DeepSeek telah memperbarui situs webnya.
Pada dini hari di Malam Tahun Baru, DeepSeek tiba-tiba mengumumkan di GitHub bahwa ruang proyek Janus telah membuka sumber model dan laporan teknis Janus-Pro.
Pertama, mari kita soroti beberapa poin penting:
- The Model Janus-Pro yang dirilis kali ini adalah model multimodal yang secara bersamaan dapat melakukan tugas pemahaman multimodal dan pembuatan gambar. Memiliki total dua versi parameter, Janus-Pro-1B dan Janus-Pro-7B.
- Inovasi inti dari Janus-Pro adalah memisahkan pemahaman dan pembangkitan multimodal, dua tugas yang berbeda. Hal ini memungkinkan kedua tugas ini diselesaikan secara efisien dalam model yang sama.
- Janus-Pro konsisten dengan arsitektur model Janus yang dirilis oleh DeepSeek pada bulan Oktober lalu, tetapi pada saat itu Janus tidak memiliki banyak volume. Charles, seorang ahli algoritma di bidang penglihatan, mengatakan kepada kami bahwa Janus sebelumnya "biasa saja" dan "tidak sebagus model bahasa DeepSeek".

Hal ini dimaksudkan untuk memecahkan masalah yang sulit dalam industri ini: menyeimbangkan pemahaman multimodal dan pembuatan gambar
Menurut perkenalan resmi DeepSeek, Janus-Pro tidak hanya dapat memahami gambar, mengekstrak dan memahami teks dalam gambar, tetapi juga menghasilkan gambar pada saat yang bersamaan.
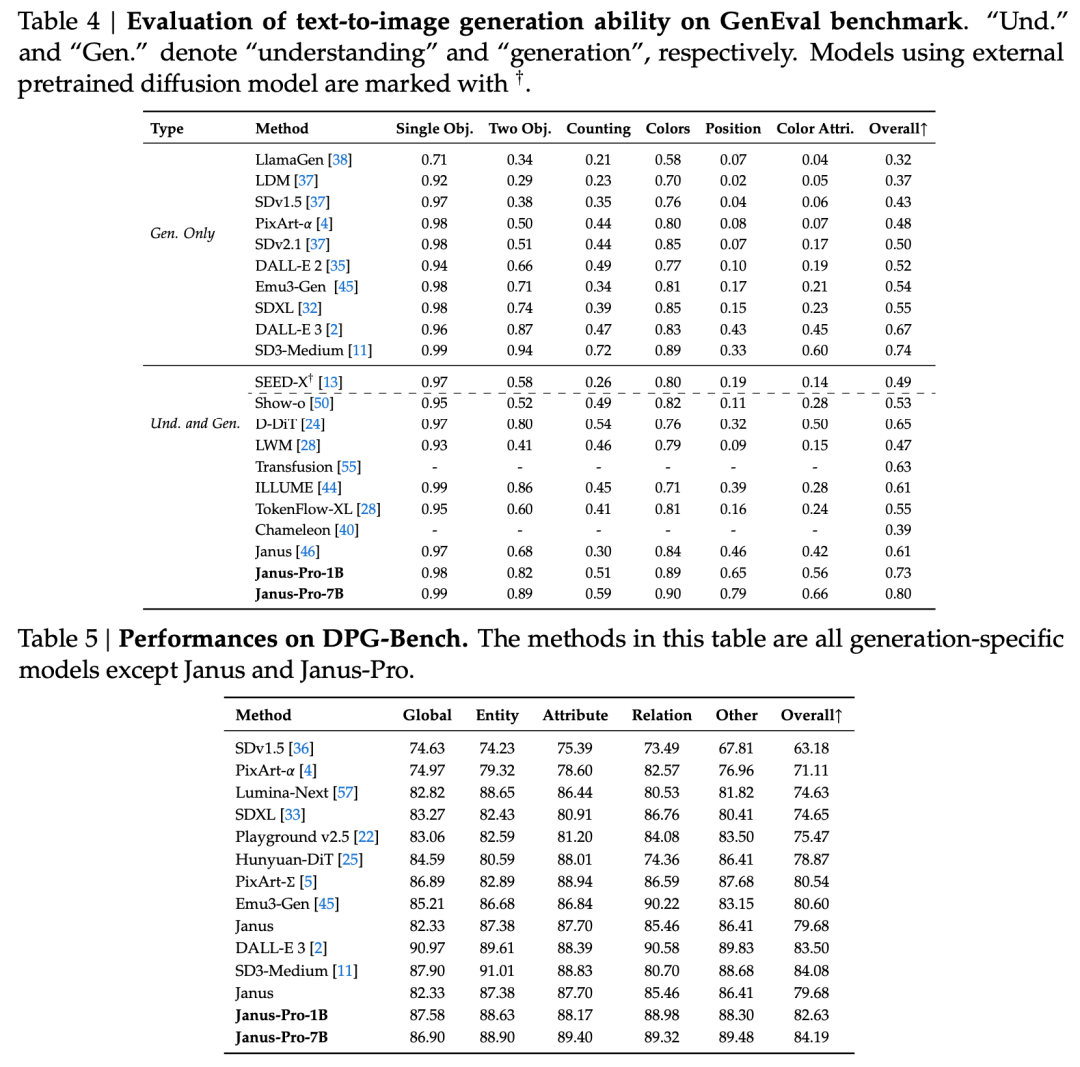
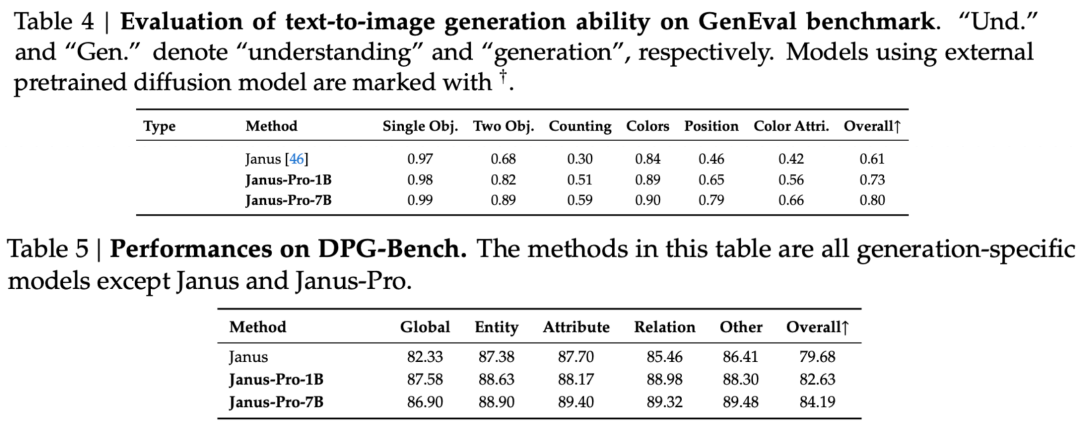
Laporan teknis menyebutkan bahwa dibandingkan dengan model lain dengan tipe dan urutan yang sama, skor Janus-Pro-7B pada perangkat uji GenEval dan DPG-Bench melebihi model lain seperti SD3-Medium dan DALL-E 3.
