

Sorotan Utama
🔹 Arsitektur Trafo Terpadu: Model tunggal menangani kedua pemahaman gambar dan generasi, sehingga tidak memerlukan sistem yang terpisah.
🔹 Dapat diskalakan & Sumber Terbuka: Tersedia dalam 1B dan 7B versi parameter (berlisensi MIT), dioptimalkan untuk beragam aplikasi dan penggunaan komersial.
🔹 Pertunjukan Seni Mutakhir: Mengungguli DALL-E 3 dan Stable Diffusion dari OpenAI dalam benchmark seperti GenEval dan DPG-Bench.
🔹 Penerapan yang Disederhanakan: Arsitektur yang ramping mengurangi biaya pelatihan/penyimpulan sekaligus mempertahankan fleksibilitas.
Tautan Model
- Janus-Pro-7B: HuggingFace
- Janus-Pro-1B: HuggingFace
- GitHub: Kode & Dokumen
Mengapa Janus-Pro Menonjol
1. Kekuatan Super Ganda dalam Satu Model
- Memahami Mode: Penggunaan SigLIP-L ("kacamata super") untuk menganalisis gambar (hingga 384×384) dan teks.
- Mode Generasi: Leverage Aliran yang Diperbaiki + SDXL-VAE ("kuas ajaib") untuk menciptakan gambar berkualitas tinggi.
2. Kekuatan Otak & Pelatihan
- Inti LLM: Dibangun di atas model bahasa DeepSeek yang kuat (parameter 1,5B/7B), unggul dalam penalaran kontekstual.
- Jalur Pelatihan: Pra-pelatihan pada dataset yang sangat besar → Penyempurnaan yang diawasi → Optimalisasi EMA untuk kinerja puncak.
3. Mengapa Transformasi Dibanding Difusi?
- Keserbagunaan Tugas: Memprioritaskan pemahaman + generasi terpadu, sedangkan model difusi hanya berfokus pada kualitas gambar.
- Efisiensi: Pembangkitan autoregresif (satu langkah) vs. denoising iteratif difusi (misalnya, 20 langkah untuk Difusi Stabil).
- Efektivitas Biaya: Satu tulang punggung Transformer menyederhanakan pelatihan dan penerapan.
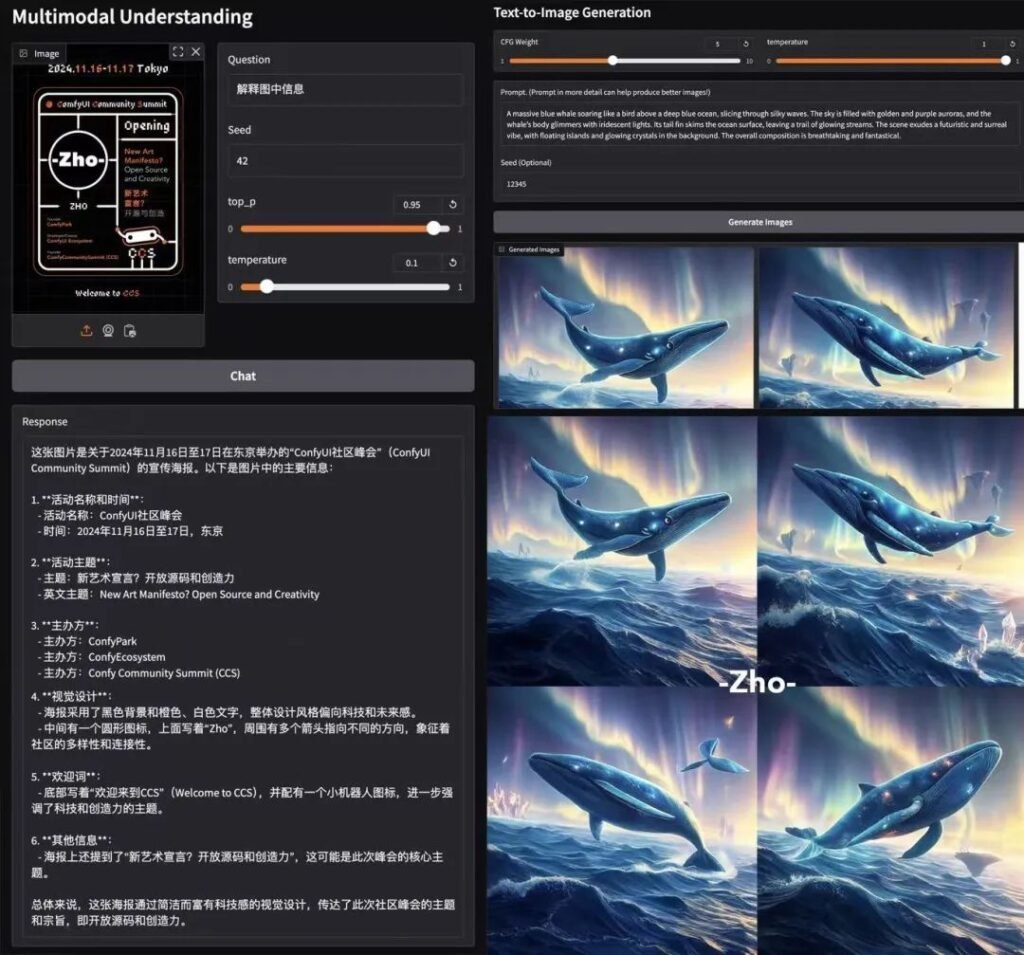
Dominasi Tolok Ukur
📊 Pemahaman Multimodal
Janus-Pro-7B mengungguli model khusus (mis., LLaVA) pada empat tolok ukur utama, menskalakan dengan lancar dengan ukuran parameter.
