

DelGPT-4o-billede er et storstilet datasæt til billedgenerering af høj kvalitet, hvor alle billeder genereres ved hjælp af GPT-4os billedgenereringsfunktioner.
Dette datasæt har til formål at kombinere fordelene ved open source multimodale modeller med GPT-4os styrker inden for skabelse af visuelt indhold.
Den indeholder 45.000 tekst-til-billede- og 46.000 billede-til-tekst-eksempler, hvilket gør den til en praktisk ressource til forbedring af multimodale modeller i forbindelse med billedgenerering og redigeringsopgaver.

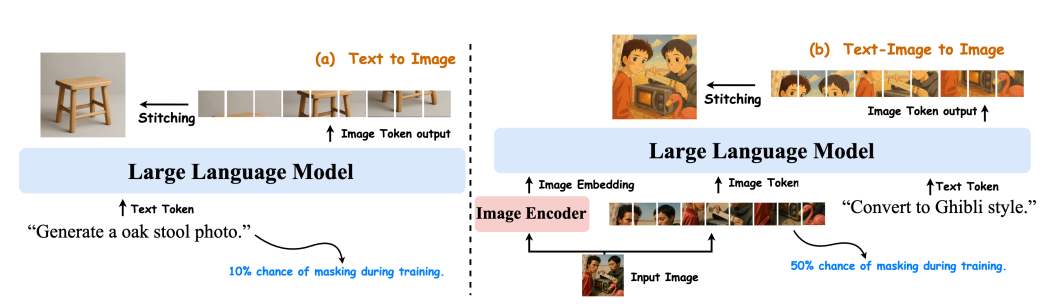
Janus-4o er en multimodal LLM, der er i stand til at generere tekst-til-billede og tekst+billede-til-billede. Den er baseret på Janus-Pro og finjusteret ved hjælp af ShareGPT-4o-Image-datasættet. Sammenlignet med Janus-Pro introducerer Janus-4o tekst+billede-til-billede-genereringsfunktioner og opnår betydelige forbedringer i tekst-til-billede-generering.
Oversigt over datasæt
ShareGPT-4o-Image-datasættet indeholder 91.000 GPT-4o-billedgenereringseksempler, kategoriseret som følger:
- Tekst-til-billede: 45.717
- Tekst plus billede til billede: 46.539
Relaterede links
Kode: github klik her
Model: Hent ShareGPT-4o-Image-modellen
Papir: klik her
Papirintroduktion
Nylige fremskridt inden for multimodale genereringsmodeller har åbnet op for realistisk, instruktionsjusteret billedgenerering. Imidlertid forbliver førende systemer som GPT-4o-Image proprietære og utilgængelige.
For at gøre disse funktioner tilgængelige for offentligheden introducerer artiklen ShareGPT-4o-Image, det første datasæt, der indeholder 45.000 tekst-til-billede og 46.000 tekst-plus-billede-til-billede eksempler, alle syntetiseret ved hjælp af GPT-4os billedgenereringsfunktioner for at forfine dets avancerede billedgenereringsevner. Ved hjælp af dette datasæt udviklede artiklen Janus-4o, en multimodal stor sprogmodel, der er i stand til tekst-til-billede og tekst-plus-billede-til-billede generering.
