
a era sztucznej inteligencji po cichu nadeszła.
Prawdopodobnie nikt nie spodziewał się, że w Chińskim Nowym Roku najgorętszym tematem nie będzie już tradycyjna internetowa bitwa na czerwone koperty, która była partnerem Gali Festiwalu Wiosny, ale firmy zajmujące się sztuczną inteligencją.
W miarę zbliżania się Festiwalu Wiosny, główne firmy modelarskie wcale się nie zrelaksowały, aktualizując falę modeli i produktów. Jednak najwięcej mówiło się o DeepSeek, "dużej firmie modelarskiej", która pojawiła się w zeszłym roku.
Wieczorem 20 stycznia br, GłębokiSeek wydała oficjalną wersję swojego modelu rozumowania DeepSeek-R1. Korzystając z niskiego kosztu szkolenia, bezpośrednio wytrenował wydajność, która nie ustępuje modelowi rozumowania OpenAI o1. Co więcej, jest on całkowicie darmowy i open source, co bezpośrednio wywołało trzęsienie ziemi w branży.
Po raz pierwszy krajowa sztuczna inteligencja wywołała poruszenie w świecie technologii na dużą skalę na całym świecie, zwłaszcza w Stanach Zjednoczonych. Deweloperzy wyrazili, że rozważają wykorzystanie DeepSeek do "odbudowy wszystkiego". W następstwie tej fali, po tygodniu fermentacji, a nawet dopiero co wydana w styczniu, aplikacja mobilna DeepSeek szybko osiągnęła szczyt rankingu bezpłatnych aplikacji w Apple App Store w USA, przewyższając nie tylko ChatGPT, ale także inne popularne aplikacje w USA.
Sukces DeepSeek wpłynął nawet bezpośrednio na amerykańską giełdę. Model wytrenowany bez użycia ogromnej ilości drogich procesorów graficznych sprawił, że ludzie ponownie zastanowili się nad ścieżką treningową sztucznej inteligencji, bezpośrednio powodując największy spadek 17% na pierwszych akcjach AI, NVIDIA.
A to jeszcze nie wszystko.
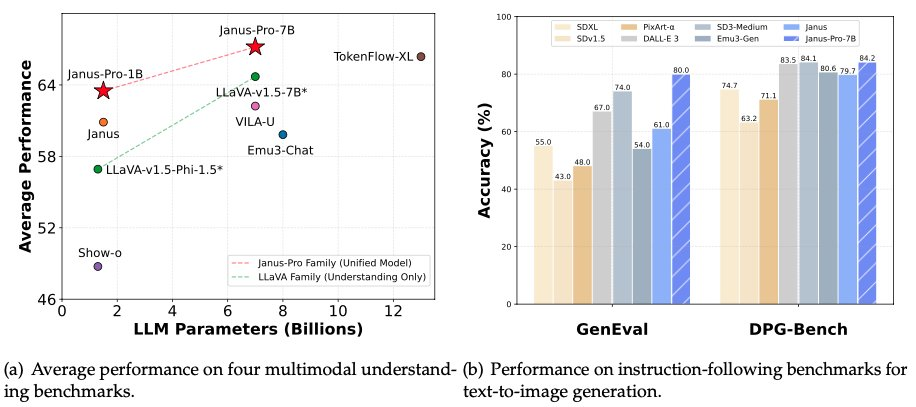
Wczesnym rankiem 28 stycznia, w noc poprzedzającą Sylwestra, DeepSeek po raz kolejny udostępnił źródło swojego multimodalnego modelu Janus-Pro-7B, ogłaszając, że pokonał on DALL-E 3 (od OpenAI) i Stable Diffusion w testach porównawczych GenEval i DPG-Bench.
Czy DeepSeek naprawdę zmiecie społeczność AI? Od modeli wnioskowania po modele multimodalne - czy DeepSeek restrukturyzuje wszystko, co jest pierwszym tematem Roku Węża?