Pejabat tersebut juga memberikan contoh 👇:
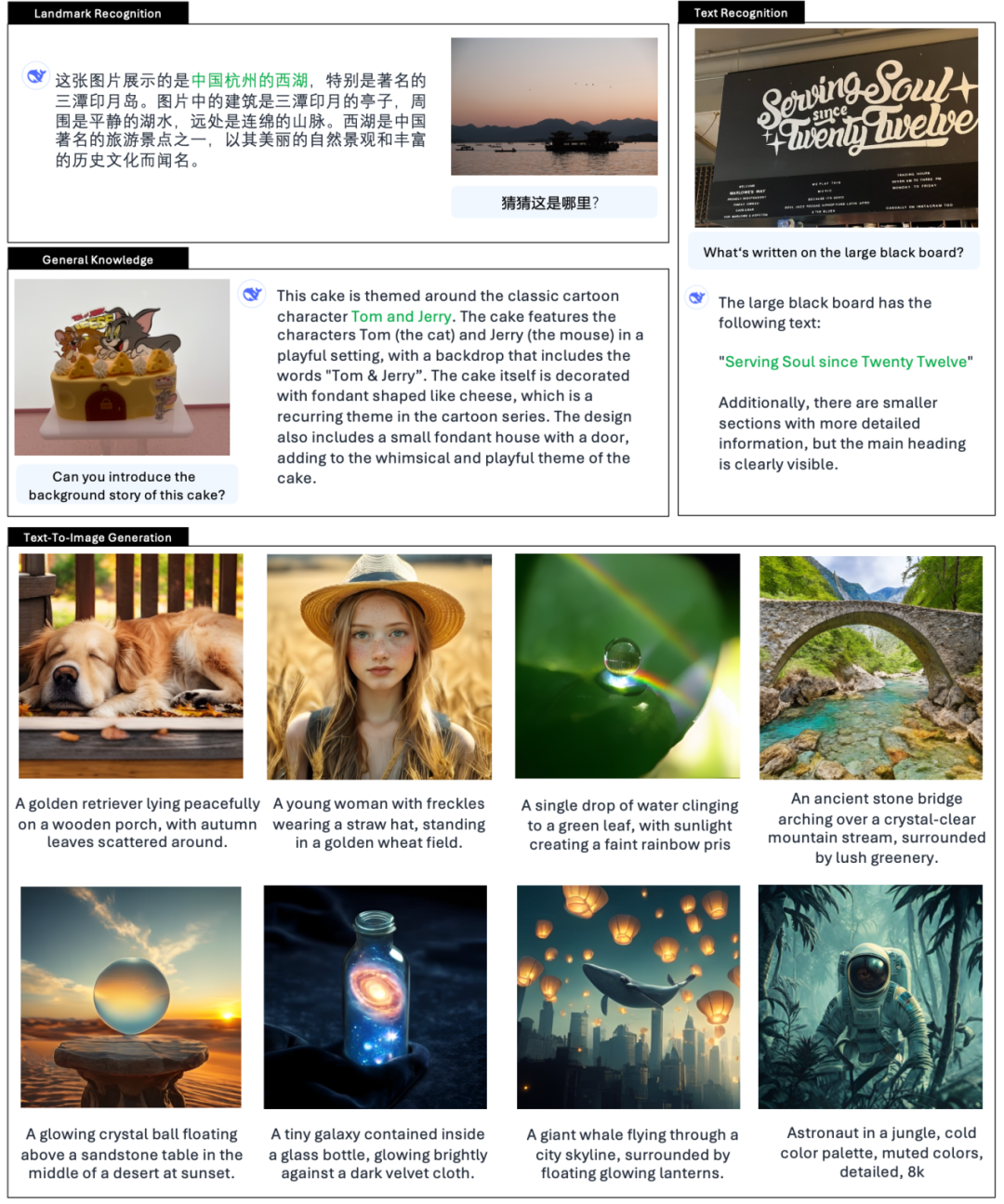
Banyak juga netizen di X yang mencoba fitur-fitur baru ini.

Tetapi ada juga yang sesekali mengalami crash.
Dengan membaca makalah teknis tentang DeepSeekkami menemukan bahwa Janus Pro merupakan optimasi yang didasarkan pada Janus, yang dirilis tiga bulan yang lalu.
Inovasi inti dari rangkaian model ini adalah untuk memisahkan tugas pemahaman visual dari tugas pembuatan visual, sehingga efek dari kedua tugas tersebut dapat diseimbangkan.
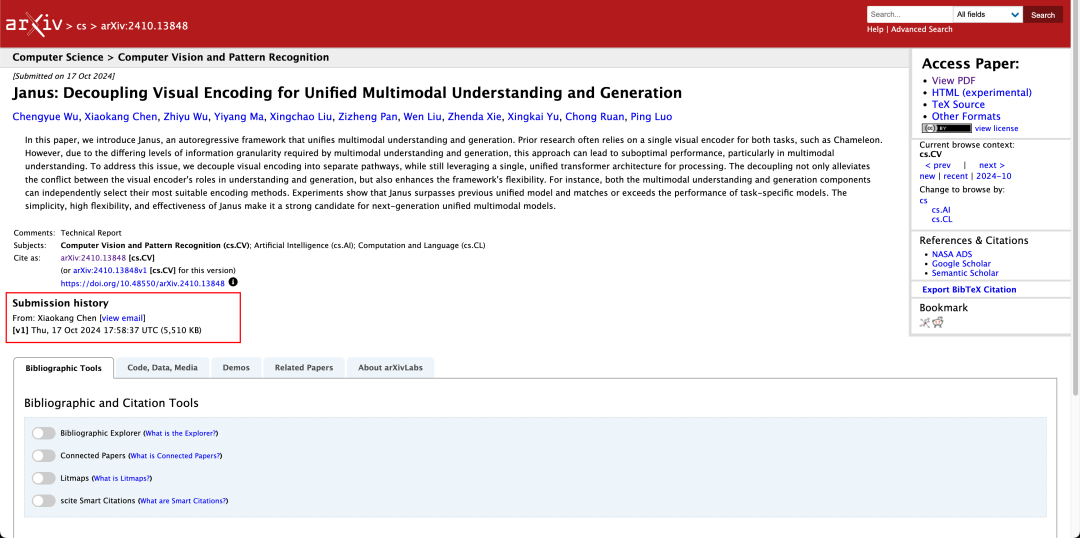
Tidak jarang sebuah model dapat melakukan pemahaman dan pembangkitan multimodal secara bersamaan. D-DiT dan TokenFlow-XL dalam rangkaian pengujian ini memiliki kemampuan ini.