Janus-4o forbedrer ikke blot tekst-til-billede-genereringsfunktionerne betydeligt i forhold til sin forgænger Janus-Pro, men introducerer også tekst-plus-billede-til-billede-genereringsfunktioner. Bemærkelsesværdigt opnår den imponerende ydeevne i at generere billeder fra tekst og billeder fra bunden ved hjælp af kun 91K syntetiske prøver og trænet i 6 timer på en 8×A800 GPU-maskine.
Vi håber, at udgivelsen af ShareGPT-4o-Image og Janus-4o vil fremme åben forskning inden for fotorealistisk, instruktionsafstemt billedgenerering.
Metodeoversigt
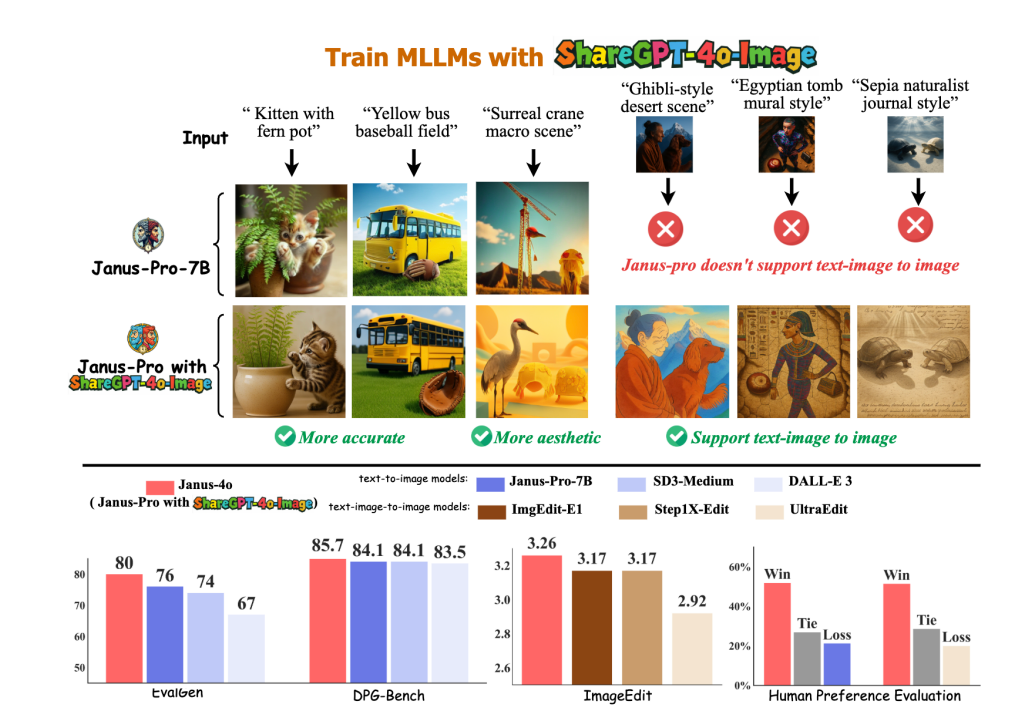
ShareGPT-4o-Image forbedrer billedgenereringsydeevnen. Ved at finjustere Janus-Pro med ShareGPT-4o-Image genererede vi Janus-4o, som viser en betydeligt forbedret billedgenereringsydelse. Janus-4o understøtter også tekst-til-billede og billede-til-billede-generering og overgår andre benchmarks med kun 91.000 træningsprøver.
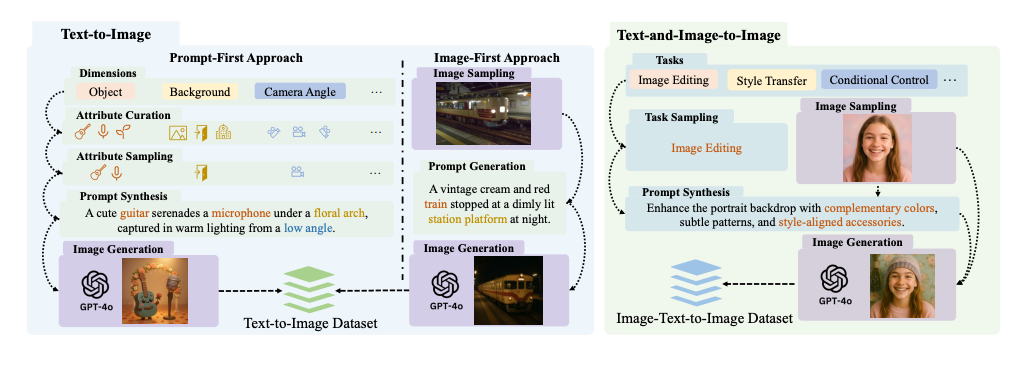
Oversigt over Janus-4o-modellen. Modellen er baseret på Janus-Pro og konstrueret ved at finjustere den på ShareGPT-4o-Image. Den inkorporerer forbedringer, der understøtter tekst-til-billede og billede-til-billede-generering. Både tekst-til-billede og tekst-til-billede-opgaver trænes i fællesskab.
Eksperimentelle resultater

Konklusioner
ShareGPT-4o-Image er det første datasæt i stor skala, der er i stand til at indfange GPT-4os avancerede billedgenereringsfunktioner inden for tekst-til-billede og tekst-til-billede-generering. Baseret på dette datasæt udviklede artiklen Janus-4o, en maskinlæringsmodel (MLLM), der er i stand til at generere billeder i høj kvalitet fra ren tekst eller billed-tekst-kombinationer.
Janus-4o opnår betydelige forbedringer i tekst-til-billede-generering og opnår yderst konkurrencedygtige resultater i tekst-til-billede-opgaver, hvilket demonstrerer den høje kvalitet og praktiske anvendelighed af ShareGPT-4o-Image.
Takket være effektiviteten af selvregressiv billedgenerering baseret på MLLM kan Janus-4o trænes på bare 6 timer på en 8×A800 GPU-maskine og opnår betydelige ydeevneforbedringer med ekstremt lave beregningskrav.



