

UdostępnijGPT-4o-Image to obszerny zbiór danych służący do generowania obrazów wysokiej jakości, w którym wszystkie obrazy są generowane przy użyciu funkcji generowania obrazów GPT-4o.
Zbiór danych ma na celu połączenie zalet multimodalnych modeli open source z mocnymi stronami GPT-4o w zakresie tworzenia treści wizualnych.
Zawiera 45 000 próbek tekstu na obraz i 46 000 próbek obrazu na tekst, co czyni go praktycznym zasobem do ulepszania modeli multimodalnych w zadaniach generowania i edycji obrazów.

Janus-4o to multimodalny LLM zdolny do generowania tekstu na obraz i tekstu + obrazu na obraz. Opiera się na Janus-Pro i jest dostrojony przy użyciu zestawu danych ShareGPT-4o-Image. W porównaniu do Janus-Pro Janus-4o wprowadza możliwości generowania tekstu + obrazu na obraz i osiąga znaczące ulepszenia w generowaniu tekstu na obraz.
Przegląd zbioru danych
Zbiór danych ShareGPT-4o-Image zawiera 91 000 próbek generowania obrazu GPT-4o, podzielonych na następujące kategorie:
- Tekst na obraz: 45 717
- Tekst-plus-obraz-do-obrazu: 46,539
Powiązane linki
Kod: github kliknij tutaj
Model: pobierz model ShareGPT-4o-Image
Papier: Kliknij tutaj
Wprowadzenie do artykułu
Ostatnie postępy w modelach generacji multimodalnej umożliwiły realistyczną, zgodną z instrukcjami generację obrazu. Jednak wiodące systemy, takie jak GPT-4o-Image, pozostają zastrzeżone i niedostępne.
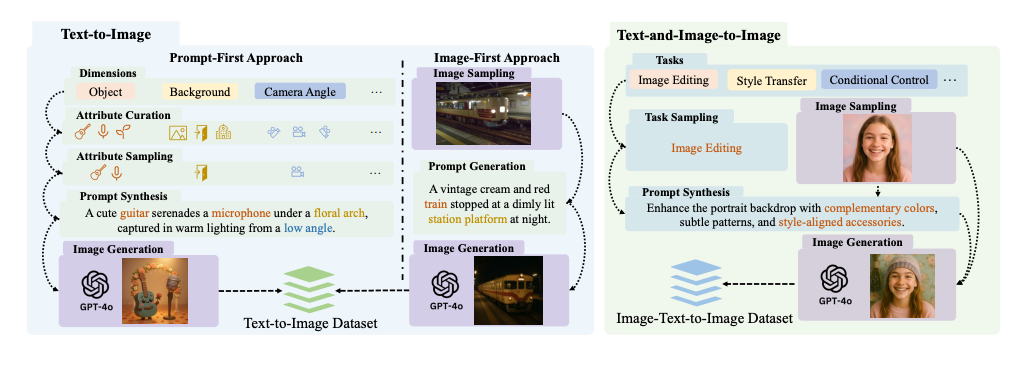
Aby udostępnić te możliwości szerszemu gronu odbiorców, w artykule przedstawiono ShareGPT-4o-Image, pierwszy zbiór danych zawierający 45 000 przykładów przekształcania tekstu na obraz i 46 000 przykładów przekształcania tekstu z obrazem na obraz, wszystkie zsyntetyzowane przy użyciu możliwości generowania obrazów GPT-4o w celu udoskonalenia jego zaawansowanych możliwości generowania obrazów. Wykorzystując ten zbiór danych, w artykule opracowano Janus-4o, multimodalny duży model językowy umożliwiający generowanie przekształceń tekstu na obraz i tekstu z obrazem na obraz.
