DeepSeek har opdateret sin hjemmeside.
I de tidlige timer af nytårsaften annoncerede DeepSeek pludselig på GitHub, at Janus-projektrummet havde åbnet kilden til Janus-Pro-modellen og den tekniske rapport.
Lad os først fremhæve et par vigtige punkter:
- Den Janus-Pro-model udgivet denne gang er en multimodal model, der kan samtidig udføre multimodal forståelse og billedgenereringsopgaver. Den har i alt to parameterversioner, Janus-Pro-1B og Janus-Pro-7B.
- Den centrale innovation i Janus-Pro er at afkoble multimodal forståelse og generering, to forskellige opgaver. Det gør det muligt at udføre disse to opgaver effektivt i den samme model..
- Janus-Pro er i overensstemmelse med Janus-modelarkitekturen, som DeepSeek udgav i oktober sidste år, men på det tidspunkt havde Janus ikke meget volumen. Dr. Charles, en algoritmeekspert inden for synsområdet, fortalte os, at den tidligere Janus var "gennemsnitlig" og "ikke så god som DeepSeeks sprogmodel".

Den skal løse branchens svære problem: at balancere multimodal forståelse og billedgenerering.
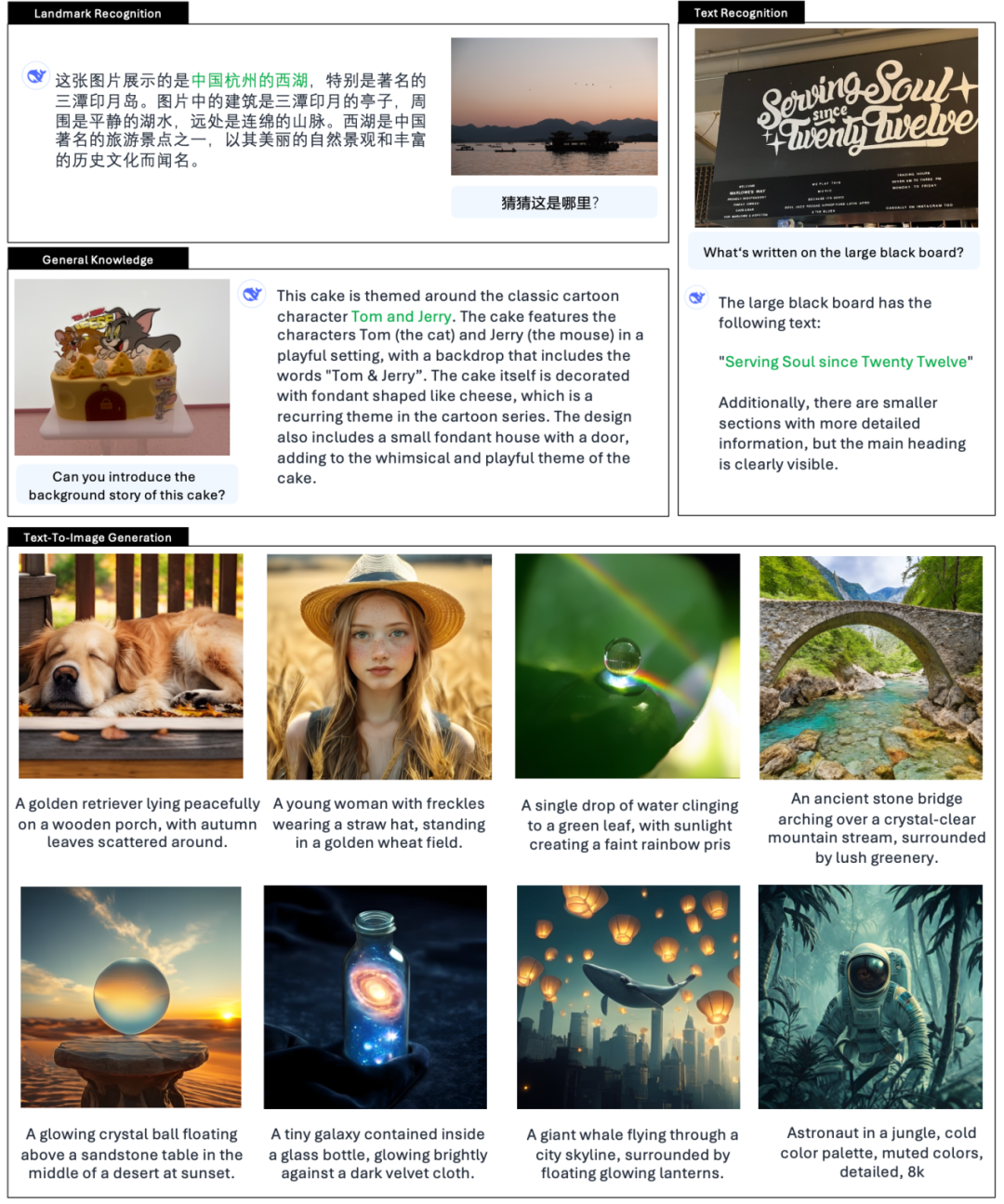
Ifølge den officielle introduktion af DeepSeek, Janus-Pro kan ikke kun forstå billeder, uddrage og forstå teksten i billederne, men også generere billeder på samme tid.
