
és csendben beköszöntött a mesterséges intelligencia korszaka.
Valószínűleg senki sem számított arra, hogy ez a kínai újév, a legforróbb téma már nem a hagyományos internetes vörös boríték csata, aki partner a Tavaszi Fesztivál Gála, de AI vállalatok.
A tavaszi fesztivál közeledtével a nagy modellgyártó cégek egyáltalán nem lazítottak, modellek és termékek egész sorát frissítették. A legtöbbet azonban a DeepSeek, a tavaly felbukkant "nagy modellcég" beszélt róla.
Január 20-án este, MélySeek kiadta a DeepSeek-R1 érvelési modelljének hivatalos verzióját. Alacsony képzési költséget használva közvetlenül olyan teljesítményt képzett ki, amely nem marad el az OpenAI o1 érvelési modelljétől. Ráadásul teljesen ingyenes és nyílt forráskódú, ami közvetlenül iparági földrengést váltott ki.
Ez az első alkalom, hogy egy hazai mesterséges intelligencia világszerte, különösen az Egyesült Államokban, nagy port kavart a technológiai világban. A fejlesztők úgy nyilatkoztak, hogy fontolgatják, hogy a DeepSeek segítségével "mindent újjáépítenek". Ennek a hullámnak a nyomán, egy hét erjedés után, sőt, még csak januárban jelent meg, a DeepSeek mobilalkalmazás gyorsan az ingyenes alkalmazások rangsorának élére került az Apple App Store-ban az Egyesült Államokban, megelőzve nemcsak a ChatGPT-t, hanem más népszerű alkalmazásokat is az USA-ban.
A DeepSeek sikere még az amerikai tőzsdére is közvetlen hatással volt. A rengeteg drága GPU felhasználása nélkül képzett modell arra késztette az embereket, hogy újragondolják a mesterséges intelligencia képzési útját, ami közvetlenül a legnagyobb, 17%-os esést okozta a mesterséges intelligencia első részvényében, az NVIDIA-ban.
És ez még nem minden.
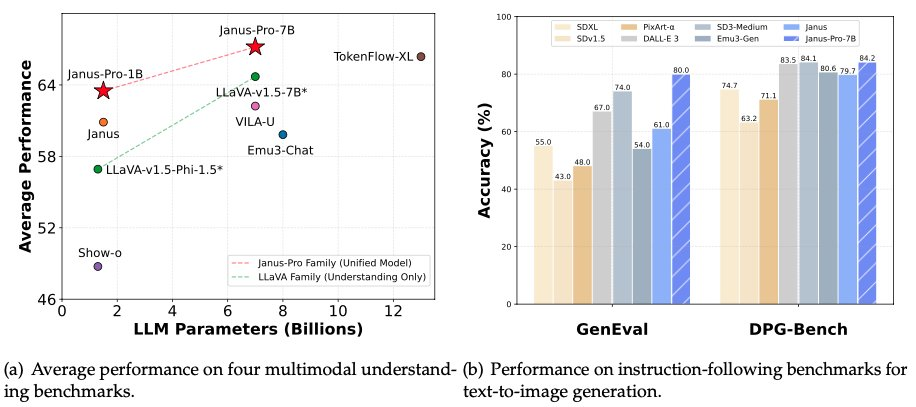
Január 28-án, a szilveszter előtti éjszakán a DeepSeek ismét megnyitotta az Janus-Pro-7B multimodális modelljének forrását, és bejelentette, hogy a GenEval és a DPG-Bench benchmark teszteken legyőzte a DALL-E 3-at (az OpenAI-tól) és a Stable Diffusiont.
A DeepSeek tényleg le fogja söpörni a mesterséges intelligencia közösséget? A következtetési modellektől a multimodális modellekig, a DeepSeek mindent átstrukturál a Kígyó évének első témája?
Janus Pro, egy innovatív multimodális modellarchitektúra validálása
A DeepSeek ezúttal késő este összesen két modellt adott ki: Janus-Pro-7B és Janus-Pro-1B (1,5B paraméterekkel).
Ahogy a neve is mutatja, maga a modell a korábbi Janus modell továbbfejlesztése.
A DeepSeek csak 2024 októberében adta ki először a Janus modellt. A DeepSeek-től megszokott módon a modell innovatív architektúrát alkalmaz. Számos látásgeneráló modellben a modell egy egységes Transformer-architektúrát alkalmaz, amely egyszerre képes feldolgozni a szövegből képbe és a képből szövegbe feladatokat.
A DeepSeek egy új ötletet javasol, a megértési (gráf-szöveg) és a generálási feladatok (szöveg-gráf) vizuális kódolásának szétválasztását, ami javítja a modellképzés rugalmasságát, és hatékonyan enyhíti az egyetlen vizuális kódolás használata által okozott konfliktusokat és teljesítménybeli szűk keresztmetszeteket.
