DeepSeek zaktualizował swoją stronę internetową.
We wczesnych godzinach sylwestrowych DeepSeek nagle ogłosił na GitHub, że przestrzeń projektu Janus otworzyła źródło modelu Janus-Pro i raportu technicznego.
Najpierw podkreślmy kilka kluczowych punktów:
- The Model Janus-Pro Tym razem wydany został multimodalny model, który może jednocześnie wykonywać zadania multimodalnego rozumienia i generowania obrazu. Ma w sumie dwie wersje parametrów, Janus-Pro-1B i Janus-Pro-7B.
- Główną innowacją Janus-Pro jest oddzielenie multimodalne rozumienie i generowanie, dwa różne zadania. Pozwala to na efektywne wykonanie tych dwóch zadań w tym samym modelu.
- Janus-Pro jest zgodny z architekturą modelu Janus wydaną przez DeepSeek w październiku ubiegłego roku, ale w tamtym czasie Janus nie miał dużej objętości. Dr Charles, ekspert w dziedzinie algorytmów wizyjnych, powiedział nam, że poprzedni Janus był "przeciętny" i "nie tak dobry jak model językowy DeepSeek".

Jego celem jest rozwiązanie trudnego problemu branży: zrównoważenie multimodalnego rozumienia i generowania obrazu
Zgodnie z oficjalnym wprowadzeniem DeepSeek, Janus-Pro może nie tylko rozumieć obrazy, wyodrębniać i rozumieć tekst na obrazach, ale także generować obrazy w tym samym czasie.
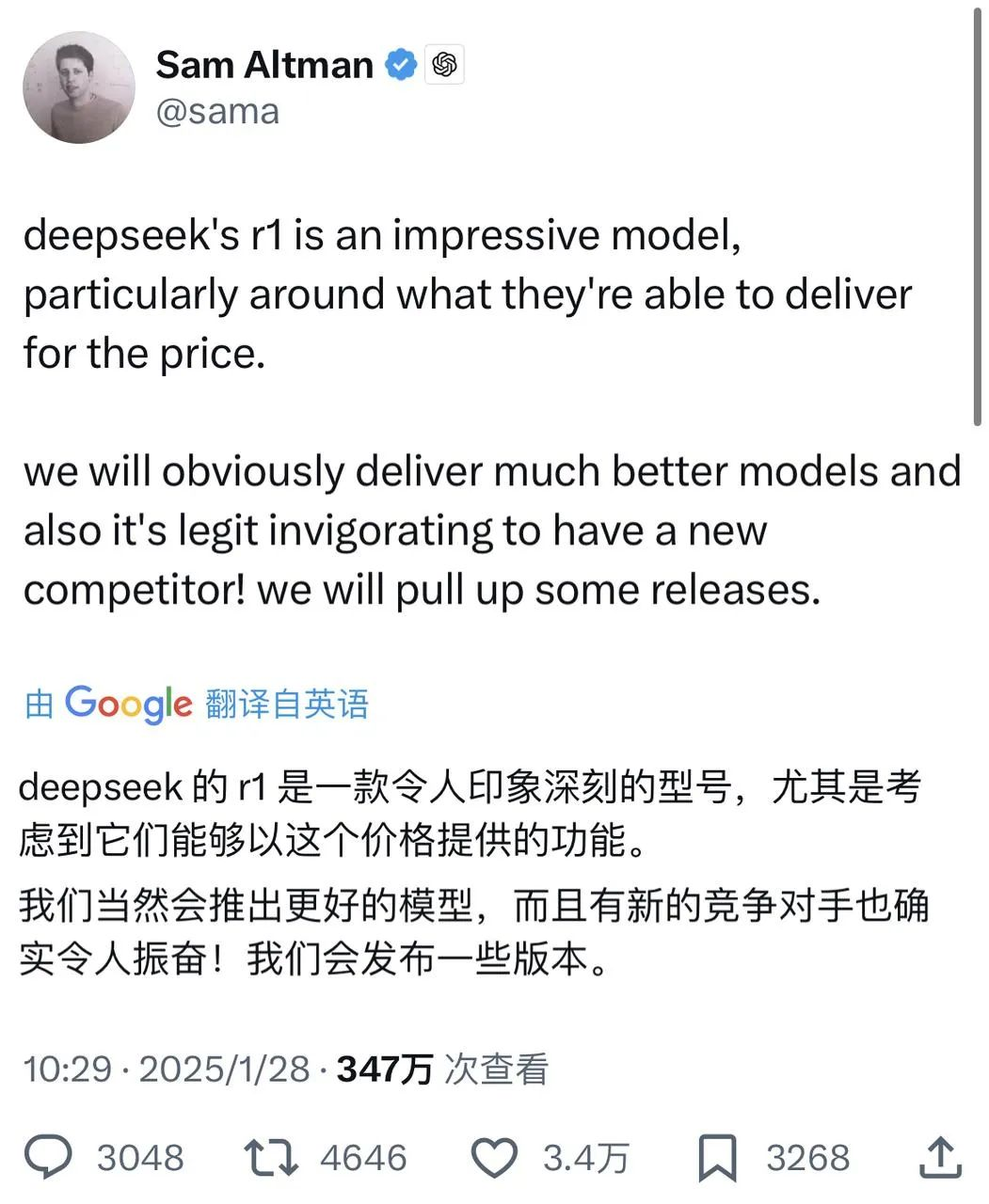
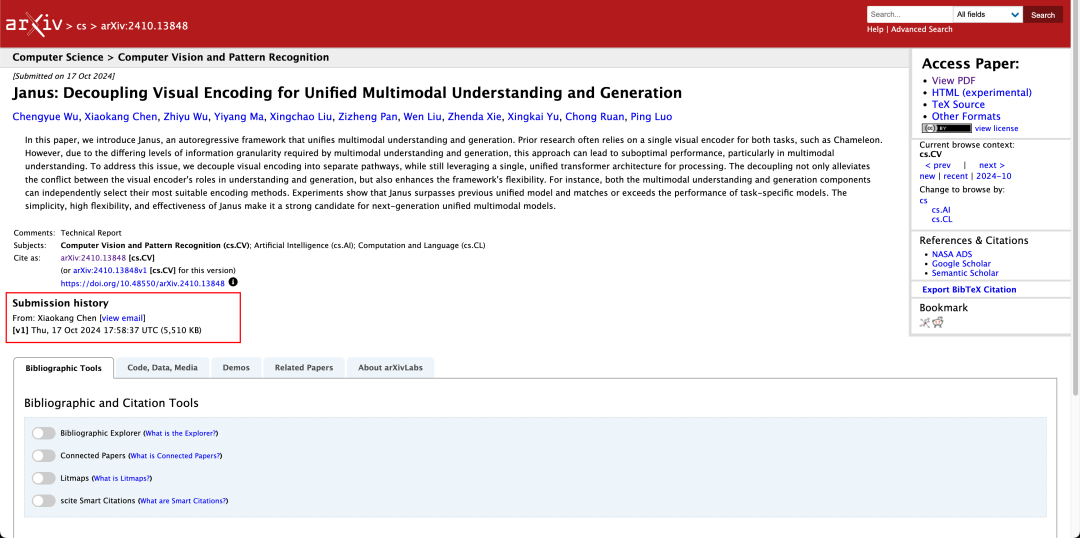
W raporcie technicznym wspomniano, że w porównaniu z innymi modelami tego samego typu i rzędu wielkości, wyniki Janus-Pro-7B w zestawach testowych GenEval i DPG-Bench przewyższają inne modele, takie jak SD3-Medium i DALL-E 3.
