
Ⅰ. Mi a tudás desztillálása?
A tudásdesztilláció egy olyan modelltömörítési technika, amelyet arra használnak, hogy a tudást egy nagy, összetett modellből (a tanári modellből) egy kis modellbe (a tanulói modellbe) vigyék át.
Az alapelv az, hogy a tanító modell az eredmények (például valószínűségi eloszlások vagy következtetési folyamatok) előrejelzésével tanítja a tanuló modellt, a tanuló modell pedig ezen előrejelzésekből tanulva javítja teljesítményét.
Ez a módszer különösen alkalmas erőforrás-korlátozott eszközök, például mobiltelefonok vagy beágyazott eszközök esetében.
II.Alapfogalmak
2.1 Sablonok kialakítása
- Sablon: A modell kimenetének szabványosítására használt strukturált formátum. Például
- : Az érvelési folyamat kezdetét jelzi.
- : Az érvelési folyamat végét jelzi.
- : A végső válasz kezdetét jelöli.
- : A végső válasz végét jelöli.
- Funkció:
- Tisztaság: Ez a modellnek azt üzeni, hogy "a gondolkodási folyamat itt kezdődik, a válasz pedig ott".
- Következetesség: Biztosítja, hogy minden kimenet ugyanazt a struktúrát kövesse, megkönnyítve a későbbi feldolgozást és elemzést.
- Olvashatóság: Az emberek könnyen meg tudják különböztetni az érvelési folyamatot és a választ, ami javítja a felhasználói élményt.
2.2 Érvelési pálya: A modell megoldásának "gondolkodási lánca"
- Érvelési pálya: A modell által egy probléma megoldása során generált részletes lépések mutatják a modell logikai láncát.
- Példa:
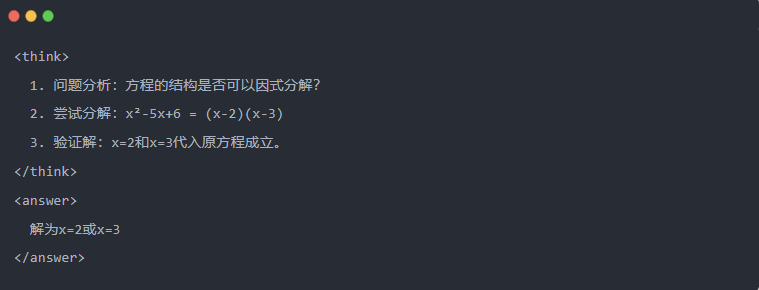
2.3 Visszautasított mintavétel: A jó adatok kiszűrése a "próba és hiba" módszerből
- Visszautasított mintavétel: Több jelölt válaszának generálása és a jó válaszok megtartása, hasonlóan ahhoz, mint amikor egy vizsgán egy vázlatot írunk, majd a helyes választ lemásoljuk.
Ⅲ.A desztillált adatok előállítása
A tudás lepárlásának első lépése, hogy jó minőségű "tanítási adatokat" hozzon létre, amelyekből a kis modellek tanulhatnak.
Adatforrások:
- 80% az érvelési adatokból, amelyeket a DeepSeek-R1
- 20% a DeepSeek-V3 általános feladatadatokból.
A desztillációs adatok előállításának folyamata:
- Szabályszűrés: automatikusan ellenőrzi a válasz helyességét (pl. hogy a matematikai válasz megfelel-e a képletnek).
- Olvashatósági ellenőrzés: kiküszöböli a vegyes nyelveket (pl. kínai és angol vegyesen) vagy a hosszú bekezdéseket.
- Sablonvezérelt generálás: a DeepSeek-R1-nek a sablon szerinti következtetési pályák kimenetéhez szükséges.
- Visszautasítás mintavételezés szűrése:
- Adatintegráció: 800 000 kiváló minőségű minta került végül generálásra, ebből körülbelül 600 000 következtetési adat és körülbelül 200 000 általános adat.
Ⅳ.Desztillációs eljárás
Tanár és diák szerepek:
- DeepSeek-R1 mint tanári modell;
- Qwen sorozatú modellek, mint a diákmodell.
