
Ⅰ. Hvad er vidensdestillation?
Vidensdestillation er en modelkomprimeringsteknik, der bruges til at overføre viden fra en stor, kompleks model (lærermodellen) til en lille model (elevmodellen).
Det centrale princip er, at lærermodellen underviser elevmodellen ved at forudsige resultater (f.eks. sandsynlighedsfordelinger eller slutningsprocesser), og elevmodellen forbedrer sin præstation ved at lære af disse forudsigelser.
Denne metode er særligt velegnet til enheder med begrænsede ressourcer, som f.eks. mobiltelefoner eller indlejrede enheder.
II. centrale begreber
2.1 Design af skabelon
- Skabelon: Et struktureret format, der bruges til at standardisere modeloutput. For eksempel
- : Markerer begyndelsen på ræsonnementsprocessen.
- : Markerer afslutningen på ræsonnementsprocessen.
- : Markerer begyndelsen af det endelige svar.
- : Markerer afslutningen på det endelige svar.
- Funktion:
- Klarhed: Ligesom "spørgeordene" i et udfyldningsspørgsmål fortæller det modellen, at "tænkeprocessen foregår her, og svaret foregår der."
- Konsistens: Sikrer, at alle outputs følger samme struktur, hvilket letter efterfølgende behandling og analyse.
- Læsbarhed: Mennesker kan nemt skelne mellem ræsonnementsprocessen og svaret, hvilket forbedrer brugeroplevelsen.
2.2 Ræsonnementets bane: "Tænkekæden" i modellens løsning
- Ræsonnementets bane: De detaljerede trin, som modellen genererer, når den løser et problem, viser modellens logiske kæde.
- Et eksempel:
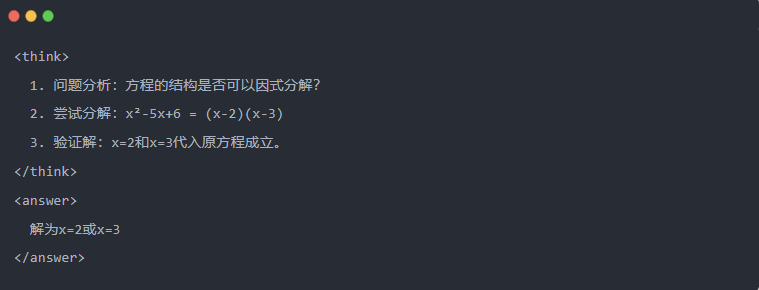
2.3 Afvisning af prøveudtagning: Filtrering af gode data fra "trial and error
- Afvisning af prøver: Generer flere kandidatsvar og behold de gode, ligesom når man skriver en kladde og derefter kopierer det rigtige svar i en eksamen.
Generering af destillerede data
Det første skridt i vidensdestillation er at generere "undervisningsdata" af høj kvalitet, som små modeller kan lære af.
Datakilder:
- 80% fra de ræsonnerende data genereret af DeepSeek-R1
- 20% fra DeepSeek-V3 generelle opgavedata.
Proces til generering af destillationsdata:
- Filtrering af regler: kontrollerer automatisk svarets korrekthed (f.eks. om det matematiske svar er i overensstemmelse med formlen).
- Tjek af læsbarhed: eliminerer blandede sprog (f.eks. kinesisk og engelsk blandet) eller lange afsnit.
- Skabelonstyret generering: kræver, at DeepSeek-R1 udsender slutningsbaner i henhold til skabelonen.
- Filtrering af afvisningsprøver:
- Integration af dataTil sidst blev der genereret 800.000 prøver af høj kvalitet, herunder ca. 600.000 inferensdata og ca. 200.000 generelle data.
Ⅳ.Destillationsproces
Lærer- og elevroller:
- DeepSeek-R1 som lærermodel;
- Modeller i Qwen-serien som elevmodel.
Træningstrin:
Først datainput: Du skal indtaste spørgsmålsdelen af de 800.000 prøver i Qwen-modellen og bede den om at generere en komplet slutningsbane (tankeproces + svar) i henhold til skabelonen. Dette er et meget vigtigt trin
Dernæst tabsberegning: Sammenlign det output, der genereres af elevmodellen, med lærermodellens inferensbane, og juster tekstsekvensen gennem supervised fine-tuning (SFT). Hvis du ikke er sikker på, hvad SFT er, håber jeg, at du vil søge efter dette nøgleord for at lære mere
Gennemfør parameteropdateringer for elevens større model: Optimer Qwen-modellens parametre gennem backpropagation for at tilnærme sig lærermodellens output.
Ved at gentage denne træningsproces flere gange sikres det, at viden overføres i tilstrækkelig grad. På den måde opnås det oprindelige mål med træningen. Vi vil give dig et eksempel for at demonstrere dette, og vi håber, at du vil forstå det
Ⅴ. Eksempel på demonstration
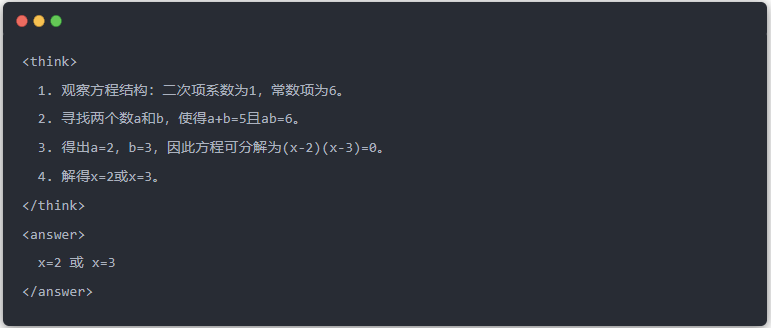
Artiklen demonstrerer destillationseffekten gennem en specifik ligningsløsningsopgave (solve equation):
- Standardoutput fra lærermodellen:
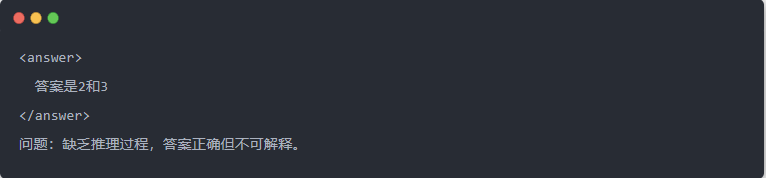
- Qwen-7B output før destillation:
- Qwen-7B output efter destillation:
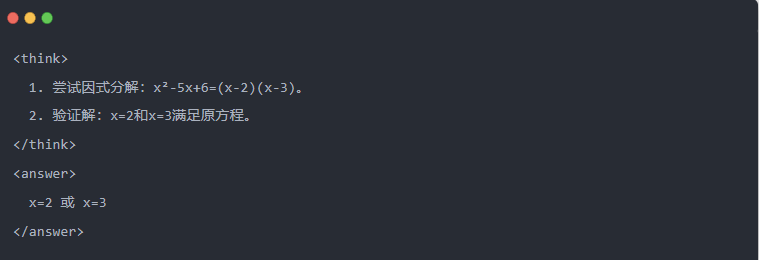
- Optimeret løsning: Der genereres en struktureret slutningsproces, og svaret er det samme som lærermodellen.
Ⅵ. Sammenfatning
Gennem vidensdestillation overføres DeepSeek-R1's slutningsevne effektivt til Qwen-serien af små modeller. Denne proces fokuserer på templated output og rejection sampling. Gennem struktureret datagenerering og raffineret træning kan små modeller også udføre komplekse inferensopgaver i ressourcebegrænsede scenarier. Denne teknologi giver en vigtig reference til letvægtsudrulning af AI-modeller.