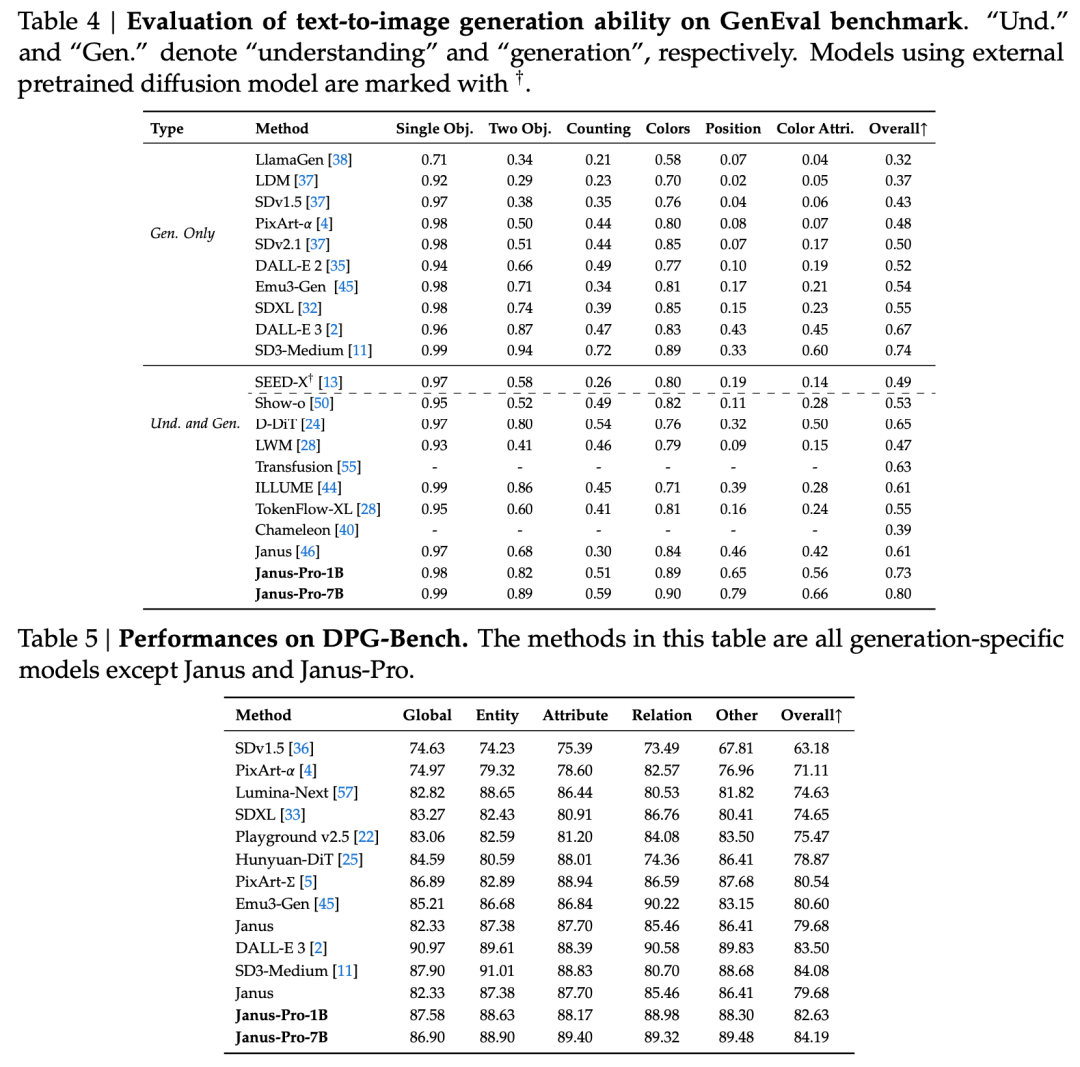
Urzędnik podaje również przykłady 👇:
Również wielu internautów na X wypróbowuje nowe funkcje.

Ale zdarzają się też sporadyczne awarie.
Poprzez zapoznanie się z dokumentami technicznymi dotyczącymi DeepSeekOdkryliśmy, że Janus Pro to optymalizacja oparta na Janusie, która została wydana trzy miesiące temu.
Główną innowacją tej serii modeli jest oddzielić zadania rozumienia wizualnego od zadań generowania wizualnego, aby zrównoważyć efekty tych dwóch zadań.
Nierzadko zdarza się, że model wykonuje multimodalne rozumienie i generowanie w tym samym czasie. D-DiT i TokenFlow-XL w tym zestawie testowym mają taką możliwość.
Charakterystyczne dla Janusa jest jednak to, że Poprzez oddzielenie przetwarzania, model, który może wykonywać multimodalne rozumienie i generowanie, równoważy efektywność obu zadań.
Równoważenie efektywności tych dwóch zadań jest trudnym problemem w branży. Wcześniej myślano o wykorzystaniu tego samego kodera do implementacji multimodalnego rozumienia i generowania w jak największym stopniu.
Zaletami tego podejścia są prosta architektura, brak zbędnego wdrażania i dostosowanie do modeli tekstowych (które również wykorzystują te same metody do generowania tekstu i jego rozumienia). Innym argumentem jest to, że połączenie wielu umiejętności może prowadzić do pewnego stopnia emergencji.
