
e a era da IA chegou silenciosamente.
Provavelmente ninguém esperava que, neste Ano Novo Chinês, o assunto mais quente não seria mais a tradicional batalha de envelopes vermelhos da Internet, que fez parceria com o Spring Festival Gala, mas as empresas de IA.
Com a aproximação do Festival da Primavera, as principais empresas de modelos não relaxaram nem um pouco, atualizando uma onda de modelos e produtos. No entanto, a mais comentada foi a DeepSeek, uma "grande empresa de modelos" que surgiu no ano passado.
Na noite de 20 de janeiro, ProfundoSeek lançou a versão oficial de seu modelo de raciocínio DeepSeek-R1. Usando um baixo custo de treinamento, ele treinou diretamente um desempenho que não é inferior ao modelo de raciocínio o1 da OpenAI. Além disso, ele é totalmente gratuito e de código aberto, o que provocou diretamente um terremoto no setor.
Essa é a primeira vez que uma IA doméstica causa agitação no mundo da tecnologia em grande escala, especialmente nos Estados Unidos. Os desenvolvedores expressaram que estão pensando em usar o DeepSeek para "reconstruir tudo". Na esteira dessa onda, após uma semana de fermentação, e mesmo recém-lançado em janeiro, o aplicativo móvel DeepSeek alcançou rapidamente o topo da classificação de aplicativos gratuitos na Apple App Store nos EUA, superando não apenas o ChatGPT, mas também outros aplicativos populares nos EUA.
O sucesso do DeepSeek afetou diretamente até mesmo o mercado de ações dos EUA. Um modelo treinado sem usar uma grande quantidade de GPUs caras fez com que as pessoas repensassem o caminho de treinamento da IA, causando diretamente a maior queda de 17% na primeira ação da IA, a NVIDIA.
E isso não é tudo.
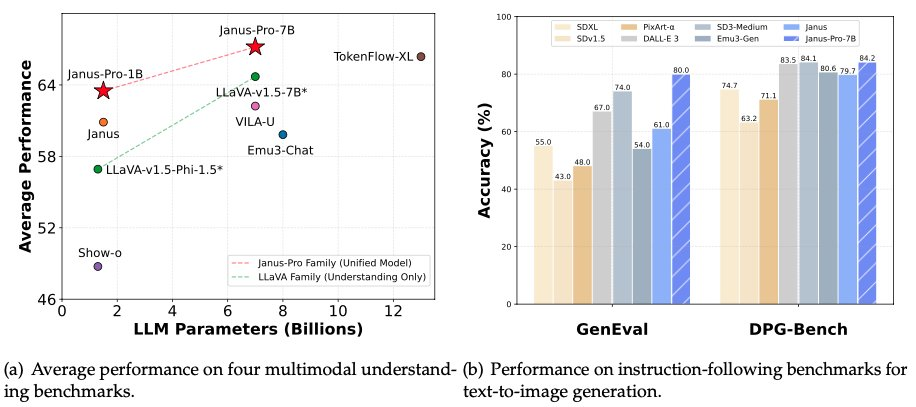
Na madrugada de 28 de janeiro, na noite anterior à véspera do Ano Novo, a DeepSeek mais uma vez abriu o código-fonte de seu modelo multimodal Janus-Pro-7B, anunciando que ele havia derrotado o DALL-E 3 (da OpenAI) e o Stable Diffusion nos testes de benchmark GenEval e DPG-Bench.
O DeepSeek realmente vai varrer a comunidade de IA? De modelos de inferência a modelos multimodais, o DeepSeek está reestruturando tudo no primeiro tópico do Ano da Serpente?
Janus ProA validação de uma arquitetura de modelo multimodal inovadora
O DeepSeek lançou um total de dois modelos tarde da noite desta vez: Janus-Pro-7B e Janus-Pro-1B (parâmetros de 1,5B).
Como o nome sugere, o modelo em si é uma atualização do modelo Janus anterior.
A DeepSeek só lançou o modelo Janus pela primeira vez em outubro de 2024. Como de costume no DeepSeek, o modelo adota uma arquitetura inovadora. Em muitos modelos de geração de visão, o modelo adota uma arquitetura Transformer unificada que pode processar simultaneamente as tarefas de texto para imagem e de imagem para texto.
O DeepSeek propõe uma nova ideia, desacoplando a codificação visual das tarefas de compreensão (gráfico para texto) e geração (texto para gráfico), o que melhora a flexibilidade do treinamento do modelo e alivia efetivamente os conflitos e gargalos de desempenho causados pelo uso de uma única codificação visual.