Ezért nevezte el a DeepSeek a modellt Janusnak. Janus az ajtók ókori római istene, akit két, ellentétes irányba néző arccal ábrázolnak. A DeepSeek szerint a modell azért kapta a Janus nevet, mert képes különböző szemekkel vizuális adatokat nézni, külön-külön kódolni a jellemzőket, majd ugyanazt a testet (Transformer) használni a bemeneti jelek feldolgozására.
Ez az új ötlet jó eredményeket hozott a Janus modellsorozatban. A csapat szerint a Janus modell erős parancskövetési képességekkel, többnyelvűséggel rendelkezik, és a modell okosabb, képes mémképeket olvasni. Olyan feladatokat is képes kezelni, mint a latex képletek konvertálása és a grafikonok kóddá alakítása.
Az Janus Pro modellsorozatban a csapat részben módosította a modell képzési folyamatát, amivel közvetlenül olyan eredményeket ért el, amelyek a GenEval és a DPG-Bench benchmark teszteken felülmúlták a DALL-E 3-at és a Stable Diffusiont.
Magával a modellel együtt a DeepSeek kiadta az új multimodális mesterséges intelligencia keretrendszert, a Janus Flow-t is, amelynek célja a képmegértési és képgenerálási feladatok egységesítése.
Az Janus Pro modell stabilabb kimenetet tud nyújtani rövid utasítások használatával, jobb vizuális minőséggel, gazdagabb részletekkel és egyszerűbb szöveg generálásának képességével.
A modell képes képeket generálni és képeket leírni, nevezetességeket azonosítani (például Hangzhou nyugati tavát), szöveget felismerni a képeken, és ismereteket leírni a képeken (például a "Tom és Jerry" süteményeket).
One x.com, Sokan már elkezdtek kísérletezni az új modellel.

A fenti ábrán balra a képfelismerési teszt, míg jobbra a képgenerálási teszt látható.

Amint látható, az Janus Pro a képek nagy pontosságú leolvasásában is jó munkát végez. Felismeri a matematikai kifejezések és a szöveg vegyes betűkészletét. A jövőben nagyobb jelentősége lehet annak, hogy érvelési modellel együtt használjuk.
Az 1B és a 7B paraméterei új alkalmazási forgatókönyveket nyithatnak meg.
A multimodális megértési feladatokban az új Janus-Pro modell SigLIP-L-t használ vizuális kódolóként, és 384 x 384 képpont méretű képeket támogat. A képgenerálási feladatokban az Janus-Pro egy adott forrásból származó, 16-os lemintavételi sebességű tokenizálót használ.
Ez még mindig viszonylag kis képméret. X A felhasználó elemzésénél az Janus Pro modell inkább irányított ellenőrzés. Ha az ellenőrzés megbízható, akkor egy gyártásba vehető modell kerül kiadásra.
Érdemes azonban megjegyezni, hogy a Janus által ezúttal kiadott új modell nem csak architekturálisan innovatív a multimodális modellekhez képest, hanem a paraméterek számát tekintve is új felfedezés.
A DeepSeek Janus Pro által ezúttal összehasonlított modell, a DALL-E 3 korábban bejelentette, hogy 12 milliárd paraméterrel rendelkezik, míg az Janus Pro nagyméretű modellje csak 7 milliárd paraméterrel. Ilyen kompakt méret mellett már az is nagyon jó, hogy az Janus Pro ilyen eredményeket tud elérni.
