
Ⅰ. Apa yang dimaksud dengan penyulingan pengetahuan?
Penyulingan pengetahuan adalah teknik kompresi model yang digunakan untuk mentransfer pengetahuan dari model yang besar dan kompleks (model guru) ke model yang kecil (model siswa).
Prinsip intinya adalah bahwa model guru mengajarkan model siswa dengan memprediksi hasil (seperti distribusi probabilitas atau proses inferensi), dan model siswa meningkatkan kinerjanya dengan belajar dari prediksi ini.
Metode ini khususnya cocok untuk perangkat dengan sumber daya terbatas, seperti ponsel atau perangkat yang disematkan.
II. konsep inti
2.1 Desain templat
- Template: Format terstruktur yang digunakan untuk menstandarkan keluaran model. Sebagai contoh
- : Menandai awal proses penalaran.
- : Menandai akhir dari proses penalaran.
- : Menandai awal dari jawaban akhir.
- : Menandai akhir dari jawaban akhir.
- Fungsi:
- Kejelasan: Seperti "kata-kata yang diminta" dalam pertanyaan isian, pertanyaan ini memberi tahu model "proses berpikir di sini, dan jawabannya di sana."
- Konsistensi: Memastikan bahwa semua output mengikuti struktur yang sama, sehingga memudahkan pemrosesan dan analisis selanjutnya.
- Keterbacaan: Manusia dapat dengan mudah membedakan antara proses penalaran dan jawabannya, sehingga meningkatkan pengalaman pengguna.
2.2 Lintasan penalaran: "Rantai pemikiran" dari solusi model
- Lintasan penalaran: Langkah-langkah terperinci yang dihasilkan oleh model ketika memecahkan masalah menunjukkan rantai logis dari model.
- Contoh:
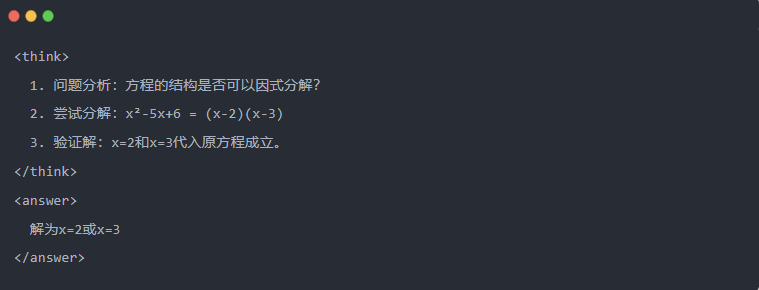
2.3 Pengambilan sampel penolakan: Menyaring data yang baik dari 'coba-coba'
- Pengambilan sampel penolakan: Menghasilkan beberapa kandidat jawaban dan mempertahankan jawaban yang baik, mirip dengan menulis draf dan kemudian menyalin jawaban yang benar dalam ujian.
Ⅲ. Pembuatan data yang disaring
Langkah pertama dalam penyulingan pengetahuan adalah menghasilkan 'data pengajaran' berkualitas tinggi untuk dipelajari oleh model-model kecil.
Sumber data:
- 80% dari data penalaran yang dihasilkan oleh DeepSeek-R1
- 20% dari data tugas umum DeepSeek-V3.
Proses pembuatan data distilasi:
- Pemfilteran aturansecara otomatis memeriksa kebenaran jawaban (misalnya apakah jawaban matematis sesuai dengan rumus).
- Pemeriksaan keterbacaanmenghilangkan bahasa campuran (misalnya campuran bahasa Mandarin dan Inggris) atau paragraf yang panjang.
- Pembuatan yang dipandu templatmembutuhkan DeepSeek-R1 untuk menghasilkan lintasan inferensi sesuai dengan template.
- Pemfilteran pengambilan sampel penolakan:
- Integrasi data: 800.000 sampel berkualitas tinggi akhirnya dihasilkan, termasuk sekitar 600.000 data inferensi dan sekitar 200.000 data umum.
Proses penyulingan
Peran guru dan siswa:
- DeepSeek-R1 sebagai model guru;
- Model seri Qwen sebagai model siswa.