Képzési lépések:
Először is, adatbevitel: a 800 000 minta kérdéses részét be kell vinni a Qwen modellbe, és meg kell kérni, hogy generáljon egy teljes következtetési pályát (gondolkodási folyamat + válasz) a sablon szerint. Ez egy nagyon fontos lépés
Ezután veszteségszámítás: a tanulómodell által generált kimenet összehasonlítása a tanári modell következtetési pályájával, és a szövegsorozat összehangolása felügyelt finomhangolással (SFT). Ha nem tudja, mi az SFT, remélem, rákeres erre a kulcsszóra, hogy többet tudjon meg.
A hallgató nagyobb modelljének teljes paraméterfrissítése: A Qwen modell paramétereinek optimalizálása backpropagációval a tanári modell kimenetének közelítése érdekében.
A képzési folyamat többszöri megismétlése biztosítja, hogy a tudás kellő mértékben átadásra kerüljön. Ezáltal megvalósul az eredeti képzési cél. Egy példával szemléltetjük ezt, és reméljük, hogy megérti.
Ⅴ. Példa bemutatására
A cikk a desztillációs hatást egy konkrét egyenletmegoldási feladaton (oldj meg egy egyenletet) keresztül mutatja be:
- A tanári modell standard kimenete:
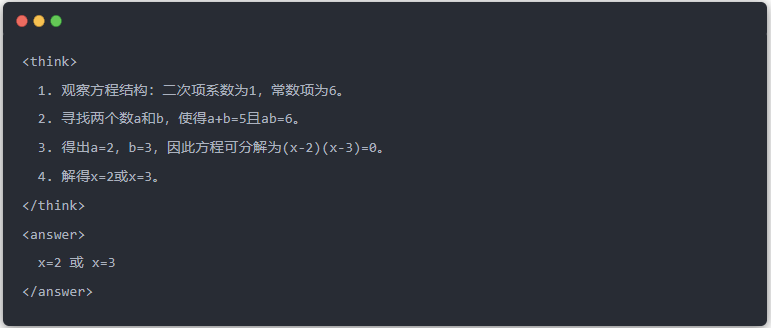
- Qwen-7B kimenete desztilláció előtt:
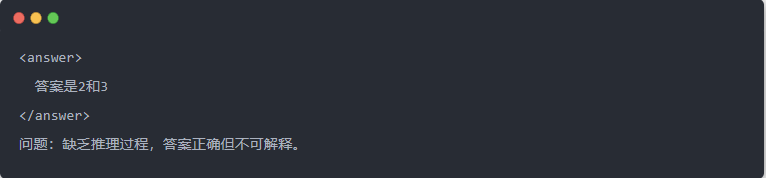
- Qwen-7B kimenet desztilláció után:
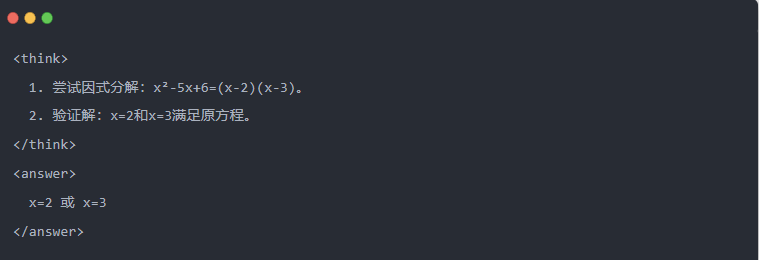
- Optimalizált megoldás: Strukturált következtetési folyamat generálódik, és a válasz megegyezik a tanári modellel.
Ⅵ. Összefoglaló
A tudás lepárlásával a DeepSeek-R1 következtetési képessége hatékonyan átkerül a Qwen kis modellek sorozatába. Ez a folyamat a sablonos kimenetre és a selejtes mintavételre összpontosít. A strukturált adatgenerálás és a kifinomult képzés révén a kis modellek erőforrás-korlátozott forgatókönyvekben is képesek komplex következtetési feladatok elvégzésére. Ez a technológia fontos hivatkozási alapot nyújt a mesterséges intelligencia modellek könnyített telepítéséhez.