Janus Prowalidacja innowacyjnej architektury modelu multimodalnego
DeepSeek udostępnił tym razem późnym wieczorem łącznie dwa modele: Janus-Pro-7B i Janus-Pro-1B (parametry 1,5B).
Jak sugeruje nazwa, sam model jest ulepszeniem poprzedniego modelu Janus.
DeepSeek wypuścił model Janus po raz pierwszy dopiero w październiku 2024 roku. Jak zwykle w przypadku DeepSeek, model przyjmuje innowacyjną architekturę. W wielu modelach generowania wizji model przyjmuje ujednoliconą architekturę Transformer, która może jednocześnie przetwarzać zadania zamiany tekstu na obraz i obrazu na tekst.
DeepSeek proponuje nowy pomysł, oddzielając wizualne kodowanie zadań rozumienia (graf-tekst) i generowania (tekst-graf), co poprawia elastyczność uczenia modelu i skutecznie łagodzi konflikty i wąskie gardła wydajności spowodowane użyciem pojedynczego kodowania wizualnego.
Właśnie dlatego DeepSeek nazwał ten model Janus. Janus jest starożytnym rzymskim bogiem drzwi i jest przedstawiany z dwiema twarzami skierowanymi w przeciwnych kierunkach. DeepSeek powiedział, że model został nazwany Janus, ponieważ może patrzeć na dane wizualne różnymi oczami, kodować cechy osobno, a następnie używać tego samego ciała (Transformer) do przetwarzania tych sygnałów wejściowych.
Ten nowy pomysł przyniósł dobre rezultaty w serii modeli Janus. Zespół twierdzi, że model Janus ma silne możliwości podążania za poleceniami, możliwości wielojęzyczne, a model jest inteligentniejszy, zdolny do odczytywania obrazów memów. Może również obsługiwać zadania, takie jak konwertowanie formuł lateksowych i konwertowanie wykresów na kod.
W serii modeli Janus Pro zespół częściowo zmodyfikował proces szkolenia modelu, który bezpośrednio osiągnął wyniki, które pokonały DALL-E 3 i Stable Diffusion w testach porównawczych GenEval i DPG-Bench.
Wraz z samym modelem, DeepSeek wydało również nowy multimodalny framework AI Janus Flow, który ma na celu ujednolicenie zadań związanych z rozumieniem i generowaniem obrazów.
Model Janus Pro może zapewnić bardziej stabilne wyniki przy użyciu krótkich podpowiedzi, z lepszą jakością wizualną, bogatszymi szczegółami i możliwością generowania prostego tekstu.
Model może generować obrazy i opisywać zdjęcia, identyfikować charakterystyczne atrakcje (takie jak Jezioro Zachodnie w Hangzhou), rozpoznawać tekst na obrazach i opisywać wiedzę na obrazach (takich jak ciastka "Tom i Jerry").
One x.com, Wiele osób zaczęło już eksperymentować z nowym modelem.

Test rozpoznawania obrazu jest pokazany po lewej stronie na powyższym rysunku, podczas gdy test generowania obrazu jest pokazany po prawej stronie.

Jak widać, Janus Pro dobrze radzi sobie również z odczytywaniem obrazów z wysoką precyzją. Potrafi rozpoznawać mieszane składy wyrażeń matematycznych i tekstu. W przyszłości większe znaczenie może mieć użycie go z modelem rozumowania.
Parametry 1B i 7B mogą odblokować nowe scenariusze zastosowań
W zadaniach rozumienia multimodalnego nowy model Janus-Pro wykorzystuje SigLIP-L jako koder wizualny i obsługuje wejścia obrazu 384 x 384 pikseli. W zadaniach generowania obrazu Janus-Pro wykorzystuje tokenizator z określonego źródła z częstotliwością downsamplingu wynoszącą 16.