🎨 Pembuatan Teks-ke-Gambar
- GenEval: Cocok dengan SDXL dan DALL-E 3.
- DPG-Bench: Akurasi 84,2% (Janus-Pro-7B), mengungguli semua pesaing.
Pengujian Dunia Nyata
- Kecepatan: ~15 detik/gambar (GPU L4, VRAM 22GB).
- Kualitas: Kepatuhan yang kuat, meskipun detail kecil perlu disempurnakan.
- Demo Colab: Coba Janus-Pro-7B (Diperlukan tingkat Pro).
Perincian Teknis
Arsitektur
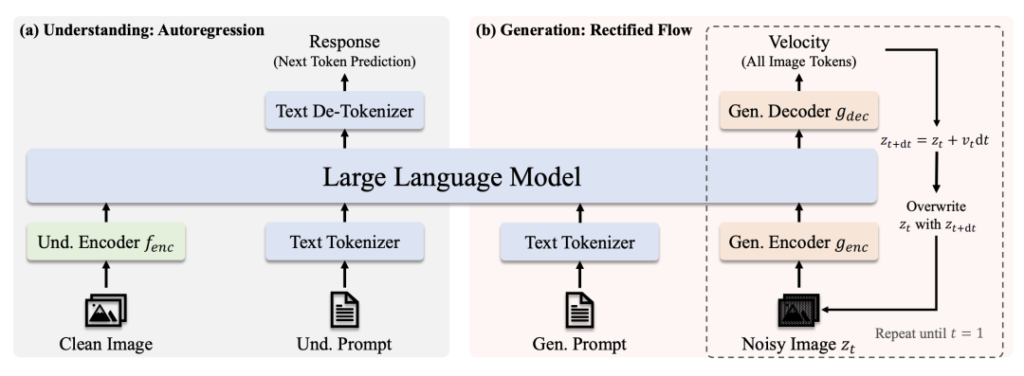
- Memahami Path: Gambar bersih → Penyandi SigLIP-L → LLM → Tanggapan teks.
- Jalur Generasi: Gambar berisik → Dekoder Aliran yang diperbaiki + LLM → Denoisasi berulang.
Inovasi Utama
- Pengkodean Visual Terpisah: Jalur terpisah untuk pemahaman/pembangkitan mencegah "konflik peran" dalam modul visi.
- Inti Transformator Bersama: Memungkinkan transfer pengetahuan lintas tugas (misalnya, mempelajari konsep "kucing" membantu pengenalan dan menggambar).
Gebrakan Komunitas
AK (Peneliti AI): "Kesederhanaan dan fleksibilitas Janus-Pro menjadikannya kandidat utama untuk sistem multimodal generasi berikutnya. Dengan memisahkan jalur penglihatan sekaligus mempertahankan Transformer yang terpadu, Transformer ini menyeimbangkan spesialisasi dengan generalisasi - suatu hal yang jarang terjadi."
Mengapa Lisensi MIT Penting
- Kebebasan: Menggunakan, memodifikasi, dan mendistribusikan secara komersial dengan batasan minimal.
- Transparansi: Akses kode penuh mempercepat peningkatan yang digerakkan oleh komunitas.
Final Take
Janus-Pro DeepSeek bukan sekadar model AI lainnya-ini adalah perubahan paradigma. Dengan menyatukan pemahaman dan generasi di bawah satu atap, ini membuka pintu untuk alat kreatif yang lebih cerdas, aplikasi real-time, dan penerapan yang hemat biaya. Dengan akses sumber terbuka dan lisensi MIT, ini bisa menjadi katalisator untuk gelombang inovasi multimodal berikutnya. 🚀
Untuk para pengembang: Lihat bagian Node ComfyUI dan bergabunglah dengan gelombang eksperimen!
postingan ini disponsori oleh:


