
而人工智能時代已悄然來臨。
大概沒有人想到,這個農曆新年,最熱門的話題不再是傳統的互聯網紅包大戰、誰與春晚合作,而是人工智能公司。
臨近春節,各大模型公司一點也沒有放鬆,更新了一大波模型和產品。然而,最受關注的還是去年崛起的 「模型大廠 」DeepSeek。
1 月 20 日晚上 深度S嚇 發布了其推理模型 DeepSeek-R1 的正式版本。利用低廉的訓練成本,直接訓練出不遜於 OpenAI 推理模型 o1 的效能。而且,它完全免費開源,直接引發了產業地震。
這是國內人工智能首次在全球,尤其是美國,大規模地引起科技界的轟動。開發人員表示,他們正在考慮使用 DeepSeek 「重建一切」。在这股浪潮下,经过一周的发酵,甚至刚刚发布一月,DeepSeek手机应用就迅速登上了美国苹果App Store免费应用排行榜的榜首,不仅超过了ChatGPT,还超过了美国其他热门应用。
DeepSeek 的成功甚至直接影響了美國股市。一個不使用大量昂貴 GPU 訓練出來的模型,讓人們重新思考 AI 的訓練路徑,直接造成 AI 第一股 NVIDIA 最大跌幅 17%。
這還不是全部。
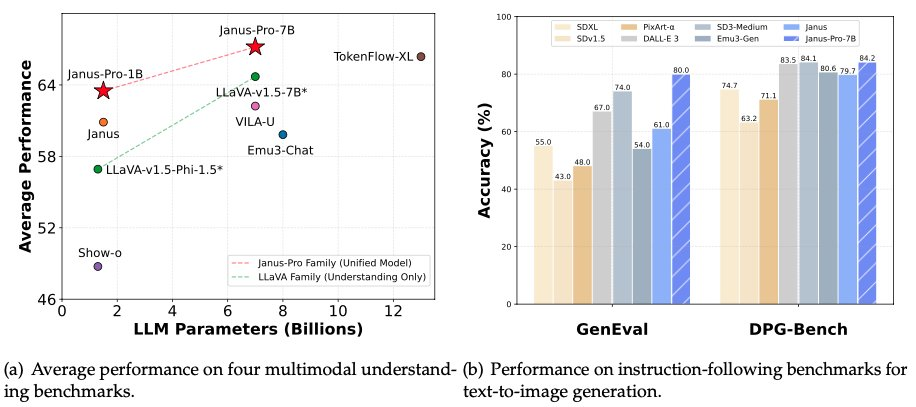
1 月 28 日凌晨,也就是除夕前一晚,DeepSeek 再次將多模態模型 Janus-Pro-7B 開源,宣布在 GenEval 與 DPG-Bench 基準測試中擊敗 DALL-E 3 (來自 OpenAI) 與 Stable Diffusion。
DeepSeek 真的要橫掃人工智能界嗎?從推理模型到多模態模型,DeepSeek是否要重整一切,成為蛇年的第一個話題?
Janus Pro驗證創新的多模式模型架構
DeepSeek 這次在深夜共發佈了兩個模型:Janus-Pro-7B 和 Janus-Pro-1B(1.5B 參數)。
顧名思義,這款機型本身就是之前 Janus 機型的升級版。
DeepSeek 在 2024 年 10 月才首次發佈 Janus 模型。一如DeepSeek的慣例,該模型採用了創新的架構。在眾多的視覺生成模型中,該模型採用了統一的 Transformer 架構,可以同時處理文字到圖像和圖像到文字的任務。
DeepSeek 提出了一種新思路,將理解任務(圖到文本)和生成任務(文本到圖)的視覺編碼解耦,提高了模型訓練的靈活性,有效緩解了使用單一視覺編碼產生的衝突和性能瓶頸。
這就是 DeepSeek 將這個模型命名為 Janus 的原因。Janus 是古羅馬的門神,被描繪成兩張面孔朝向相反方向。DeepSeek 表示,這個模型之所以命名為 Janus,是因為它可以用不同的眼睛來觀察視覺資料,分別對特徵進行編碼,然後用同一個機體(Transformer)來處理這些輸入訊號。
這個新構想在 Janus 系列模型中產生了良好的效果。研究團隊表示,Janus 模型具有強大的指令遵循能力、多語言能力,而且模型更聰明,能夠讀取 meme 圖片。它還可以處理轉換 latex 公式、將圖表轉換為程式碼等任務。
在 Janus Pro 系列模型中,研究團隊部分修改了模型的訓練過程,直接取得了在 GenEval 和 DPG-Bench 基準測試中擊敗 DALL-E 3 和 Stable Diffusion 的結果。
除了模型本身,DeepSeek 還發布了全新的多模態 AI 框架 Janus Flow,旨在統一圖像理解和生成任務。
Janus Pro 機型 可以使用簡短的提示提供更穩定的輸出,具有更好的視覺品質、更豐富的細節,以及產生簡單文字的能力。
該模型可以生成圖片並對圖片進行描述、識別地標性景點(如杭州西湖)、識別圖片中的文字以及描述圖片中的知識(如 「湯姆和傑瑞 」蛋糕)。
One x.com,許多人已經開始嘗試使用新模式。

上圖中左側為影像辨識測試,右側為影像產生測試。

可以看出,Janus Pro 在高精度讀取圖像方面也做得很好。它可以辨識數學表達式與文字的混合排版。在未來,將它與推理模型一起使用可能會有更大的意義。
1B 和 7B 的參數可能會開啟新的應用場景
在多模式理解任務中,新機型 Janus-Pro 使用 SigLIP-L 作為視覺編碼器,並支援 384 x 384 像素的影像輸入。在影像產生任務中,Janus-Pro 使用來自特定來源的標記器,其下取樣率為 16。
這仍然是相對較小的影像尺寸。X 在使用者分析上,Janus Pro 機型更像是一個方向性的驗證。如果驗證可靠,就會推出可以投入生產的機型。