To wciąż stosunkowo niewielki rozmiar obrazu. X Jeśli chodzi o analizę użytkownika, model Janus Pro jest raczej weryfikacją kierunkową. Jeśli weryfikacja okaże się wiarygodna, zostanie wydany model, który będzie można wprowadzić do produkcji.
Warto jednak zauważyć, że nowy model wydany tym razem przez Janusa jest nie tylko innowacyjny architektonicznie dla modeli multimodalnych, ale także stanowi nową eksplorację pod względem liczby parametrów.
Model porównywany tym razem przez DeepSeek Janus Pro, DALL-E 3, wcześniej ogłosił, że ma 12 miliardów parametrów, podczas gdy duży model Janus Pro ma tylko 7 miliardów parametrów. Przy tak kompaktowym rozmiarze, to już bardzo dobrze, że Janus Pro może osiągnąć takie wyniki.
W szczególności model 1B Janus Pro wykorzystuje tylko 1,5 miliarda parametrów. Użytkownicy dodali już obsługę modelu do transformers.js w sieci zewnętrznej. Oznacza to, że model może teraz uruchamiać 100% w przeglądarkach na WebGPU!
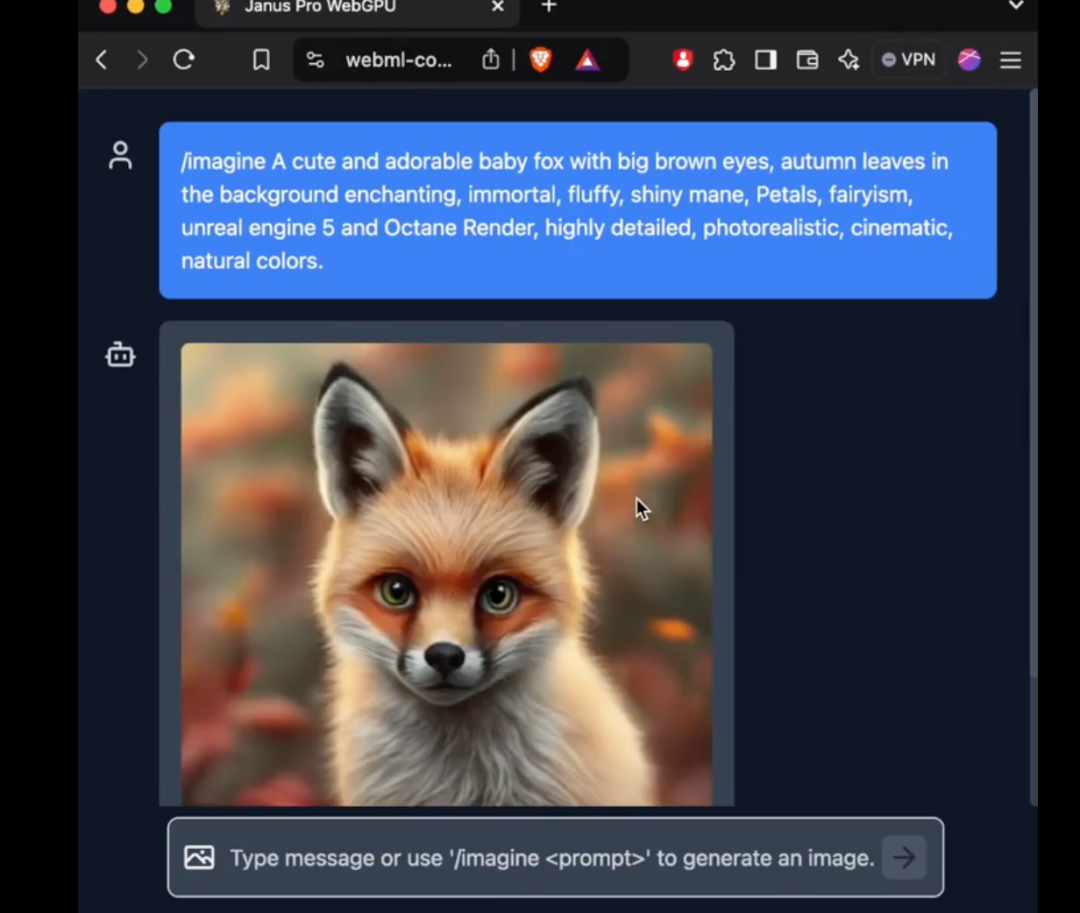
Chociaż w momencie publikacji tego tekstu autor nie był jeszcze w stanie z powodzeniem korzystać z nowego modelu Janus Pro w wersji webowej, fakt, że liczba parametrów jest wystarczająco mała, aby działać bezpośrednio po stronie internetowej, jest nadal niesamowitym ulepszeniem.