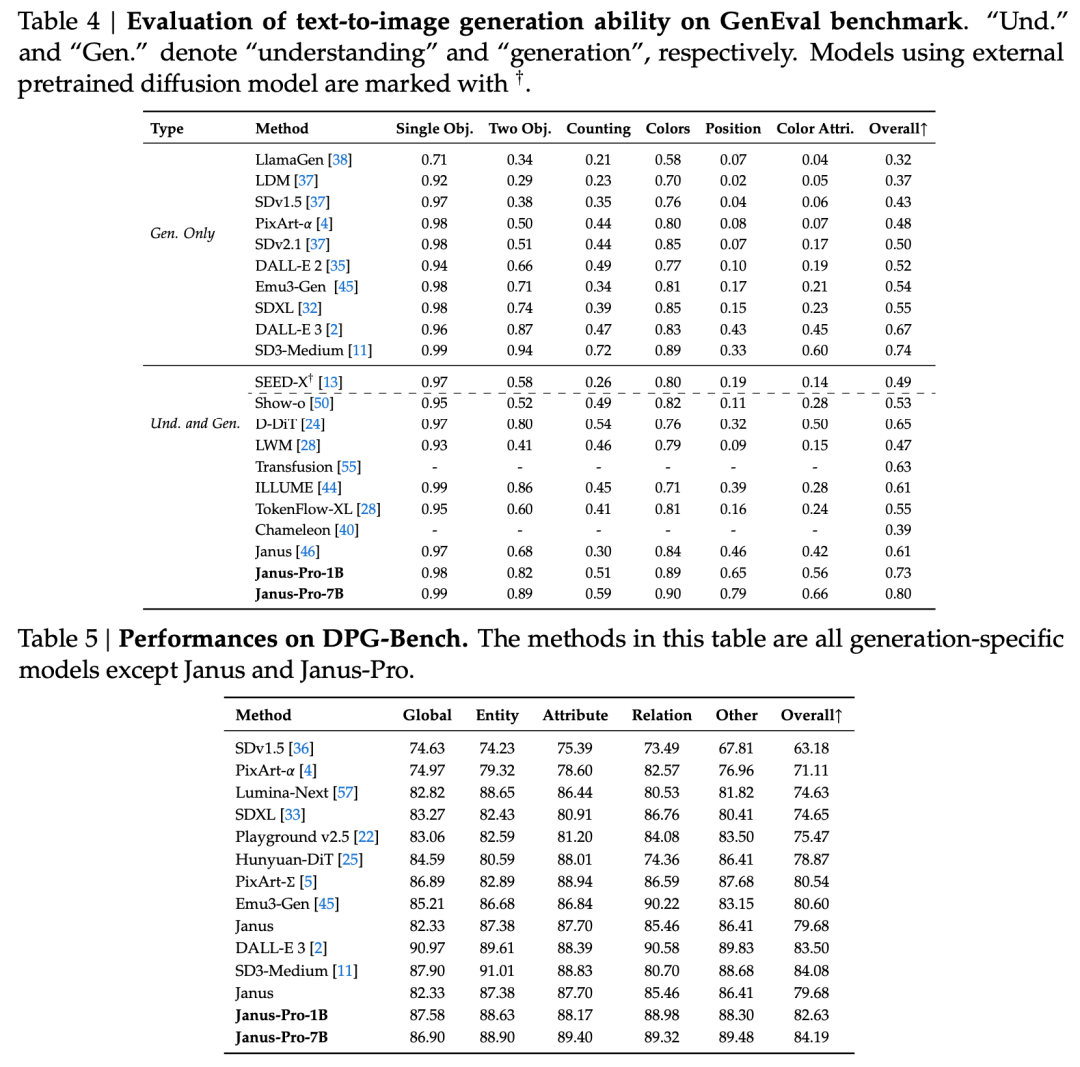
Den tekniske rapport nævner, at sammenlignet med andre modeller af samme type og størrelsesorden er Janus-Pro-7B's score på GenEval- og DPG-Bench-testsættene overstiger andre modeller som SD3-Medium og DALL-E 3.