É por isso que a DeepSeek batizou o modelo de Janus. Janus é o antigo deus romano das portas e é representado com duas faces voltadas para direções opostas. O DeepSeek disse que o modelo recebeu o nome de Janus porque pode observar dados visuais com olhos diferentes, codificar recursos separadamente e, em seguida, usar o mesmo corpo (Transformer) para processar esses sinais de entrada.
Essa nova ideia produziu bons resultados na série de modelos Janus. A equipe diz que o modelo Janus tem fortes recursos de acompanhamento de comandos, recursos multilíngues e o modelo é mais inteligente, capaz de ler imagens de memes. Ele também pode lidar com tarefas como a conversão de fórmulas em látex e a conversão de gráficos em código.
Na série de modelos Janus Pro, a equipe modificou parcialmente o processo de treinamento do modelo, que obteve resultados diretos que superaram o DALL-E 3 e o Stable Diffusion nos testes de benchmark GenEval e DPG-Bench.
Junto com o modelo em si, a DeepSeek também lançou a nova estrutura de IA multimodal Janus Flow, que visa unificar as tarefas de compreensão e geração de imagens.
O modelo Janus Pro pode fornecer resultados mais estáveis usando avisos curtos, com melhor qualidade visual, detalhes mais ricos e capacidade de gerar texto simples.
O modelo pode gerar imagens e descrever imagens, identificar atrações de referência (como o Lago Oeste de Hangzhou), reconhecer texto em imagens e descrever conhecimento em imagens (como bolos "Tom e Jerry").
One x.com, Muitas pessoas já começaram a experimentar o novo modelo.

O teste de reconhecimento de imagem é mostrado à esquerda na figura acima, enquanto o teste de geração de imagem é mostrado à direita.

Como pode ser visto, o Janus Pro também faz um bom trabalho de leitura de imagens com alta precisão. Ele pode reconhecer a composição mista de expressões matemáticas e texto. No futuro, pode ser mais importante usá-lo com um modelo de raciocínio.
Os parâmetros de 1B e 7B podem abrir novos cenários de aplicação
Em tarefas de compreensão multimodal, o novo modelo Janus-Pro usa SigLIP-L como codificador visual e suporta entradas de imagem de 384 x 384 pixels. Nas tarefas de geração de imagens, o Janus-Pro usa um tokenizador de uma fonte específica com uma taxa de downsampling de 16.
Esse ainda é um tamanho de imagem relativamente pequeno. X Na análise do usuário, o modelo Janus Pro é mais uma verificação direcional. Se a verificação for confiável, será lançado um modelo que poderá ser colocado em produção.
No entanto, vale a pena observar que o novo modelo lançado pela Janus desta vez não é apenas inovador em termos de arquitetura para modelos multimodais, mas também uma nova exploração em termos do número de parâmetros.
O modelo comparado pelo DeepSeek Janus Pro desta vez, o DALL-E 3, anunciou anteriormente que tinha 12 bilhões de parâmetros, enquanto o modelo de tamanho grande do Janus Pro tem apenas 7 bilhões de parâmetros. Com um tamanho tão compacto, já é muito bom que o Janus Pro possa alcançar tais resultados.