Namun, yang menjadi ciri khas dari Janus adalah dengan pemrosesan decoupling, sebuah model yang dapat melakukan pemahaman dan pembangkitan multimodal menyeimbangkan keefektifan kedua tugas tersebut.
Menyeimbangkan efektivitas kedua tugas tersebut adalah masalah yang sulit dalam industri ini. Sebelumnya, pemikirannya adalah menggunakan encoder yang sama untuk mengimplementasikan pemahaman dan pembangkitan multimodal sebanyak mungkin.
Keuntungan dari pendekatan ini adalah arsitektur yang sederhana, tidak ada penerapan yang berlebihan, dan keselarasan dengan model teks (yang juga menggunakan metode yang sama untuk mencapai pembuatan teks dan pemahaman teks). Argumen lainnya adalah bahwa perpaduan beberapa kemampuan ini dapat mengarah pada tingkat kemunculan tertentu.
Namun demikian, pada kenyataannya, setelah memadukan pembuatan dan pemahaman, kedua tugas tersebut akan bertentangan - pemahaman gambar memerlukan model untuk mengabstraksikan dalam dimensi tinggi dan mengekstrak semantik inti gambar, yang bias ke arah makroskopis. Sebaliknya, pembangkitan gambar berfokus pada ekspresi dan pembangkitan detail lokal pada tingkat piksel.
Praktik yang biasa dilakukan oleh industri ini adalah memprioritaskan kemampuan menghasilkan gambar. Hal ini menghasilkan model multimodal yang dapat menghasilkan gambar berkualitas lebih tinggi, tetapi hasil pemahaman gambar sering kali biasa-biasa saja.
Arsitektur terpisah Janus dan strategi pelatihan yang dioptimalkan Janus-Pro
Arsitektur terpisah Janus memungkinkan model untuk menyeimbangkan tugas memahami dan menghasilkan sendiri.
Menurut hasil dalam laporan teknis resmi, apakah itu pemahaman multimodal atau pembangkitan gambar, Janus-Pro-7B berkinerja baik pada beberapa set pengujian.

Untuk pemahaman multimodal, Janus-Pro-7B meraih posisi pertama di empat dari tujuh set data evaluasi, dan posisi kedua di tiga set data lainnya, sedikit di belakang model yang berada di peringkat teratas.