Embedsmanden giver også eksempler 👇:
Der er også mange netbrugere på X, der afprøver de nye funktioner.

Men der er også lejlighedsvise nedbrud.
Ved at konsultere de tekniske artikler på DeepSeekfandt vi ud af, at Janus Pro er en optimering baseret på Janus, som blev udgivet for tre måneder siden.
Den centrale innovation i denne serie af modeller er at afkoble visuelle forståelsesopgaver fra visuelle genereringsopgaver, så effekten af de to opgaver kan afbalanceres.
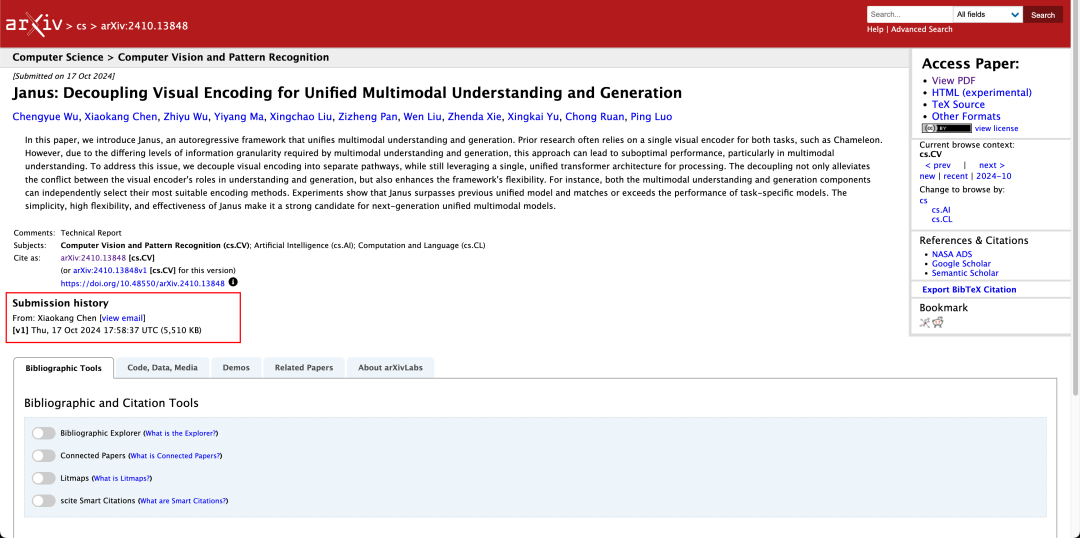
Det er ikke ualmindeligt, at en model kan udføre multimodal forståelse og generering på samme tid. D-DiT og TokenFlow-XL i dette testsæt har begge denne evne.
Men det, der er karakteristisk for Janus, er, at Ved at afkoble behandlingen afbalancerer en model, der kan udføre multimodal forståelse og generering, effektiviteten af de to opgaver.