Janus-4o nie tylko znacznie zwiększa możliwości generowania tekstu na obraz w porównaniu ze swoim poprzednikiem Janus-Pro, ale także wprowadza możliwości generowania tekstu i obrazu na obraz. Warto zauważyć, że osiąga imponującą wydajność w generowaniu obrazów z tekstu i obrazów od podstaw, wykorzystując jedynie 91 tys. próbek syntetycznych i trenując przez 6 godzin na maszynie 8×A800 GPU.
Mamy nadzieję, że wydanie ShareGPT-4o-Image i Janus-4o przyczyni się do rozwoju otwartych badań nad generowaniem fotorealistycznych obrazów zgodnych z instrukcjami.
Przegląd metody
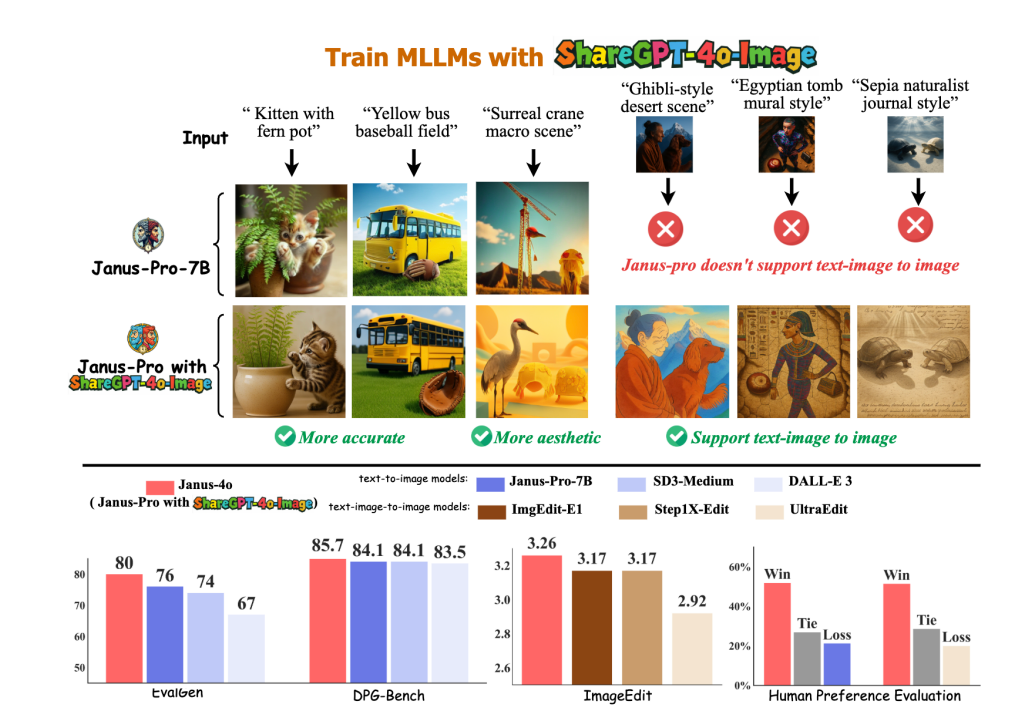
ShareGPT-4o-Image zwiększa wydajność generowania obrazów. Dostrajając Janus-Pro za pomocą ShareGPT-4o-Image, wygenerowaliśmy Janus-4o, który wykazuje znacząco ulepszoną wydajność generowania obrazu. Janus-4o obsługuje również generowanie tekstu do obrazu i obrazu do obrazu, przewyższając inne testy porównawcze z zaledwie 91 000 próbek treningowych.
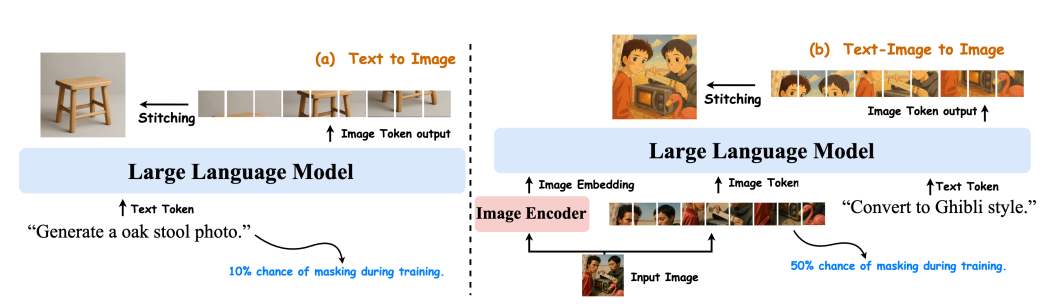
Przegląd modelu Janus-4o. Model jest oparty na Janus-Pro i skonstruowany poprzez dostrojenie go na ShareGPT-4o-Image. Zawiera ulepszenia, aby obsługiwać generowanie text-to-image i image-to-image. Zadania text-to-image i text-to-image są trenowane wspólnie.
Wyniki eksperymentalne

Wnioski
ShareGPT-4o-Image to pierwszy zbiór danych na dużą skalę, który jest w stanie uchwycić zaawansowane możliwości generowania obrazów GPT-4o w zakresie generowania tekstu do obrazu i tekstu do obrazu. Na podstawie tego zbioru danych w artykule opracowano Janus-4o, model uczenia maszynowego (MLLM) zdolny do generowania wysokiej jakości obrazów z czystego tekstu lub kombinacji obraz-tekst.
Janus-4o znacząco usprawnia generowanie tekstu na obraz i osiąga konkurencyjne wyniki w zadaniach przekształcania tekstu na obraz, co dowodzi wysokiej jakości i praktyczności ShareGPT-4o-Image.
Dzięki efektywności autoregresyjnego generowania obrazu na bazie MLLM, Janus-4o można wytrenować w zaledwie 6 godzin na komputerze z procesorem graficznym 8×A800, uzyskując przy tym znaczącą poprawę wydajności przy niezwykle niskich wymaganiach obliczeniowych.