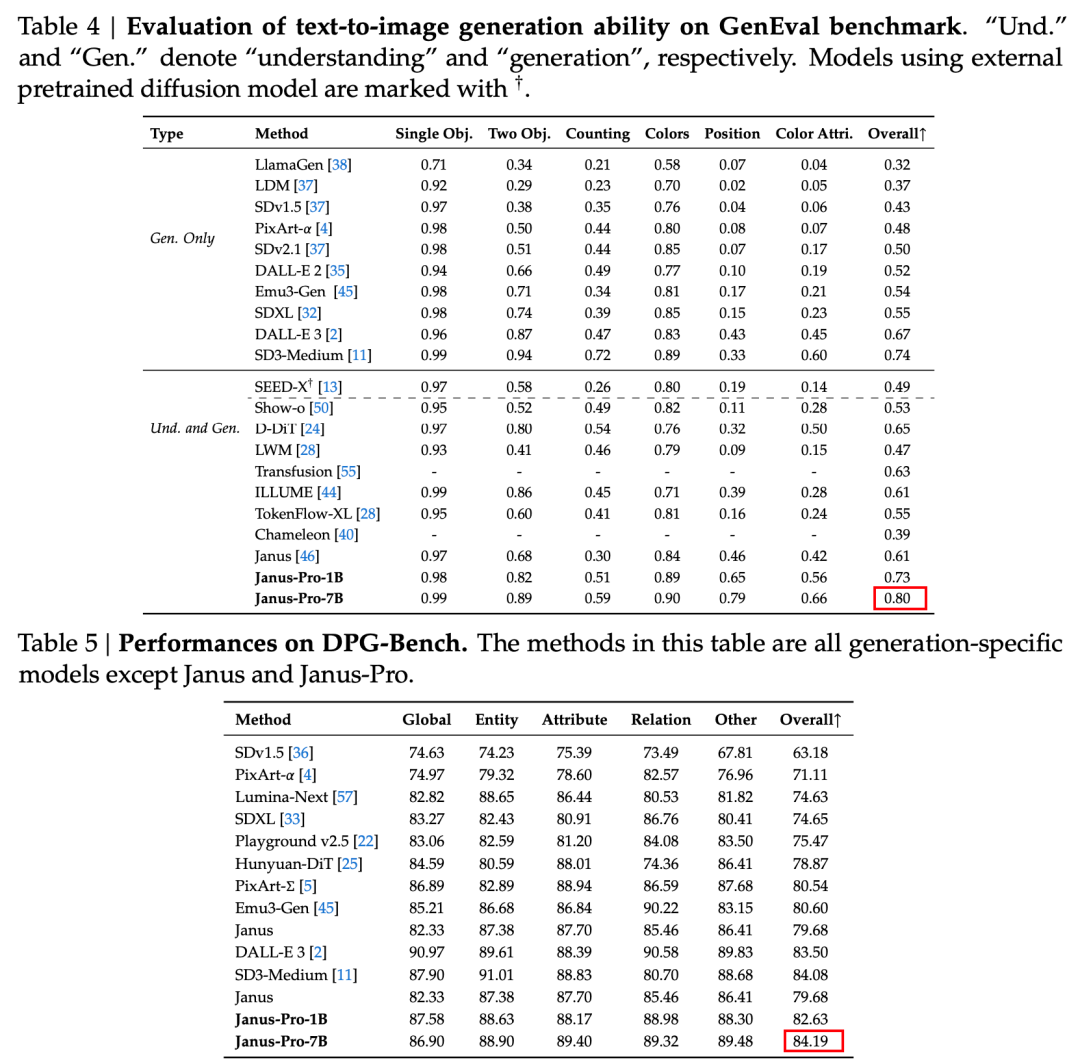
Untuk menghasilkan gambar, Janus-Pro-7B meraih peringkat pertama dalam skor keseluruhan pada dataset evaluasi GenEval dan DPG-Bench.
Efek multi-tasking ini terutama disebabkan oleh penggunaan dua penyandi visual untuk tugas yang berbeda pada seri Janus:
- Memahami encoder: digunakan untuk mengekstrak fitur semantik dalam gambar untuk tugas pemahaman gambar (seperti pertanyaan dan jawaban gambar, klasifikasi visual, dll.).
- Encoder generatif: mengonversi gambar menjadi representasi diskrit (misalnya, menggunakan encoder VQ) untuk tugas pembuatan teks-ke-gambar.
Dengan arsitektur ini, model ini dapat secara independen mengoptimalkan kinerja setiap encoder, sehingga pemahaman multimodal dan tugas pembangkitan masing-masing dapat mencapai kinerja terbaiknya.