At afbalancere effektiviteten af de to opgaver er et vanskeligt problem i branchen. Tidligere var tanken at bruge den samme koder til at implementere multimodal forståelse og generering så meget som muligt.
Fordelene ved denne tilgang er en enkel arkitektur, ingen overflødig implementering og en tilpasning til tekstmodeller (som også bruger de samme metoder til at opnå tekstgenerering og tekstforståelse). Et andet argument er, at denne sammensmeltning af flere evner kan føre til en vis grad af emergens.
Men faktisk vil de to opgaver komme i konflikt efter sammensmeltning af generering og forståelse - billedforståelse kræver, at modellen abstraherer i høje dimensioner og udtrækker billedets kernesemantik, som er forudindtaget mod det makroskopiske. Billedgenerering fokuserer på den anden side på at udtrykke og generere lokale detaljer på pixelniveau.
Industriens sædvanlige praksis er at prioritere billedgenereringsfunktioner. Det resulterer i multimodale modeller, der kan generere billeder af højere kvalitet, men resultaterne af billedforståelsen er ofte middelmådige.
Janus' afkoblede arkitektur og Janus-Pro's optimerede træningsstrategi
Janus' afkoblede arkitektur gør det muligt for modellen at afbalancere opgaverne med at forstå og generere på egen hånd.
