Vyvážení efektivity těchto dvou úkolů je v tomto odvětví obtížný problém. Dříve se uvažovalo o použití stejného kodéru pro co nejširší implementaci multimodálního porozumění a generování.
Výhodou tohoto přístupu je jednoduchá architektura, žádné nadbytečné nasazení a sladění s textovými modely (které rovněž používají stejné metody k dosažení generování textu a porozumění textu). Dalším argumentem je, že toto spojení více schopností může vést k určitému stupni emergence.
Ve skutečnosti si však po spojení generování a porozumění budou tyto dvě úlohy odporovat - porozumění obrazu vyžaduje, aby model abstrahoval ve vysokých dimenzích a extrahoval jádro sémantiky obrazu, která je vychýlena směrem k makroskopickým rozměrům. Generování obrazu se naproti tomu zaměřuje na vyjádření a generování lokálních detailů na úrovni pixelů.
Obvyklou praxí v oboru je upřednostňovat schopnosti generování obrazu. Výsledkem jsou multimodální modely, které může generovat kvalitnější snímky, ale výsledky porozumění snímkům jsou často průměrné.
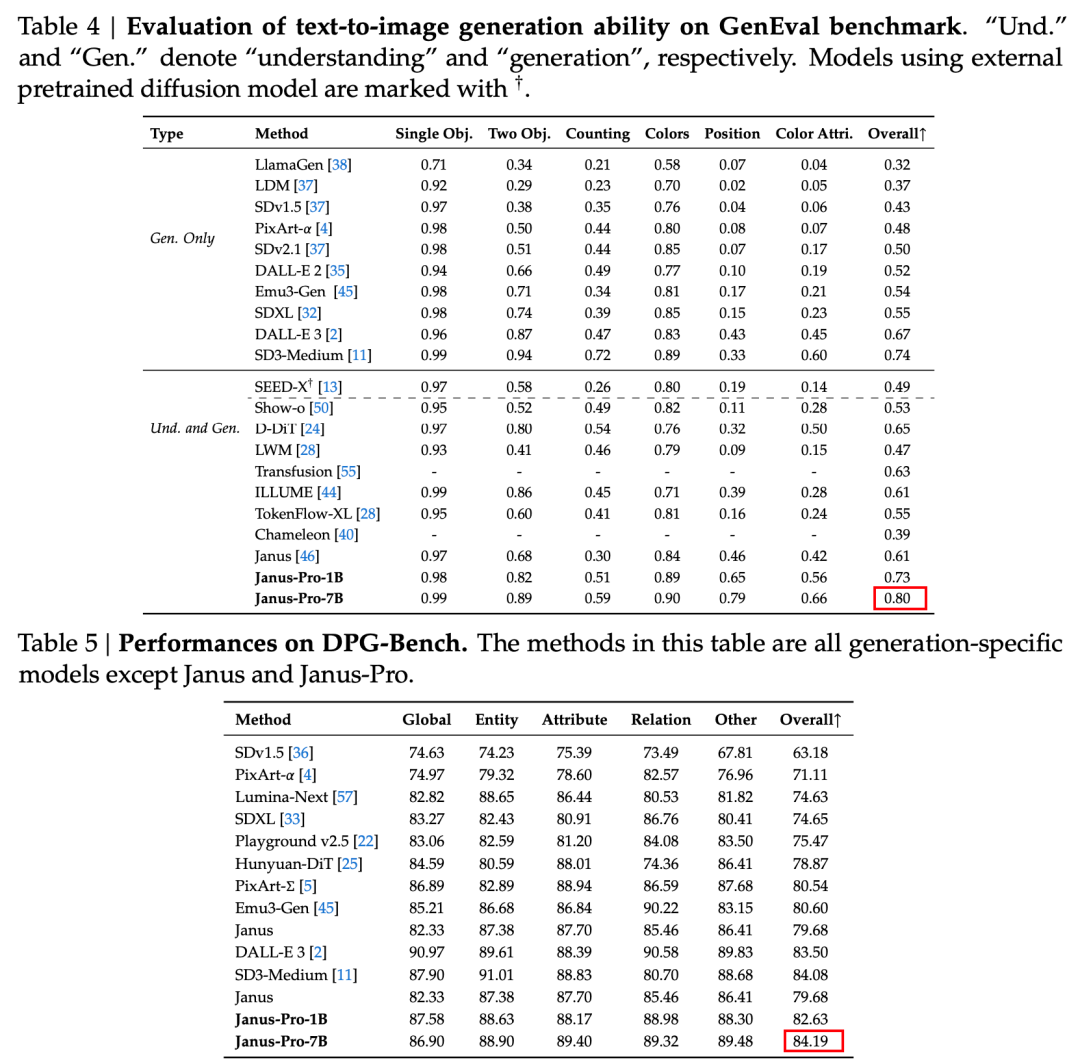
Oddělená architektura systému Janus a optimalizovaná tréninková strategie Janus-Pro
Oddělená architektura systému Janus umožňuje, aby model sám vyvažoval úlohy porozumění a generování.