Em particular, o modelo 1B do Janus Pro usa apenas 1,5 bilhão de parâmetros. Os usuários já adicionaram suporte para o modelo ao transformers.js na rede externa. Isso significa que o modelo agora pode executar o 100% em navegadores na WebGPU!
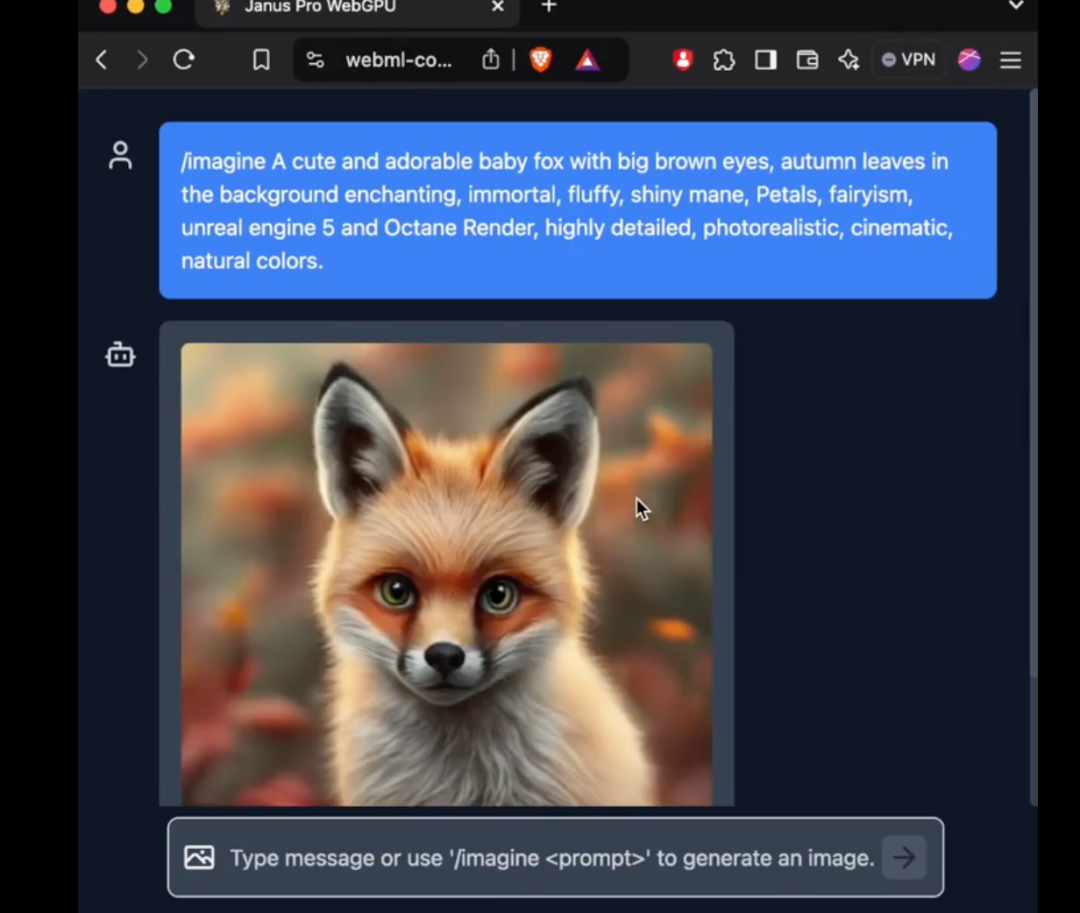
Embora, até o momento, o autor ainda não tenha conseguido usar com sucesso o novo modelo do Janus Pro na versão da Web, o fato de o número de parâmetros ser pequeno o suficiente para ser executado diretamente na Web ainda é um aprimoramento surpreendente.
Isso significa que o custo da geração/compreensão de imagens continua a diminuir. Temos a oportunidade de ver o uso da IA em mais lugares onde as imagens brutas e a compreensão de imagens não podiam ser usadas antes, mudando nossas vidas.
Um ponto importante em 2024 é como o hardware de IA com maior compreensão multimodal pode intervir em nossas vidas. Os modelos de compreensão multimodal com parâmetros cada vez mais baixos, ou modelos que podem ser executados no limite, podem permitir que o hardware de IA cresça ainda mais.
O DeepSeek agitou o ano novo. Será que tudo pode ser refeito com a IA chinesa?
O mundo da IA está mudando a cada dia.
Por volta do Festival da Primavera do ano passado, o que agitou o mundo foi o modelo Sora da OpenAI. No entanto, ao longo do ano, as empresas chinesas alcançaram o mesmo patamar em termos de geração de vídeo, fazendo com que o lançamento do Sora no final do ano pareça um pouco sombrio.
Este ano, o que agitou o mundo foi o DeepSeek da China.
A DeepSeek não é uma empresa de tecnologia tradicional, mas criou modelos extremamente inovadores a um custo muito inferior ao das placas de GPU das principais empresas americanas de modelos, o que chocou diretamente suas contrapartes americanas. Os americanos exclamaram: "O treinamento do modelo R1 custou apenas 5,6 milhões de dólares, o que equivale até mesmo ao salário de qualquer executivo da equipe da Meta GenAI. O que é esse misterioso poder oriental?"
Uma conta de paródia que imita o fundador da DeepSeek, Liang Wenfeng, publicou uma imagem interessante diretamente no X:

A imagem usou o meme de tendência do mundialmente famoso atirador turco em 2024.
Na final da pistola de ar de 10 metros dos eventos de tiro nos Jogos Olímpicos de Paris, o atirador turco Mithat Dikec, de 51 anos, usando apenas um par de óculos míopes comuns e um par de protetores auriculares para dormir, embolsou calmamente a medalha de prata com uma única mão no bolso. Todos os outros atiradores presentes precisavam de duas lentes profissionais para foco e bloqueio de luz e um par de protetores auriculares com cancelamento de ruído para iniciar a competição.
Desde que o DeepSeek "crackeou" Modelo de raciocínio da OpenAINa última semana, as principais empresas de tecnologia dos EUA sofreram intensa pressão. Hoje, Sam Altman finalmente respondeu com uma declaração oficial.

Será que 2025 será o ano em que a IA chinesa impactará as percepções americanas?
O DeepSeek ainda tem alguns segredos na manga - este está destinado a ser um extraordinário Festival da Primavera.