Langkah-langkah pelatihan:
Pertama, input data: Anda perlu memasukkan bagian pertanyaan dari 800.000 sampel ke dalam model Qwen dan memintanya untuk membuat lintasan inferensi (proses berpikir + jawaban) yang lengkap sesuai dengan templatnya. Ini adalah langkah yang sangat penting
Selanjutnya, perhitungan kerugian: bandingkan output yang dihasilkan oleh model siswa dengan lintasan inferensi model guru, dan selaraskan urutan teks melalui supervised fine-tuning (SFT). Jika Anda tidak yakin apa itu SFT, saya harap Anda mencari kata kunci ini untuk mempelajari lebih lanjut
Selesaikan pembaruan parameter untuk model siswa yang lebih besar: Optimalkan parameter model Qwen melalui backpropagation untuk memperkirakan keluaran model guru.
Mengulangi proses pelatihan ini beberapa kali untuk memastikan bahwa pengetahuan telah ditransfer secara memadai. Hal ini akan mencapai tujuan awal pelatihan. Kami akan memberikan contoh untuk mendemonstrasikan hal ini, dan kami harap Anda dapat memahaminya
Ⅴ. Contoh demonstrasi
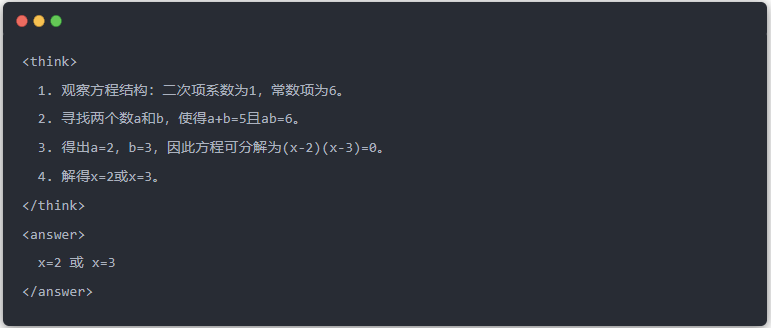
Artikel ini mendemonstrasikan efek distilasi melalui tugas pemecahan persamaan tertentu (menyelesaikan persamaan):
- Keluaran standar dari model guru:
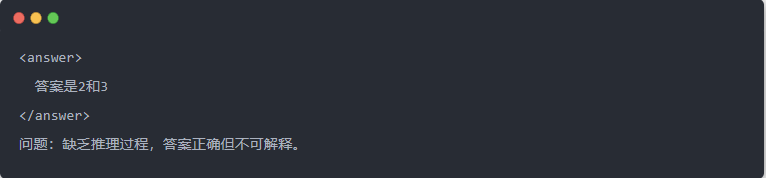
- Keluaran Qwen-7B sebelum distilasi:
- Keluaran Qwen-7B setelah distilasi:
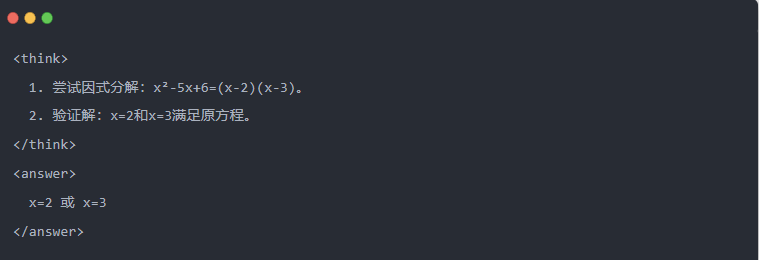
- Solusi yang dioptimalkan: Proses inferensi terstruktur dihasilkan, dan jawabannya sama dengan model guru.
Ⅵ. Ringkasan
Melalui penyulingan pengetahuan, kemampuan inferensi DeepSeek-R1 dimigrasikan secara efisien ke rangkaian model kecil Qwen. Proses ini berfokus pada keluaran templated dan pengambilan sampel penolakan. Melalui pembuatan data terstruktur dan pelatihan yang disempurnakan, model kecil juga dapat melakukan tugas inferensi yang kompleks dalam skenario dengan sumber daya terbatas. Teknologi ini memberikan referensi penting untuk penerapan model AI yang ringan.