Podle výsledků uvedených v oficiální technické zprávě dosahuje Janus-Pro-7B dobrých výsledků v mnoha testovacích sadách, ať už jde o multimodální porozumění nebo generování obrazu.

Pro multimodální porozumění, Model Janus-Pro-7B se umístil na prvním místě ve čtyřech ze sedmi hodnocených datových sad a na druhém místě ve zbývajících třech, s mírným odstupem za nejlépe hodnoceným modelem.
Pro generování obrázků, Janus-Pro-7B dosáhl prvního místa v celkovém skóre v obou hodnotících sadách GenEval a DPG-Bench.
Tento víceúlohový efekt je způsoben především tím, že řada Janus používá dva vizuální kodéry pro různé úkoly:
- Porozumění kodéru: slouží k extrakci sémantických rysů v obrazech pro úlohy porozumění obrazu (jako jsou otázky a odpovědi na obrázky, vizuální klasifikace atd.).
- Generativní kodér: převádí obrázky na diskrétní reprezentaci (např. pomocí kodéru VQ) pro úlohy generování textu na obrázky.
S touto architekturou, model může nezávisle optimalizovat výkon každého kodéru, takže multimodální úlohy porozumění a generování mohou dosáhnout nejlepšího výkonu.
Tato oddělená architektura je společná pro Janus-Pro a Janus. Jaké iterace tedy Janus-Pro v posledních měsících prodělal?
Jak je patrné z výsledků hodnotící sady, aktuální verze Janus-Pro-1B má ve srovnání s předchozí verzí Janus zlepšení ve skóre různých hodnotících sad přibližně o 10% až 20%. Janus-Pro-7B má po rozšíření počtu parametrů nejvyšší zlepšení o přibližně 45% ve srovnání s Janusem.

Co se týče podrobností o školení, technická zpráva uvádí, že současná verze Janus-Pro si oproti předchozímu modelu Janus zachovává základní návrh oddělené architektury a navíc iteruje na velikost parametrů, strategie trénování a tréninková data.
Nejprve se podívejme na parametry.
První verze systému Janus měla pouze 1,3B parametrů a současná verze Pro obsahuje modely s 1B a 7B parametry.
Tyto dvě velikosti odrážejí škálovatelnost architektury Janus. Model 1B, který je nejlehčí, již byl použit externími uživateli pro běh v prohlížeči pomocí WebGPU.
K dispozici je také na strategie školení.
V souladu s rozdělením tréninkových fází programu Janus má Janus Pro celkem tři tréninkové fáze, které jsou v dokumentu přímo rozděleny na fázi I, fázi II a fázi III.
Společnost Janus-Pro zachovala základní myšlenky a cíle školení v jednotlivých fázích, ale zlepšila délku školení a údaje o školení ve všech třech fázích. Níže jsou uvedena konkrétní zlepšení ve třech fázích:
Fáze I - Delší doba tréninku
V porovnání se systémem Janus prodloužila technologie Janus-Pro dobu tréninku v první fázi, zejména při tréninku adaptérů a obrazových hlav ve vizuální části. To znamená, že učení vizuálních rysů bylo věnováno více času na trénink, a je naděje, že model dokáže plně porozumět detailním rysům obrazů (jako je mapování pixelů na sémantické rysy).
Tento rozšířený trénink pomáhá zajistit, aby trénink vizuální části nebyl narušován jinými moduly.