Ifølge resultaterne i den officielle tekniske rapport klarer Janus-Pro-7B sig godt i flere testsæt, uanset om det drejer sig om multimodal forståelse eller billedgenerering.

For multimodal forståelse, Janus-Pro-7B opnåede førstepladsen i fire af de syv evalueringsdatasæt og andenpladsen i de resterende tre, lidt efter den bedst placerede model.
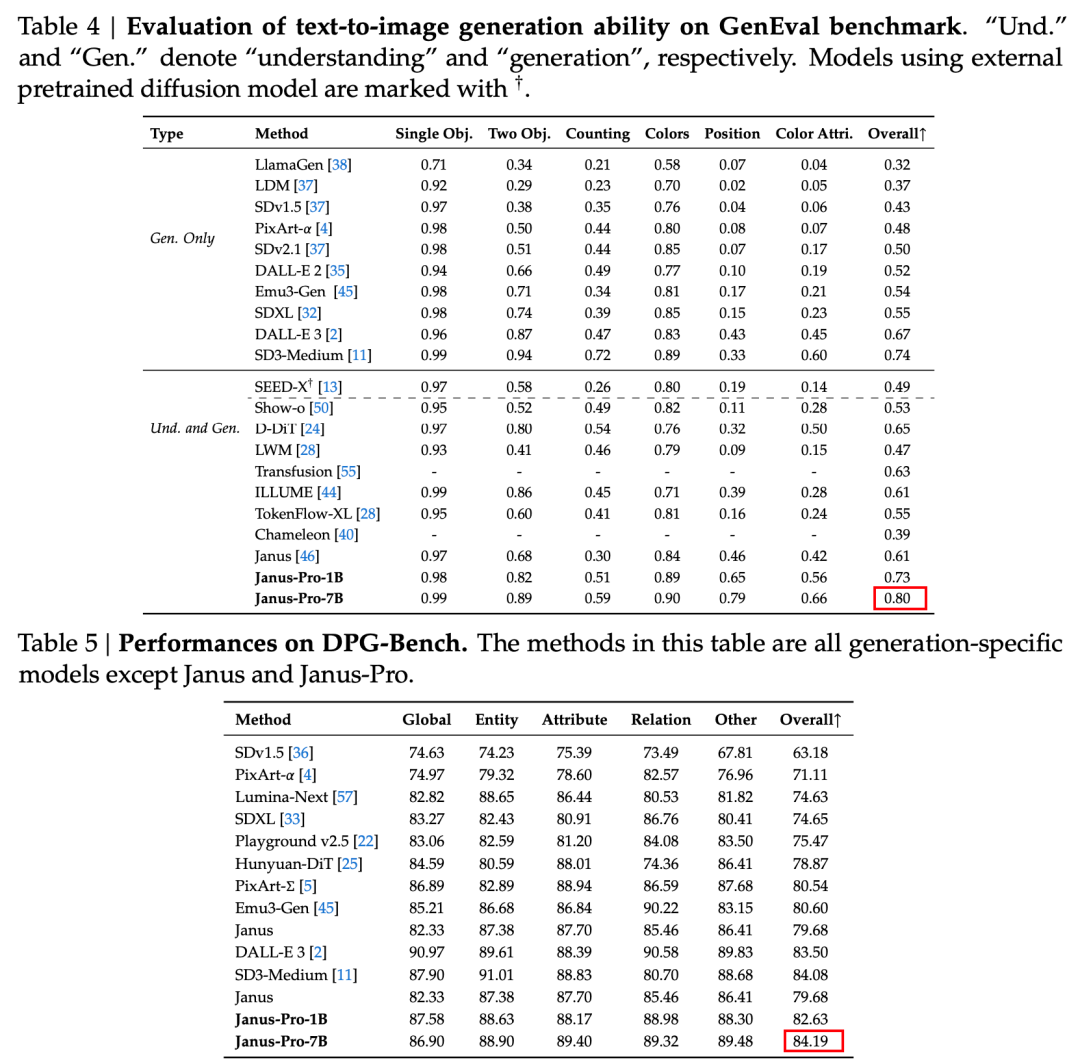
Til billedgenerering, Janus-Pro-7B opnåede førstepladsen i den samlede score på både GenEval- og DPG-Bench-evalueringsdatasættene.
Denne multi-tasking-effekt skyldes hovedsageligt Janus-seriens brug af to visuelle koder til forskellige opgaver:
- Forståelse af enkoder: bruges til at udtrække semantiske funktioner i billeder til billedforståelsesopgaver (såsom billedspørgsmål og -svar, visuel klassificering osv.).
- Generativ koder: konverterer billeder til en diskret repræsentation (f.eks. ved hjælp af en VQ-koder) til tekst-til-billede-genereringsopgaver.
Med denne arkitektur, Modellen kan uafhængigt optimere hver enkelt koders ydeevne, så multimodale forståelses- og genereringsopgaver hver især kan opnå deres bedste ydeevne.
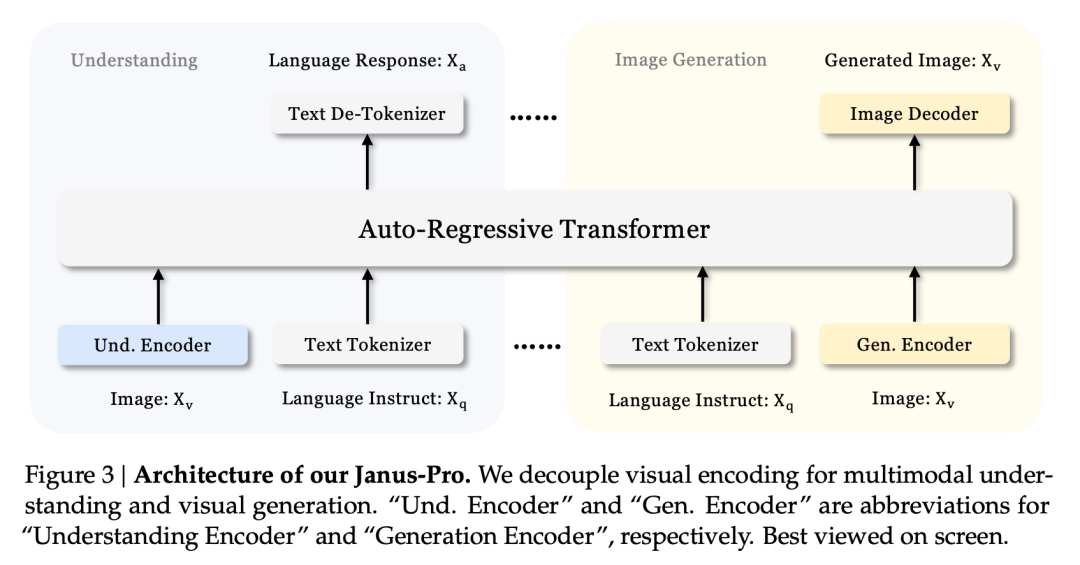
Denne afkoblede arkitektur er fælles for Janus-Pro og Janus. Så hvilke iterationer har Janus-Pro haft i de sidste par måneder?