Jednak w rzeczywistości, po połączeniu generowania i rozumienia, te dwa zadania będą ze sobą sprzeczne - rozumienie obrazu wymaga od modelu abstrakcji w dużych wymiarach i wyodrębnienia podstawowej semantyki obrazu, która jest ukierunkowana na makroskopię. Z drugiej strony generowanie obrazu koncentruje się na wyrażaniu i generowaniu lokalnych szczegółów na poziomie pikseli.
Zwykłą praktyką w branży jest nadawanie priorytetu możliwościom generowania obrazu. W rezultacie powstają modele multimodalne, które może generować obrazy o wyższej jakości, ale wyniki rozumienia obrazu są często mierne.
Oddzielona architektura Janus i zoptymalizowana strategia treningowa Janus-Pro
Rozdzielona architektura Janusa pozwala modelowi na samodzielne równoważenie zadań rozumienia i generowania.
Zgodnie z wynikami zawartymi w oficjalnym raporcie technicznym, niezależnie od tego, czy chodzi o rozumienie multimodalne, czy generowanie obrazu, Janus-Pro-7B radzi sobie dobrze w wielu zestawach testowych.

Dla multimodalnego zrozumienia, Janus-Pro-7B zajął pierwsze miejsce w czterech z siedmiu ocenianych zestawów danych i drugie miejsce w pozostałych trzech, nieznacznie ustępując najwyżej sklasyfikowanemu modelowi.
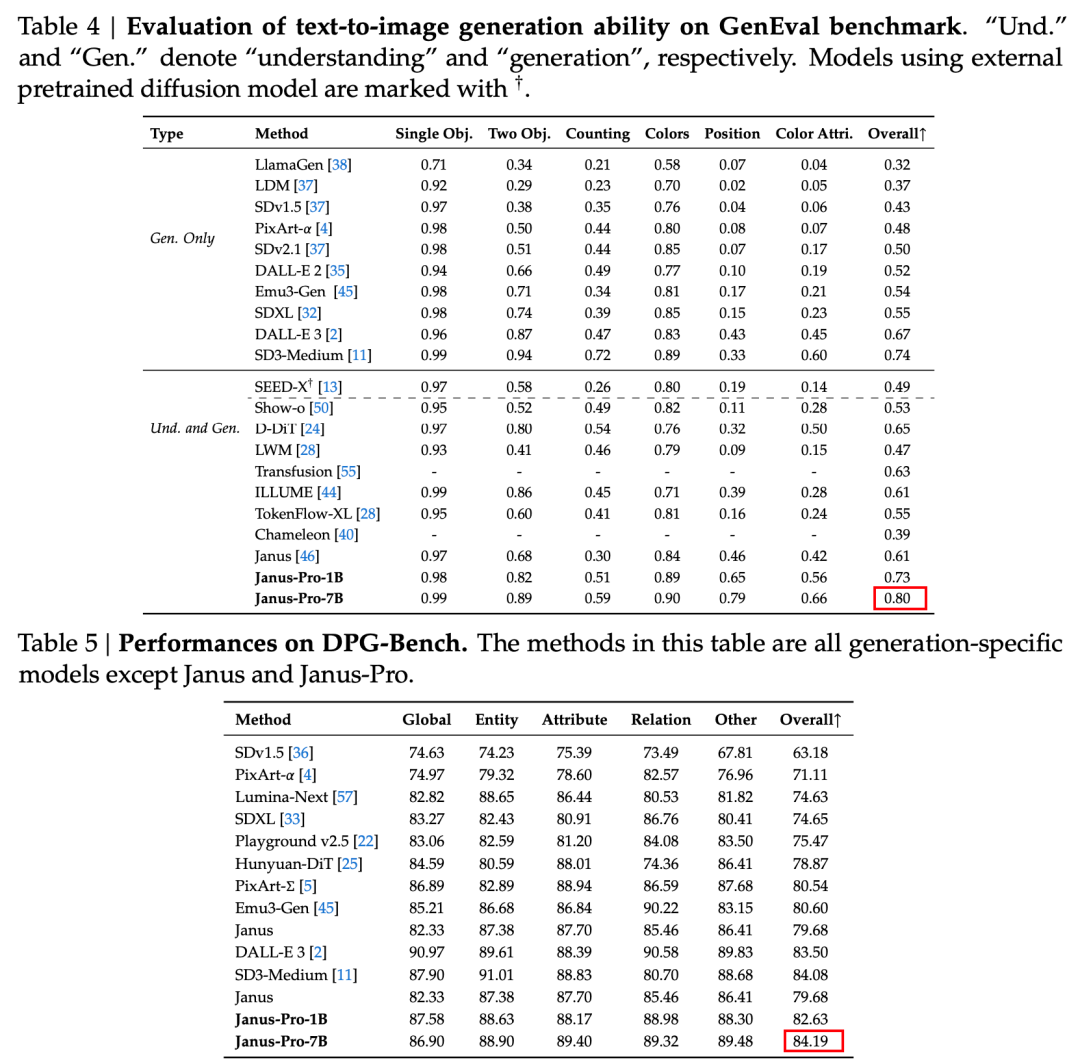
Do generowania obrazów, Janus-Pro-7B zajął pierwsze miejsce w ogólnym wyniku zarówno w zestawie danych GenEval, jak i DPG-Bench.