Oznacza to, że koszt generowania i rozumienia obrazów stale spada. Mamy okazję zobaczyć wykorzystanie sztucznej inteligencji w większej liczbie miejsc, w których surowe obrazy i rozumienie obrazu nie mogły być wcześniej używane, zmieniając nasze życie.
Głównym punktem zapalnym w 2024 roku jest to, w jaki sposób sprzęt AI z dodatkowym multimodalnym zrozumieniem może ingerować w nasze życie. Modele rozumienia multimodalnego o coraz niższych parametrach lub modele, które mogą działać na krawędzi, mogą umożliwić dalszą eksplozję sprzętu AI.
DeepSeek wywołał poruszenie w nowym roku. Czy wszystko można zrobić od nowa z chińską sztuczną inteligencją?
Świat sztucznej inteligencji zmienia się z dnia na dzień.
W okolicach zeszłorocznego Festiwalu Wiosny światem zawładnął model Sora firmy OpenAI. Jednak w ciągu roku chińskie firmy całkowicie nadrobiły zaległości w zakresie generowania wideo, przez co premiera Sory pod koniec roku wydaje się nieco ponura.
W tym roku tym, co poruszyło świat, stał się chiński DeepSeek.
DeepSeek nie jest tradycyjną firmą technologiczną, ale stworzyła niezwykle innowacyjne modele w cenie znacznie niższej niż w przypadku kart graficznych głównych amerykańskich firm modelarskich, co bezpośrednio zaszokowało jej amerykańskie odpowiedniki. Amerykanie wykrzyknęli: "Szkolenie modelu R1 kosztowało tylko 5,6 miliona dolarów amerykańskich, co jest nawet równowartością pensji każdego kierownika w zespole Meta GenAI. Czym jest ta tajemnicza wschodnia moc?"
Konto parodiujące założyciela DeepSeek, Liang Wenfeng, opublikowało interesujące zdjęcie bezpośrednio na X:

Na zdjęciu wykorzystano popularny mem przedstawiający znanego na całym świecie tureckiego strzelca w 2024 roku.
W finale strzelania z pistoletu pneumatycznego na 10 metrów podczas Igrzysk Olimpijskich w Paryżu, 51-letni turecki strzelec Mithat Dikec, noszący tylko parę zwykłych okularów krótkowzrocznych i parę zatyczek do uszu do spania, spokojnie sięgnął po srebrny medal z jedną ręką w kieszeni. Wszyscy inni obecni strzelcy potrzebowali dwóch profesjonalnych soczewek do ustawiania ostrości i blokowania światła oraz pary zatyczek do uszu z redukcją szumów, aby rozpocząć zawody.
Odkąd DeepSeek "złamał" Model rozumowania OpenAIGłówne amerykańskie firmy technologiczne znalazły się pod silną presją. Dziś Sam Altman w końcu odpowiedział oficjalnym oświadczeniem.

Czy rok 2025 będzie rokiem, w którym chińska sztuczna inteligencja wpłynie na amerykańskie postrzeganie?
DeepSeek ma jeszcze kilka tajemnic w rękawie - to będzie niezwykły Festiwal Wiosny.