不過,值得注意的是,Janus 這次發表的新模型不僅在架構上創新了多模態模型,在參數數量上也有新的探索。
DeepSeek Janus Pro 這次比較的模型 DALL-E 3,之前公佈有 120 億個參數,而 Janus Pro 的大尺寸模型只有 70 億個參數。如此小巧的尺寸,Janus Pro 能取得這樣的成績已經非常不錯了。
其中,Janus Pro 的 1B 模型僅使用 15 億個參數。使用者已在外部網路的 transformers.js 中加入對該模型的支援。這表示該模型現在可以在 WebGPU 上的瀏覽器中執行 100%!
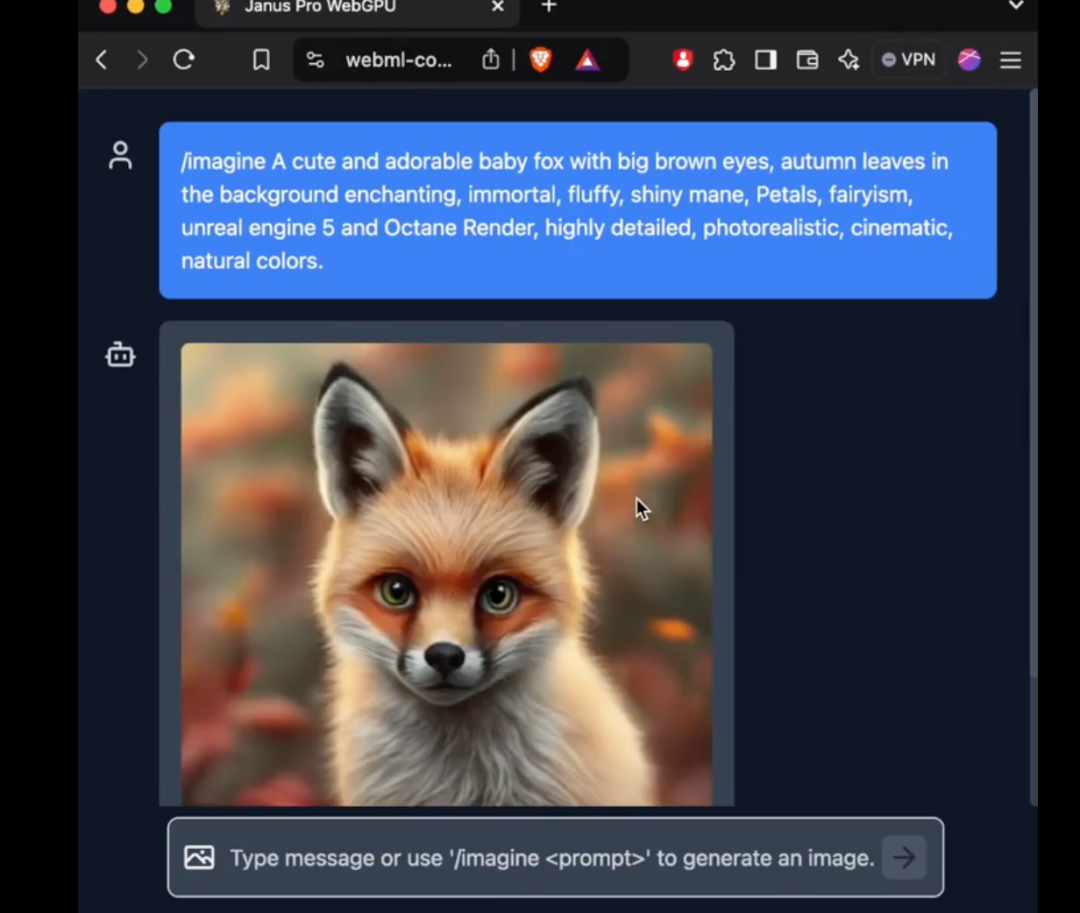
雖然截至發稿前,筆者尚未能在網頁版上成功使用 Janus Pro 的新模型,但參數數量少到可以直接在網頁端執行的程度,仍是一個驚人的進步。
這意味著影像產生/影像理解的成本正在持續下降。我們有機會看到在更多以前無法使用原始影像和影像理解的地方使用 AI,改變我們的生活。
2024 年的一大熱點在於,具有額外多模態理解能力的人工智能硬體如何介入我們的生活。參數愈來愈低的多模態理解模型,或是可望在邊緣運行的模型,可能會讓人工智能硬體進一步爆發。
DeepSeek 攪動了新的一年。一切都可以用中國的人工智能重做嗎?
人工智能的世界日新月異。
去年春節前後,轟動全球的是 OpenAI 的 Sora 模式。然而,在這一年裡,中國公司在視頻生成方面已經完全迎頭趕上,這讓 Sora 在年底的發布顯得有些黯淡。
今年,轟動全球的成了中國的 DeepSeek。
DeepSeek 並非傳統的科技公司,卻以遠低於美國主要模型公司 GPU 卡的成本,做出極富創意的模型,直接震撼了美國同行。美國人感嘆道"R1模型的培訓只花了560萬美元,甚至相當於Meta GenAI團隊任何一位高管的薪水。這個神秘的東方力量到底是什麼?"
一個模仿 DeepSeek 創辦人梁文鋒的模仿帳號直接在 X 上發佈了一張有趣的圖片:

這張圖片使用了 2024 年世界知名的土耳其射手的潮流meme。
在巴黎奧運射擊項目 10 公尺氣手槍決賽中,51 歲的土耳其射手 Mithat Dikec 只戴著一副普通近視眼鏡和一對睡眠耳塞,單手插袋,淡定地將銀牌收入囊中。其他所有到場的射手都需要兩副專業鏡片來對焦與遮光,再加上一對降噪耳塞才能開始比賽。
由於 DeepSeek「破解」了 OpenAI 的推理模型, 美國各大科技公司都受到了強大的壓力。今天,Sam Altman 終於以官方聲明作出回應。

2025 年會是中國人工智能衝擊美國人觀念的一年嗎?
DeepSeek 仍有一些秘密 - 這注定是一個不平凡的春節。