Ten efekt wielozadaniowości wynika głównie z wykorzystania przez serię Janus dwóch enkoderów wizualnych do różnych zadań:
- Zrozumienie kodera: używane do wyodrębniania cech semantycznych w obrazach do zadań rozumienia obrazu (takich jak pytania i odpowiedzi dotyczące obrazów, klasyfikacja wizualna itp.)
- Koder generatywny: konwertuje obrazy na dyskretną reprezentację (np. przy użyciu kodera VQ) do zadań generowania tekstu na obraz.
Dzięki tej architekturze, Model może niezależnie optymalizować wydajność każdego kodera, dzięki czemu zadania multimodalnego rozumienia i generowania mogą osiągnąć najlepszą wydajność.
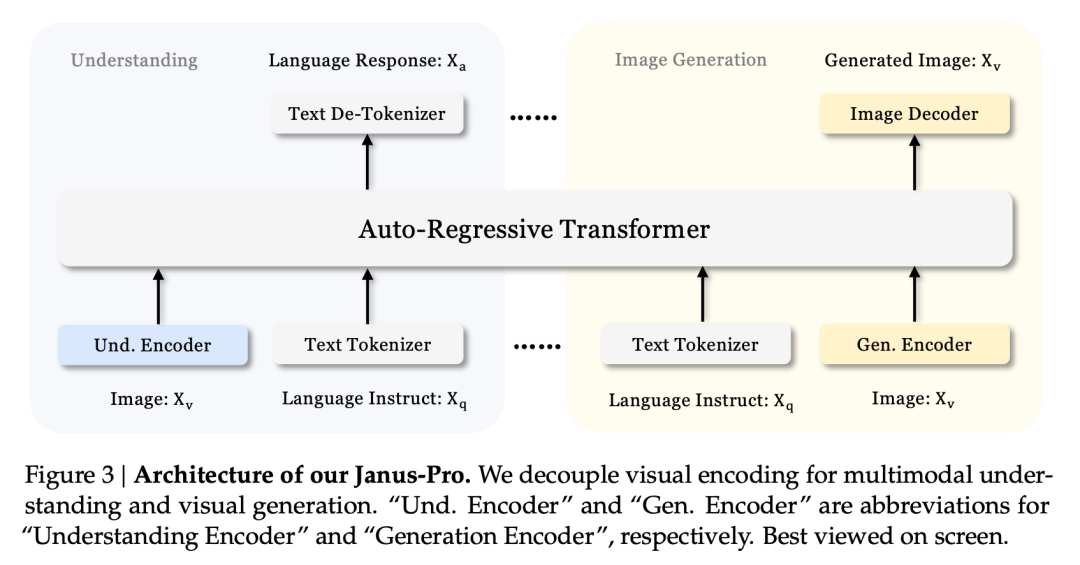
Ta oddzielona architektura jest wspólna dla Janus-Pro i Janus. Jakie iteracje przeszedł Janus-Pro w ciągu ostatnich kilku miesięcy?