Az Janus Pro 1B modellje mindössze 1,5 milliárd paramétert használ. A felhasználók már hozzáadták a modell támogatását a transformers.js külső hálózathoz. Ez azt jelenti, hogy a modell mostantól az 100% böngészőkben WebGPU-n is futtatható!
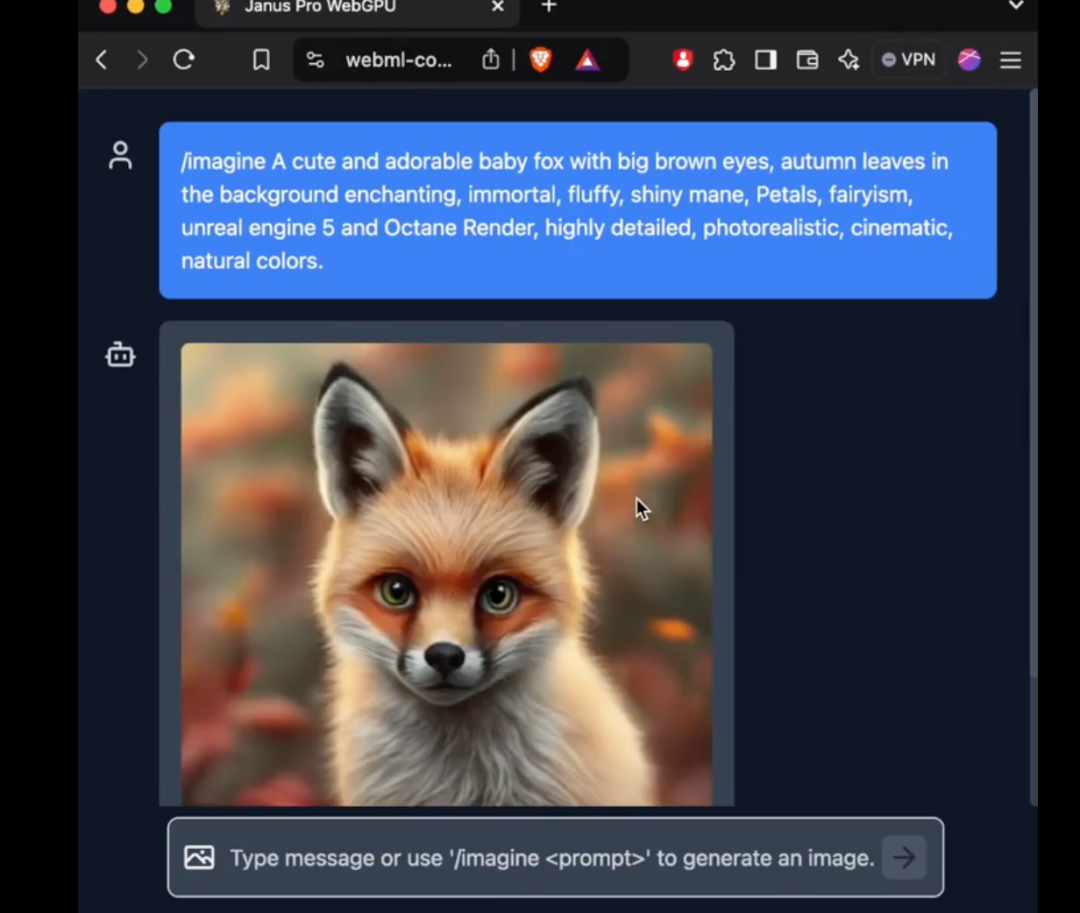
Bár a sajtó időpontjáig a szerző még nem tudta sikeresen használni az Janus Pro új modelljét a webes változaton, az a tény, hogy a paraméterek száma elég kicsi ahhoz, hogy közvetlenül a webes oldalon fusson, mégis elképesztő előrelépés.
Ez azt jelenti, hogy a képalkotás/képmegértés költségei folyamatosan csökkennek. Lehetőségünk nyílik arra, hogy a mesterséges intelligenciát egyre több olyan helyen használjuk, ahol korábban nem lehetett nyers képeket és képmegértést alkalmazni, ami megváltoztatja az életünket.
A 2024-es év egyik fő forró pontja az, hogy a multimodális megértéssel kiegészített mesterséges intelligencia hardverek hogyan avatkozhatnak be az életünkbe. Az egyre alacsonyabb paraméterekkel rendelkező multimodális megértési modellek, illetve a várhatóan a határon futó modellek lehetővé tehetik az AI hardverek további robbanását.
A DeepSeek felkavarta az új évet. Vajon mindent újra lehet csinálni a kínai mesterséges intelligenciával?
A mesterséges intelligencia világa napról napra változik.
A tavalyi tavaszi fesztivál környékén az OpenAI Sora modellje kavarta fel a világot. Az év folyamán azonban a kínai cégek teljesen felzárkóztak a videók készítése terén, így a Sora év végi megjelenése kissé kilátástalannak tűnik.
Idén, ami felkavarta a világot, az a kínai DeepSeek lett.
A DeepSeek nem egy hagyományos technológiai vállalat, de rendkívül innovatív modelleket készített a nagy amerikai modellgyártó cégek GPU-kártyáinál jóval alacsonyabb áron, ami közvetlenül sokkolta az amerikai partnereket. Az amerikaiak felkiáltottak: "Az R1 modell kiképzése mindössze 5,6 millió dollárba került, ami még a Meta GenAI csapat bármelyik vezetőjének fizetésével is egyenértékű. Mi ez a titokzatos keleti hatalom?"
A DeepSeek alapítóját, Liang Wenfenget utánzó paródiafiók egy érdekes képet tett közzé közvetlenül az X-en:

A képen a világhírű török lövő 2024-es trendi mémjét használták fel.
A párizsi olimpia lövészversenyeinek 10 méteres légpisztolyos döntőjében az 51 éves török lövész, Mithat Dikec, aki csak egy közönséges rövidlátó szemüveget és egy pár alvó füldugót viselt, nyugodtan, egy kézzel a zsebében zsebelte be az ezüstérmet. Az összes többi jelenlévő lövésznek két professzionális szemüveglencsére volt szüksége a fókuszáláshoz és fényzáráshoz, valamint egy pár zajszűrő füldugóra, hogy elindulhasson a versenyen.
Mivel a DeepSeek "feltörte" Az OpenAI érvelési modellje, a nagy amerikai technológiai vállalatokra nagy nyomás nehezedik. Ma Sam Altman végre hivatalos nyilatkozatban reagált.

Vajon 2025 lesz az az év, amikor a kínai mesterséges intelligencia hatással lesz az amerikai felfogásra?
A DeepSeek még mindig tartogat néhány titkot a tarsolyában - ez egy rendkívüli tavaszi fesztiválnak ígérkezik.