Som det fremgår af resultaterne af evalueringssættet, har den nuværende udgave af Janus-Pro-1B en forbedring på ca. 10% til 20% i resultaterne af forskellige evalueringssæt sammenlignet med den tidligere Janus. Janus-Pro-7B har den højeste forbedring på ca. 45% sammenlignet med Janus efter udvidelse af antallet af parametre.

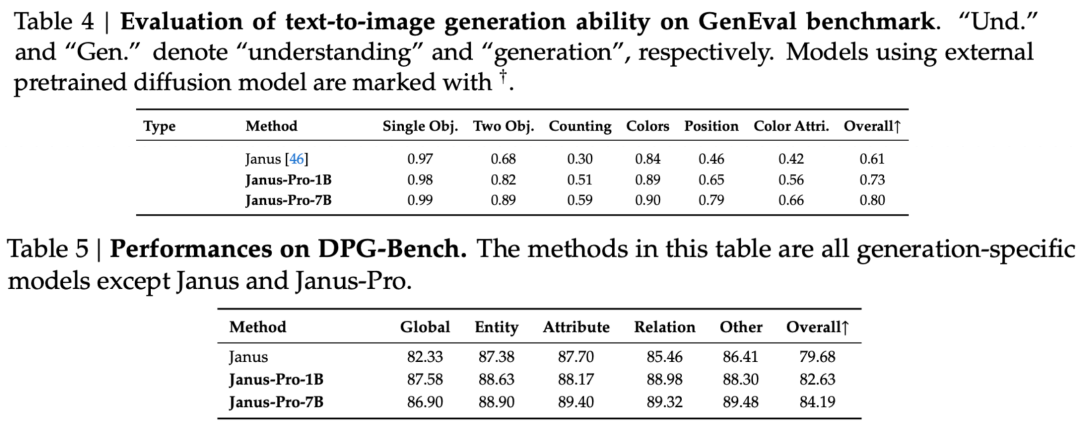
Med hensyn til træningsdetaljer hedder det i den tekniske rapport, at den nuværende udgave af Janus-Pro, sammenlignet med den tidligere Janus-model, bevarer det centrale afkoblede arkitekturdesign og derudover itererer på parameterstørrelse, træningsstrategi og træningsdata.
Lad os først se på parametrene.
Den første version af Janus havde kun 1,3B parametre, og den nuværende udgave af Pro indeholder modeller med 1B og 7B parametre.
Disse to størrelser afspejler Janus-arkitekturens skalerbarhed. 1B-modellen, som er den letteste, er allerede blevet brugt af eksterne brugere til at køre i browseren ved hjælp af WebGPU.
Der er også den træningsstrategi.
I tråd med Janus' opdeling i træningsfaser har Janus Pro i alt tre træningsfaser, og artiklen opdeler dem direkte i fase I, fase II og fase III.
Samtidig med at de grundlæggende træningsideer og træningsmål i hver fase er bevaret, har Janus-Pro forbedret træningens varighed og træningsdata i de tre faser. I det følgende beskrives de specifikke forbedringer i de tre faser:
Fase I - Længere træningstid
Sammenlignet med Janus har Janus-Pro forlænget træningstiden i fase I, især i træningen af adaptere og billedhoveder i den visuelle del. Det betyder, at indlæringen af visuelle funktioner har fået mere træningstid, og det er håbet, at modellen fuldt ud kan forstå de detaljerede funktioner i billeder (såsom pixel-til-semantisk kortlægning).
Denne udvidede træning er med til at sikre, at træningen af den visuelle del ikke forstyrres af andre moduler.
Fase II - Fjernelse af ImageNet-data og tilføjelse af multimodale data
I fase II henviste Janus tidligere til PixArt og trænede i to dele. Den første del blev trænet ved hjælp af ImageNet-datasættet til billedklassifikationsopgaven, og den anden del blev trænet ved hjælp af almindelige tekst-til-billede-data. Omkring to tredjedele af tiden i fase II blev brugt på at træne i den første del.
