
Ⅰ. 什麼是知識蒸餾?
知識蒸餾是一種模型壓縮技術,用來將知識從複雜的大型模型(教師模型)轉移到小型模型(學生模型)。
其核心原則是教師模型透過預測結果(例如概率分布或推理過程)來教導學生模型,而學生模型則透過從這些預測中學習來改善其表現。
此方法特別適用於資源有限的裝置,例如行動電話或嵌入式裝置。
二、核心概念
2.1 範本設計
- 範本:用於標準化模型輸出的結構化格式。例如
- :標誌著推理過程的開始。
- :標示推理過程的結束。
- :標示最終答案的開始。
- :標示最終答案的結束。
- 功能:
- 明確性:就像填空題中的「提示字詞」一樣,它告訴模型「思考過程到這裡,答案到這裡」。
- 一致性:確保所有輸出都遵循相同的結構,方便後續處理和分析。
- 可讀性:人類能夠輕易區分推理過程和答案,改善使用者體驗。
2.2 推理軌跡:模型解決方案的「思考鏈
- 推理軌跡:模型在解決問題時所產生的詳細步驟,顯示了模型的邏輯鏈。
- 範例:
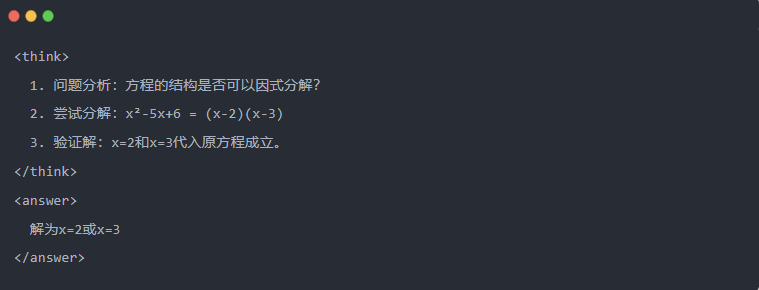
2.3 拒絕取樣:從「試驗與錯誤」中篩選出好的資料
- 拒絕抽樣:產生多個候選答案,並保留好的答案,類似於在考試中先寫草稿,再複製正確答案。
Ⅲ.蒸餾資料的產生
知識提煉的第一步是產生高品質的 「教學資料」,供小型模型學習。
資料來源:
- 80% 的推理資料由 DeepSeek-R1
- 20% 來自 DeepSeek-V3 一般任務資料。
蒸餾資料產生程序:
- 規則過濾: 自動檢查答案的正確性 (例如數學答案是否符合公式)。
- 可讀性檢查:消除混合語言(例如中英文混合)或冗長段落。
- 模板導向生成:要求 DeepSeek-R1 根據範本輸出推理軌跡。
- 剔除取樣濾波:
- 資料整合:最終產生了 800,000 個高品質的樣本,包括約 600,000 個推理資料和約 200,000 個一般資料。
Ⅳ.蒸餾製程
教師和學生的角色:
- DeepSeek-R1 作為教師模型;
- Qwen 系列模型作為學生模型。
訓練步驟:
首先是資料輸入:您需要將 800,000 個樣本中的問題部分輸入到 Qwen 模型中,並要求它根據模板產生完整的推理軌跡(思考過程 + 答案)。這是非常重要的一步
接下來是損失計算:將學生模型產生的輸出與教師模型的推理軌跡進行比較,並通過監督微調(SFT)來對齊文本序列。如果您不清楚什麼是 SFT,希望您可以搜尋此關鍵字來瞭解更多資訊
完成學生較大模型的參數更新:透過反向傳播優化 Qwen 模型的參數,以近似教師模型的輸出。
多次重複這個訓練過程可以確保知識得到充分的傳授。這樣就達到了原本的訓練目的。我們將舉例說明,希望您能了解
Ⅴ.範例展示
文章透過一個特定的方程式求解任務(解方程式)來展示蒸餾效應:
- 教師模型的標準輸出:
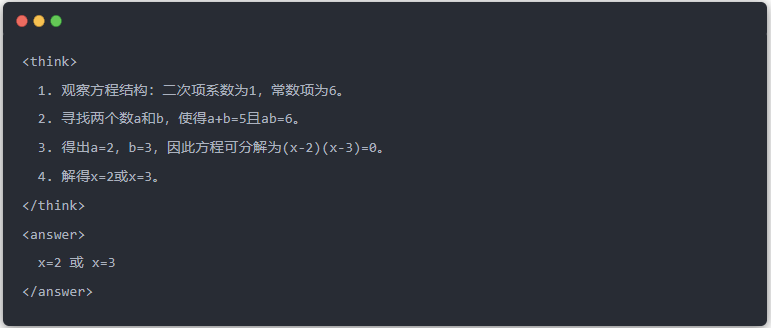
- 蒸餾前的 Qwen-7B 輸出:
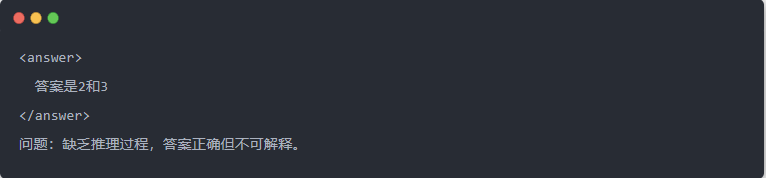
- 蒸餾後的 Qwen-7B 輸出:
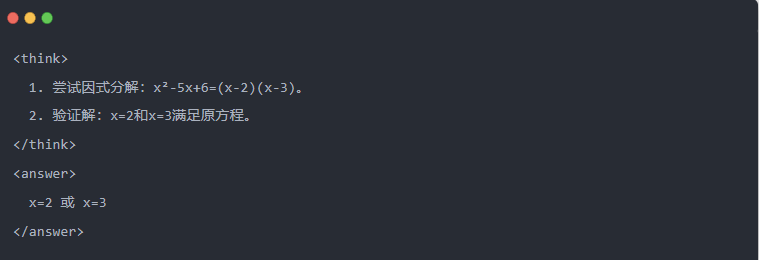
- 最佳化的解決方案:產生結構化的推論過程,答案與教師模型相同。
Ⅵ.摘要
透過知識提煉,DeepSeek-R1 的推理能力被有效地移植到 Qwen 系列的小型模型中。這個過程著重於模板化輸出和剔除抽樣。通過結構化的數據生成和精煉的訓練,小型模型也可以在資源有限的情況下完成複雜的推理任務。這項技術為人工智能模型的輕量級部署提供了重要參考。