Jak widać z wyników zestawu ewaluacyjnego, obecna wersja Janus-Pro-1B ma poprawę o około 10% do 20% w wynikach różnych zestawów ewaluacyjnych w porównaniu z poprzednim Janusem. Janus-Pro-7B ma najwyższą poprawę o około 45% w porównaniu do Janusa po rozszerzeniu liczby parametrów.

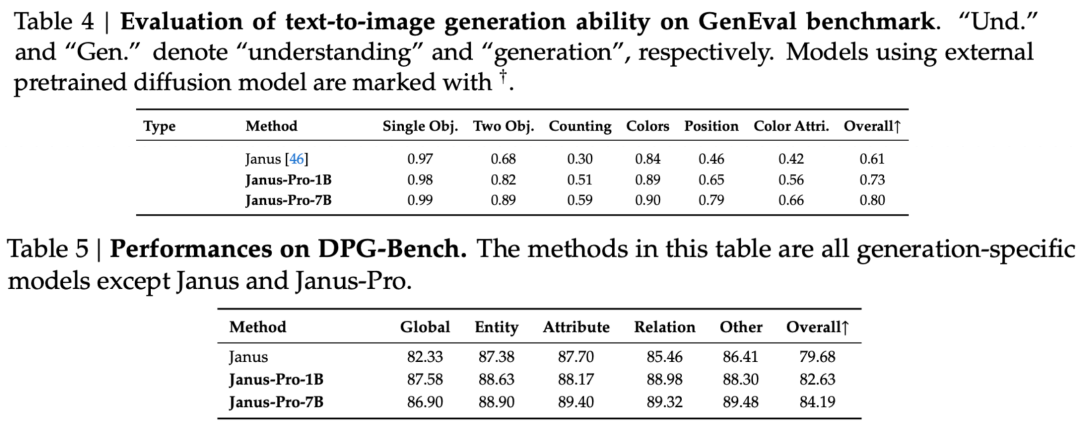
Jeśli chodzi o szczegóły szkolenia, raport techniczny stwierdza, że obecna wersja Janus-Pro, w porównaniu do poprzedniego modelu Janus, zachowuje rdzeń architektury odsprzężonej, a dodatkowo iteruje w zakresie wielkość parametru, strategia treningowa i dane treningowe.
Najpierw przyjrzyjmy się parametrom.
Pierwsza wersja Janusa miała tylko 1,3B parametrów, a obecna wersja Pro zawiera modele z parametrami 1B i 7B.
Te dwa rozmiary odzwierciedlają skalowalność architektury Janus. Model 1B, który jest najlżejszy, był już używany przez zewnętrznych użytkowników do uruchamiania w przeglądarce za pomocą WebGPU.
Istnieje również w strategia szkoleniowa.
Zgodnie z podziałem faz treningowych Janus, Janus Pro ma w sumie trzy fazy treningowe, a artykuł bezpośrednio dzieli je na etap I, etap II i etap III.
Zachowując podstawowe pomysły szkoleniowe i cele szkoleniowe każdego etapu, Janus-Pro wprowadził ulepszenia w czasie trwania szkolenia i danych szkoleniowych w trzech fazach. Poniżej przedstawiono konkretne ulepszenia na trzech etapach:
Etap I - Dłuższy czas treningu
W porównaniu z Janusem, Janus-Pro wydłużył czas uczenia w etapie I, zwłaszcza w zakresie uczenia adapterów i głowic obrazu w części wizualnej. Oznacza to, że uczenie się cech wizualnych otrzymało więcej czasu na trening i mamy nadzieję, że model będzie w stanie w pełni zrozumieć szczegółowe cechy obrazów (takie jak mapowanie semantyczne pikseli).
To rozszerzone szkolenie pomaga zapewnić, że szkolenie części wizualnej nie zostanie zakłócone przez inne moduły.
Etap II - Usunięcie danych ImageNet i dodanie danych multimodalnych
W etapie II, Janus wcześniej odnosił się do PixArt i trenował w dwóch częściach. Pierwsza część została przeszkolona przy użyciu zestawu danych ImageNet do zadania klasyfikacji obrazów, a druga część została przeszkolona przy użyciu zwykłych danych tekst-obraz. Około dwóch trzecich czasu w etapie II poświęcono na szkolenie w pierwszej części.