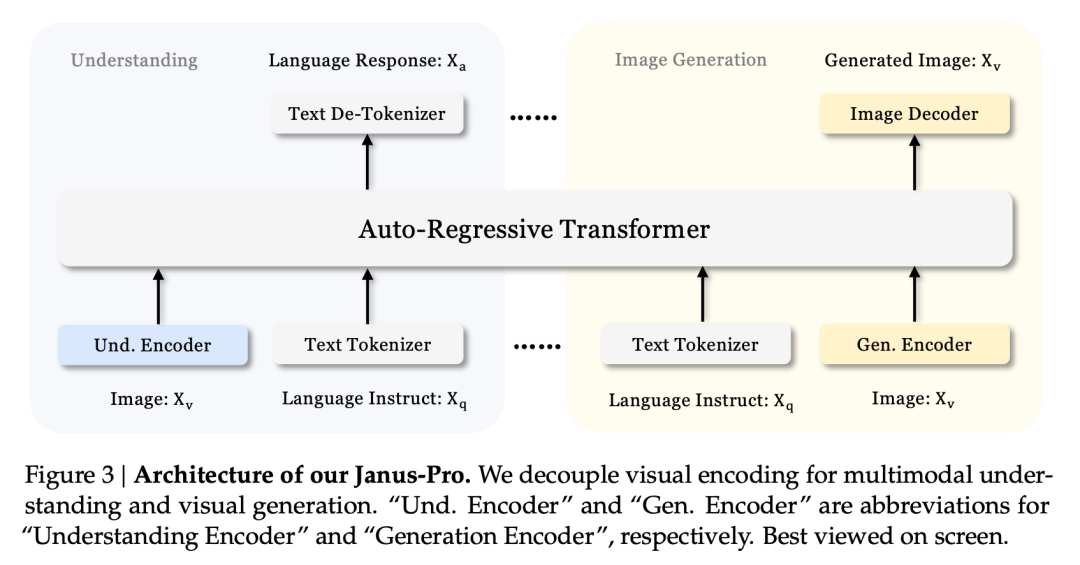
Arsitektur terpisah ini adalah hal yang umum pada Janus-Pro dan Janus. Jadi, iterasi apa saja yang telah dilakukan Janus-Pro dalam beberapa bulan terakhir?
Seperti yang dapat dilihat dari hasil set evaluasi, rilis Janus-Pro-1B saat ini memiliki peningkatan sekitar 10% hingga 20% dalam skor set evaluasi yang berbeda dibandingkan dengan Janus sebelumnya. Janus-Pro-7B memiliki peningkatan tertinggi sekitar 45% dibandingkan dengan Janus setelah memperluas jumlah parameter.

Dalam hal detail pelatihan, laporan teknis menyatakan bahwa rilis Janus-Pro saat ini, dibandingkan dengan model Janus sebelumnya, mempertahankan desain arsitektur inti yang terpisah, dan juga mengulang pada ukuran parameter, strategi pelatihan, dan data pelatihan.
Pertama, mari kita lihat parameternya.
Versi pertama Janus hanya memiliki parameter 1,3B, dan rilis Pro saat ini menyertakan model dengan parameter 1B dan 7B.
Kedua ukuran ini mencerminkan skalabilitas arsitektur Janus. Model 1B, yang paling ringan, telah digunakan oleh pengguna eksternal untuk berjalan di browser menggunakan WebGPU.
Ada juga yang strategi pelatihan.
Sejalan dengan pembagian fase pelatihan Janus, Janus Pro memiliki total tiga fase pelatihan, dan makalah ini secara langsung membaginya menjadi Tahap I, Tahap II, dan Tahap III.
Dengan tetap mempertahankan ide dasar pelatihan dan tujuan pelatihan dari setiap tahap, Janus-Pro telah melakukan perbaikan pada durasi pelatihan dan data pelatihan dalam ketiga tahap tersebut. Berikut ini adalah perbaikan spesifik dalam ketiga tahap tersebut:
Tahap I - Waktu pelatihan yang lebih lama
Dibandingkan dengan Janus, Janus-Pro telah memperpanjang waktu pelatihan pada Tahap I, khususnya dalam pelatihan adaptor dan kepala gambar di bagian visual. Ini berarti, bahwa pembelajaran fitur visual telah diberikan lebih banyak waktu pelatihan, dan diharapkan model dapat sepenuhnya memahami fitur detail gambar (seperti pemetaan piksel-ke-semantik).
Pelatihan yang diperpanjang ini membantu memastikan bahwa pelatihan bagian visual tidak terganggu oleh modul lainnya.
Tahap II - Menghapus data ImageNet dan menambahkan data multi-modal
Pada Tahap II, Janus sebelumnya mereferensikan PixArt dan dilatih dalam dua bagian. Bagian pertama dilatih menggunakan kumpulan data ImageNet untuk tugas klasifikasi gambar, dan bagian kedua dilatih menggunakan data teks-ke-gambar biasa. Sekitar dua pertiga dari waktu di Tahap II dihabiskan untuk melatih bagian pertama.