Fáze II - Odstranění dat sítě ImageNet a přidání multimodálních dat
Ve druhé fázi Janus dříve odkazoval na PixArt a trénoval ve dvou částech. První část byla trénována pomocí datové sady ImageNet pro úlohu klasifikace obrázků a druhá část byla trénována pomocí běžných dat pro převod textu na obrázek. Přibližně dvě třetiny času v etapě II byly věnovány tréninku v první části.
Janus-Pro odstraňuje trénink ImageNet ve fázi II. Tato konstrukce umožňuje, aby se model během fáze II soustředil na trénování dat z textu na obraz. Podle experimentálních výsledků to může výrazně zlepšit využití dat text-obraz.
Kromě úpravy návrhu tréninkové metody se soubor tréninkových dat použitý ve druhé fázi již neomezuje pouze na úlohu klasifikace jednoho obrazu, ale zahrnuje také více dalších typů multimodálních dat, jako je popis obrazu a dialog, pro společné trénování.
Fáze III - Optimalizace poměru dat
Ve fázi III tréninku Janus-Pro upravuje poměr různých typů tréninkových dat.
Dříve byl poměr multimodálních dat pro porozumění, prostých textových dat a textově-obrázkových dat v trénovacích datech používaných systémem Janus ve fázi III 7:3:10. Janus-Pro snižuje poměr posledních dvou typů dat a upravuje poměr tří typů dat na 5:1:4, tj. věnuje větší pozornost úloze multimodálního porozumění.
Podívejme se na tréninková data.
Ve srovnání s Janusem Janus-Pro tentokrát výrazně zvyšuje množství vysoce kvalitních syntetická data.
Rozšiřuje množství a rozmanitost tréninkových dat pro multimodální porozumění a generování obrazu.
Rozšíření multimodálních dat pro porozumění:
Janus-Pro se při trénování odkazuje na datovou sadu DeepSeek-VL2 a přidává přibližně 90 milionů dalších datových bodů, včetně nejen datových sad popisů obrázků, ale také datových sad složitých scén, jako jsou tabulky, grafy a dokumenty.
Ve fázi dolaďování pod dohledem (fáze III) pokračuje v přidávání souborů dat týkajících se porozumění MEME a zlepšování zkušeností s dialogem (včetně čínského dialogu).
Rozšíření vizuálních dat generace:
Původní reálná data měla nízkou kvalitu a vysokou úroveň šumu, což způsobovalo, že model produkoval nestabilní výstupy a obrázky nedostatečné estetické kvality v úlohách převodu textu na obraz.
Janus-Pro přidal do tréninkové fáze přibližně 72 milionů nových vysoce estetických syntetických dat, čímž se poměr reálných dat k syntetickým datům v předtréninkové fázi zvýšil na 1:1.
Všechny podněty pro syntetická data byly převzaty z veřejných zdrojů. Experimenty ukázaly, že po přidání těchto dat model rychleji konverguje a generované obrázky mají zjevně lepší stabilitu a vizuální krásu.
Pokračování revoluce v efektivitě?
Celkově lze říci, že touto verzí přinesla společnost DeepSeek revoluci v efektivitě vizuálních modelů.
Na rozdíl od vizuálních modelů, které se zaměřují na jedinou funkci, nebo multimodálních modelů, které upřednostňují určitý úkol, Janus-Pro vyvažuje účinky dvou hlavních úkolů - generování obrazu a multimodálního porozumění - ve stejném modelu.
Navzdory svým malým parametrům navíc v hodnocení porazilOpenAI DALL-E 3 a SD3-Medium.
Po rozšíření na zem stačí podniku nasadit model, který přímo realizuje dvě funkce generování obrazu a porozumění. Ve spojení s velikostí pouhých 7B jsou náročnost a náklady na nasazení mnohem nižší.
V souvislosti s předchozími verzemi R1 a V3 zpochybňuje společnost DeepSeek stávající pravidla hry pomocí. "kompaktní architektonické inovace, lehké modely, modely s otevřeným zdrojovým kódem a mimořádně nízké náklady na školení.". To je důvodem paniky mezi západními technologickými giganty a dokonce i na Wall Street.
Právě teď Sam Altman, který se několik dní nechal strhnout veřejným míněním, konečně pozitivně reagoval na informace o DeepSeek na X - pochválil R1 a řekl, že OpenAI učiní nějaká oznámení.