Janus-Pro usuwa szkolenie ImageNet w etapie II. Taka konstrukcja pozwala modelowi skupić się na danych tekstowo-obrazowych podczas szkolenia na etapie II. Zgodnie z wynikami eksperymentów, może to znacznie poprawić wykorzystanie danych tekstowo-obrazowych.
Oprócz dostosowania projektu metody szkoleniowej, zestaw danych szkoleniowych wykorzystywany w etapie II nie jest już ograniczony do zadania klasyfikacji pojedynczego obrazu, ale obejmuje także więcej innych typów danych multimodalnych, takich jak opis obrazu i dialog, do wspólnego szkolenia.
Etap III - Optymalizacja współczynnika danych
W etapie III szkolenia Janus-Pro dostosowuje stosunek różnych typów danych szkoleniowych.
Poprzednio stosunek multimodalnych danych rozumienia, zwykłych danych tekstowych i danych tekstowo-obrazowych w danych treningowych używanych przez Janus w etapie III wynosił 7:3:10. Janus-Pro zmniejsza stosunek dwóch ostatnich typów danych i dostosowuje stosunek trzech typów danych do 5:1:4, czyli zwraca większą uwagę na multimodalne zadanie rozumienia.
Przyjrzyjmy się danym treningowym.
W porównaniu do Janusa, Janus-Pro tym razem znacznie zwiększa ilość wysokiej jakości dane syntetyczne.
Zwiększa to ilość i różnorodność danych szkoleniowych do multimodalnego rozumienia i generowania obrazów.
Rozszerzenie multimodalnego rozumienia danych:
Janus-Pro odnosi się do zbioru danych DeepSeek-VL2 podczas treningu i dodaje około 90 milionów dodatkowych punktów danych, w tym nie tylko zbiory danych opisów obrazów, ale także zbiory danych złożonych scen, takich jak tabele, wykresy i dokumenty.
Podczas nadzorowanego etapu dostrajania (etap III) nadal dodaje zbiory danych związane ze zrozumieniem MEME i dialogiem (w tym dialogiem chińskim).
Rozszerzenie danych generacji wizualnej:
Oryginalne dane rzeczywiste miały niską jakość i wysoki poziom szumów, co powodowało, że model generował niestabilne dane wyjściowe i obrazy o niewystarczającej jakości estetycznej w zadaniach zamiany tekstu na obraz.
Janus-Pro dodał około 72 milionów nowych syntetycznych danych o wysokiej estetyce do fazy treningowej, zwiększając stosunek danych rzeczywistych do danych syntetycznych w fazie przedtreningowej do 1:1.
Wszystkie podpowiedzi dla danych syntetycznych zostały pobrane z zasobów publicznych. Eksperymenty wykazały, że dodanie tych danych sprawia, że model zbiega się szybciej, a generowane obrazy mają oczywistą poprawę stabilności i wizualnego piękna.
Kontynuacja rewolucji wydajnościowej?
Ogólnie rzecz biorąc, dzięki tej wersji DeepSeek wprowadził rewolucję wydajności do modeli wizualnych.
W przeciwieństwie do modeli wizualnych, które koncentrują się na jednej funkcji lub modeli multimodalnych, które faworyzują określone zadanie, Janus-Pro równoważy efekty dwóch głównych zadań generowania obrazu i multimodalnego rozumienia w tym samym modelu.
Co więcej, pomimo niewielkich parametrów, w ocenie pokonał OpenAI DALL-E 3 i SD3-Medium.
Rozszerzony na ziemię, przedsiębiorstwo musi jedynie wdrożyć model, aby bezpośrednio wdrożyć dwie funkcje generowania i rozumienia obrazu. W połączeniu z rozmiarem wynoszącym zaledwie 7B, trudność i koszt wdrożenia są znacznie niższe.
W związku z poprzednimi wydaniami R1 i V3, DeepSeek rzuca wyzwanie istniejącym zasadom gry poprzez "kompaktowe innowacje architektoniczne, lekkie modele, modele open source i bardzo niskie koszty szkolenia". Jest to powód paniki wśród zachodnich gigantów technologicznych, a nawet Wall Street.
Przed chwilą Sam Altman, który od kilku dni jest omamiany przez opinię publiczną, w końcu pozytywnie odniósł się do informacji o DeepSeek on X - chwaląc R1, powiedział, że OpenAI wyda kilka ogłoszeń.