Janus-Pro fjerner ImageNet-træningen i fase II. Dette design gør det muligt for modellen at fokusere på tekst-til-billed-data under Stage II-træningen. Ifølge eksperimentelle resultater kan dette forbedre udnyttelsen af tekst-til-billed-data betydeligt.
Ud over justeringen af træningsmetodens design er det træningsdatasæt, der bruges i fase II, ikke længere begrænset til en enkelt billedklassificeringsopgave, men inkluderer også flere andre typer multimodale data, såsom billedbeskrivelse og dialog, til fælles træning.
Fase III - Optimering af dataforholdet
I fase III-træning justerer Janus-Pro forholdet mellem forskellige typer træningsdata.
Tidligere var forholdet mellem multimodale forståelsesdata, almindelige tekstdata og tekst-til-billed-data i de træningsdata, der blev brugt af Janus i fase III, 7:3:10. Janus-Pro reducerer forholdet mellem de to sidstnævnte typer data og justerer forholdet mellem de tre typer data til 5:1:4, det vil sige, at der lægges mere vægt på den multimodale forståelsesopgave.
Lad os se på træningsdataene.
Sammenlignet med Janus øger Janus-Pro denne gang markant mængden af højkvalitets syntetiske data.
Det udvider mængden og variationen af træningsdata til multimodal forståelse og billedgenerering.
Udvidelse af multimodale forståelsesdata:
Janus-Pro refererer til DeepSeek-VL2-datasættet under træningen og tilføjer omkring 90 millioner ekstra datapunkter, herunder ikke kun billedbeskrivelsesdatasæt, men også datasæt med komplekse scener som tabeller, diagrammer og dokumenter.
Under den overvågede finjusteringsfase (fase III) fortsætter den med at tilføje datasæt relateret til MEME-forståelse og forbedring af dialog (herunder kinesisk dialog).
Udvidelse af visuelle generationsdata:
De oprindelige data fra den virkelige verden havde dårlig kvalitet og høje støjniveauer, hvilket fik modellen til at producere ustabile outputs og billeder af utilstrækkelig æstetisk kvalitet i tekst-til-billede-opgaver.
Janus-Pro tilføjede ca. 72 millioner nye højæstetiske syntetiske data til træningsfasen, hvilket bragte forholdet mellem rigtige data og syntetiske data i førtræningsfasen op på 1:1.
Prompterne til de syntetiske data blev alle taget fra offentlige ressourcer. Eksperimenter har vist, at tilføjelsen af disse data får modellen til at konvergere hurtigere, og de genererede billeder har tydelige forbedringer i stabilitet og visuel skønhed.
Fortsættelsen af en effektivitetsrevolution?
Alt i alt har DeepSeek med denne udgivelse bragt effektivitetsrevolutionen til visuelle modeller.
I modsætning til visuelle modeller, der fokuserer på en enkelt funktion, eller multimodale modeller, der favoriserer en bestemt opgave, afbalancerer Janus-Pro virkningerne af de to hovedopgaver billedgenerering og multimodal forståelse i den samme model.
På trods af sine små parametre slog den desuden OpenAI DALL-E 3 og SD3-Medium i evalueringen.
Udvidet til jorden behøver virksomheden kun at implementere en model for direkte at implementere de to funktioner til billedgenerering og -forståelse. Sammen med en størrelse på kun 7B er vanskelighederne og omkostningerne ved implementering meget lavere.
I forbindelse med de tidligere udgivelser af R1 og V3 udfordrer DeepSeek de eksisterende spilleregler med "kompakt arkitektonisk innovation, letvægtsmodeller, open source-modeller og ekstremt lave uddannelsesomkostninger". Det er årsagen til panikken blandt vestlige teknologigiganter og selv Wall Street.
Lige nu har Sam Altman, som er blevet revet med af den offentlige mening i flere dage, endelig reageret positivt på oplysninger om DeepSeek på X - samtidig med at han roste R1, sagde han, at OpenAI vil komme med nogle meddelelser.