
Ⅰ. O que é destilação de conhecimento?
A destilação do conhecimento é uma técnica de compressão de modelos usada para transferir conhecimento de um modelo grande e complexo (o modelo do professor) para um modelo pequeno (o modelo do aluno).
O princípio fundamental é que o modelo do professor ensina o modelo do aluno prevendo resultados (como distribuições de probabilidade ou processos de inferência), e o modelo do aluno melhora seu desempenho aprendendo com essas previsões.
Esse método é particularmente adequado para dispositivos com recursos limitados, como telefones celulares ou dispositivos incorporados.
II. Conceitos básicos
2.1 Design do modelo
- Modelo: Um formato estruturado usado para padronizar a saída do modelo. Por exemplo
- : Marca o início do processo de raciocínio.
- : Marca o fim do processo de raciocínio.
- : Marca o início da resposta final.
- : Marca o fim da resposta final.
- Função:
- Clareza: Como as "palavras-chave" em uma pergunta de preenchimento de lacunas, ela informa ao modelo que "o processo de raciocínio vai até aqui e a resposta vai até ali".
- Consistência: Garante que todos os resultados sigam a mesma estrutura, facilitando o processamento e a análise subsequentes.
- Legibilidade: os seres humanos podem distinguir facilmente entre o processo de raciocínio e a resposta, melhorando a experiência do usuário.
2.2 Trajetória de raciocínio: A "cadeia de raciocínio" da solução do modelo
- Trajetória de raciocínio: As etapas detalhadas geradas pelo modelo ao resolver um problema mostram a cadeia lógica do modelo.
- Exemplo:
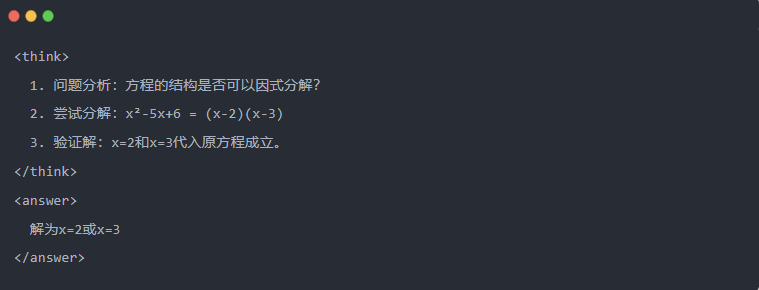
2.3 Amostragem de rejeição: Filtragem de bons dados de "tentativa e erro
- Amostragem de rejeição: Gerar várias respostas de candidatos e reter as boas, semelhante a escrever um rascunho e depois copiar a resposta correta em um exame.
Geração de dados destilados
A primeira etapa da destilação do conhecimento é gerar "dados de ensino" de alta qualidade para que os modelos pequenos possam aprender com eles.
Fontes de dados:
- 80% a partir dos dados de raciocínio gerados por DeepSeek-R1
- 20% dos dados da tarefa geral do DeepSeek-V3.
Processo de geração de dados de destilação:
- Filtragem de regrasVerifica automaticamente a exatidão da resposta (por exemplo, se a resposta matemática está de acordo com a fórmula).
- Verificação de legibilidadeElimina idiomas mistos (por exemplo, chinês e inglês misturados) ou parágrafos longos.
- Geração guiada por modelorequer que o DeepSeek-R1 produza trajetórias de inferência de acordo com o modelo.
- Filtragem de amostragem de rejeição:
- Integração de dadosNo final, foram geradas 800.000 amostras de alta qualidade, incluindo cerca de 600.000 dados de inferência e cerca de 200.000 dados gerais.
Ⅳ. Processo de destilação
Funções do professor e do aluno:
- DeepSeek-R1 como modelo de professor;
- Modelos da série Qwen como o modelo do aluno.
Etapas do treinamento:
Primeiro, a entrada de dados: você precisa inserir a parte da pergunta das 800.000 amostras no modelo Qwen e pedir que ele gere uma trajetória de inferência completa (processo de pensamento + resposta) de acordo com o modelo. Essa é uma etapa muito importante
Em seguida, cálculo de perda: compare a saída gerada pelo modelo do aluno com a trajetória de inferência do modelo do professor e alinhe a sequência de texto por meio do ajuste fino supervisionado (SFT). Se você não tiver certeza do que é SFT, espero que pesquise esta palavra-chave para saber mais
Concluir as atualizações de parâmetros para o modelo maior do aluno: Otimizar os parâmetros do modelo Qwen por meio de retropropagação para aproximar a saída do modelo do professor.
A repetição desse processo de treinamento várias vezes garante que o conhecimento seja suficientemente transferido. Isso atinge o objetivo original do treinamento. Daremos um exemplo para demonstrar isso e esperamos que você entenda
Ⅴ. Exemplo de demonstração
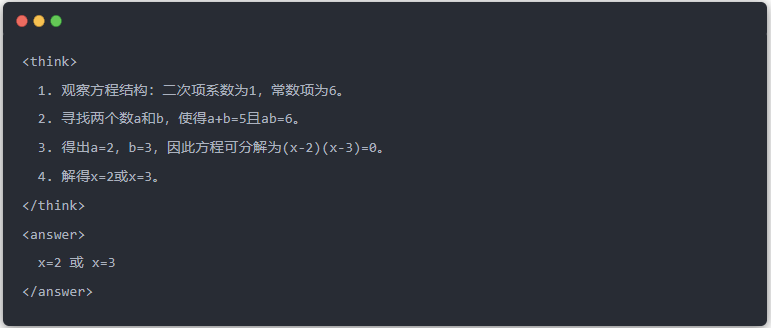
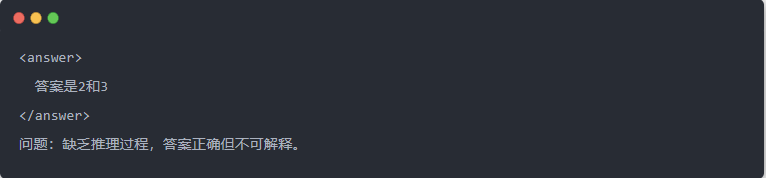
O artigo demonstra o efeito de destilação por meio de uma tarefa específica de resolução de equações (resolver equações):
- Saída padrão do modelo do professor:
- Saída do Qwen-7B antes da destilação:
- Saída do Qwen-7B após a destilação:
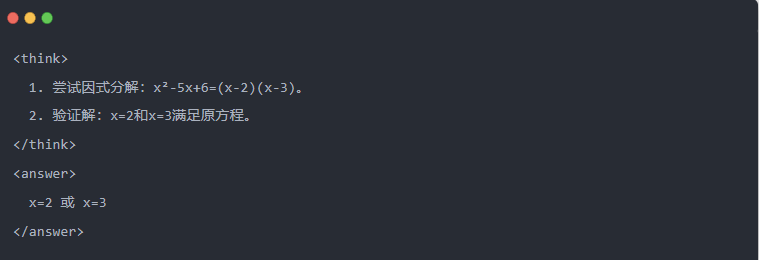
- Solução otimizada: Um processo de inferência estruturado é gerado, e a resposta é a mesma que o modelo do professor.
Ⅵ. Resumo
Por meio da destilação do conhecimento, a capacidade de inferência do DeepSeek-R1 é eficientemente migrada para a série Qwen de modelos pequenos. Esse processo se concentra na saída modelada e na amostragem de rejeição. Por meio da geração de dados estruturados e do treinamento refinado, os modelos pequenos também podem executar tarefas de inferência complexas em cenários com recursos limitados. Essa tecnologia fornece uma referência importante para a implantação leve de modelos de IA.