Janus-Pro menghapus pelatihan ImageNet di Tahap II. Desain ini memungkinkan model untuk fokus pada data teks-ke-gambar selama pelatihan Tahap II. Menurut hasil eksperimen, hal ini dapat secara signifikan meningkatkan pemanfaatan data teks-ke-gambar.
Selain penyesuaian desain metode pelatihan, set data pelatihan yang digunakan pada Tahap II tidak lagi terbatas pada tugas klasifikasi gambar tunggal, tetapi juga mencakup lebih banyak jenis data multimodal lainnya, seperti deskripsi gambar dan dialog, untuk pelatihan bersama.
Tahap III - Mengoptimalkan rasio data
Pada pelatihan Tahap III, Janus-Pro menyesuaikan rasio berbagai jenis data pelatihan.
Sebelumnya, rasio data pemahaman multimodal, data teks biasa, dan data teks-ke-gambar dalam data pelatihan yang digunakan oleh Janus pada Tahap III adalah 7:3:10. Janus-Pro mengurangi rasio dua jenis data terakhir dan menyesuaikan rasio ketiga jenis data tersebut menjadi 5:1:4, yaitu lebih memperhatikan tugas pemahaman multimodal.
Mari kita lihat data pelatihan.
Dibandingkan dengan Janus, Janus-Pro kali ini secara signifikan meningkatkan jumlah kualitas tinggi data sintetis.
Ini memperluas jumlah dan variasi data pelatihan untuk pemahaman multimodal dan pembuatan gambar.
Perluasan data pemahaman multimodal:
Janus-Pro mengacu pada dataset DeepSeek-VL2 selama pelatihan dan menambahkan sekitar 90 juta titik data tambahan, termasuk tidak hanya dataset deskripsi gambar, tetapi juga dataset adegan yang kompleks seperti tabel, bagan, dan dokumen.
Selama tahap penyempurnaan yang diawasi (Tahap III), terus menambahkan set data yang terkait dengan pemahaman MEME dan peningkatan pengalaman dialog (termasuk dialog bahasa Mandarin).
Perluasan data generasi visual:
Data asli dunia nyata memiliki kualitas yang buruk dan tingkat noise yang tinggi, yang menyebabkan model menghasilkan output yang tidak stabil dan gambar dengan kualitas estetika yang tidak memadai dalam tugas teks-ke-gambar.
Janus-Pro menambahkan sekitar 72 juta data sintetis estetika tinggi yang baru ke dalam fase pelatihan, sehingga rasio data nyata dan data sintetis pada fase pra-pelatihan menjadi 1:1.
Petunjuk untuk data sintetis semuanya diambil dari sumber daya publik. Eksperimen telah menunjukkan bahwa penambahan data ini membuat model lebih cepat menyatu, dan gambar yang dihasilkan memiliki peningkatan yang nyata dalam stabilitas dan keindahan visual.
Kelanjutan dari revolusi efisiensi?
Secara keseluruhan, dengan rilis ini, DeepSeek telah membawa revolusi efisiensi ke model visual.
Tidak seperti model visual yang berfokus pada fungsi tunggal atau model multimodal yang mendukung tugas tertentu, Janus-Pro menyeimbangkan efek dari dua tugas utama, yaitu pembuatan gambar dan pemahaman multimodal dalam model yang sama.
Selain itu, meskipun parameternya kecil, namun mampu mengalahkanOpenAI DALL-E 3 dan SD3-Medium dalam evaluasi.
Diperluas ke lapangan, perusahaan hanya perlu menggunakan model untuk secara langsung mengimplementasikan dua fungsi pembuatan dan pemahaman gambar. Ditambah dengan ukuran yang hanya 7B, kesulitan dan biaya penerapan menjadi jauh lebih rendah.
Sehubungan dengan rilis R1 dan V3 sebelumnya, DeepSeek menantang aturan main yang ada dengan "inovasi arsitektur yang ringkas, model yang ringan, model sumber terbuka, dan biaya pelatihan yang sangat rendah". Inilah alasan kepanikan di antara raksasa teknologi Barat dan bahkan Wall Street.
Baru saja, Sam Altman, yang selama beberapa hari ini terseret oleh opini publik, akhirnya merespon positif informasi mengenai DeepSeek di X. Sembari memuji R1, ia mengatakan bahwa OpenAI akan membuat beberapa pengumuman.