På tærsklen til forårsfestivalen blev DeepSeek-R1-modellen udgivet. Med sin rene RL-arkitektur har den lært af CoT's store innovationer og klarer sig bedre end ChatGPT i matematik, kode og logisk ræsonnement.
Derudover har dens open source-modelvægte, lave træningsomkostninger og billige API-priser gjort DeepSeek til et hit på internettet, hvilket endda fik NVIDIA's og ASML's aktiekurser til at styrtdykke i en periode.
Mens populariteten eksploderede, udgav DeepSeek også en opdateret version af den multimodale store model Janus (Janus), Janus-Pro, som arver den samlede arkitektur fra den tidligere generation af multimodal forståelse og generering og optimerer træningsstrategien ved at skalere træningsdata og modelstørrelse, hvilket giver en stærkere ydeevne.

Janus-Pro
Janus-Pro er en samlet multimodal sprogmodel (MLLM), der samtidig kan behandle multimodale forståelsesopgaver og genereringsopgaver, dvs. den kan forstå indholdet af et billede og også generere tekst.
Den afkobler de visuelle kodere til multimodal forståelse og generering (dvs. der bruges forskellige tokenizers til input til billedforståelse og input og output til billedgenerering) og behandler dem ved hjælp af en samlet autoregressiv transformer.
Som en avanceret multimodal forståelses- og genereringsmodel er den en opgraderet version af den tidligere Janus-model.
I den romerske mytologi er Janus (Janus) en skytsgud med to ansigter, som symboliserer modsigelse og overgang. Han har to ansigter, hvilket også antyder, at Janus-modellen kan forstå og generere billeder, hvilket er meget passende. Så hvad er det helt præcist, PRO har opgraderet?
Janus, som er en lille model på 1.3B, er mere en preview-version end en officiel version. Den udforsker forenet multimodal forståelse og generering, men har mange problemer, såsom ustabile billedgenereringseffekter, store afvigelser fra brugerinstruktioner og utilstrækkelige detaljer.
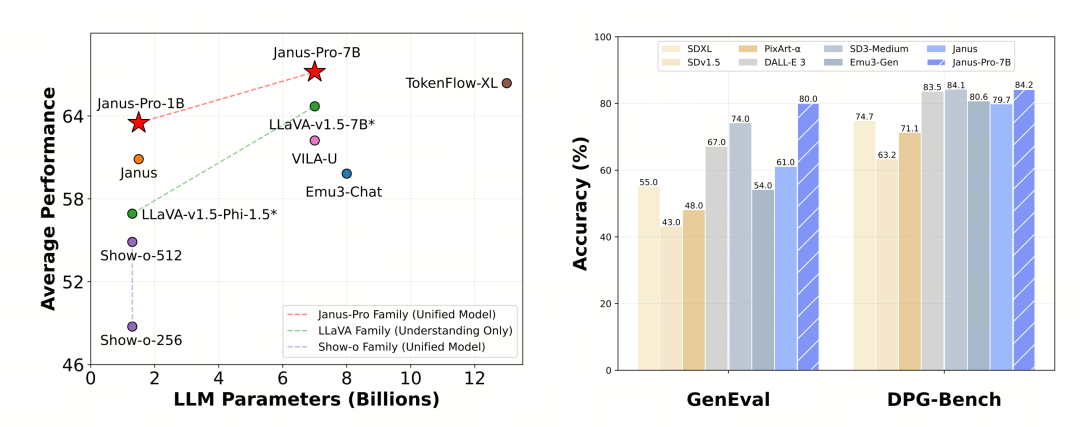
Pro-versionen optimerer træningsstrategien, øger træningsdatasættet og giver en større model (7B) at vælge imellem, samtidig med at den giver en 1B-model.
Modelarkitektur
Jaus-Pro og Janus er identiske med hensyn til modelarkitektur. (Kun 1,3B! Janus forener multimodal forståelse og generering)
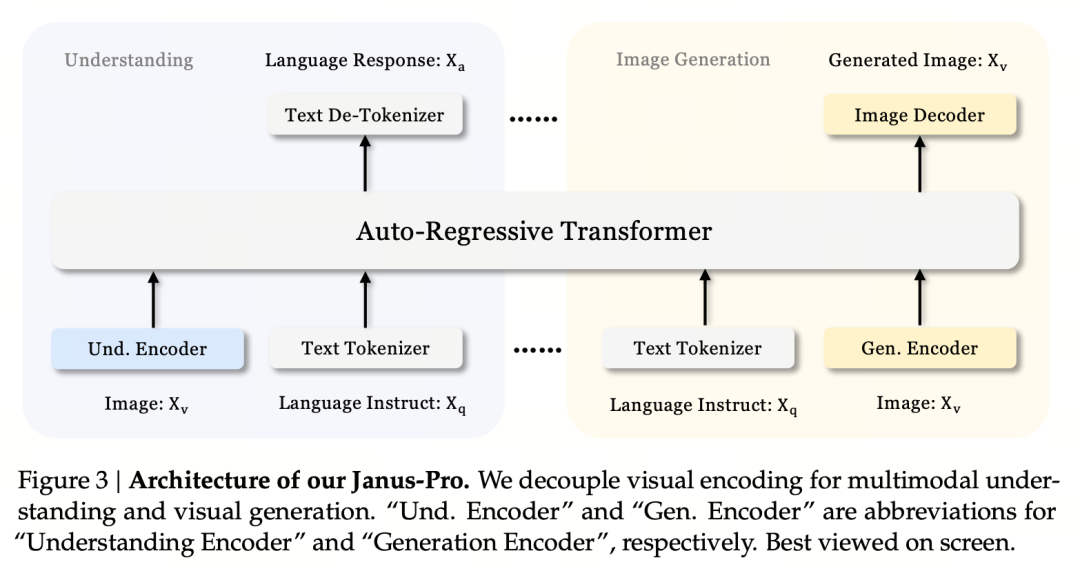
Det centrale designprincip er at afkoble visuel kodning for at understøtte multimodal forståelse og generering. Janus-Pro koder det originale billede/tekst-input separat, udtrækker højdimensionelle funktioner og behandler dem gennem en samlet autoregressiv transformer.
Multimodal billedforståelse bruger SigLIP til at kode billedfunktioner (blå koder i figuren ovenfor), og genereringsopgaven bruger VQ tokenizer til at diskretisere billedet (gul koder i figuren ovenfor). Til sidst sendes alle funktionssekvenser til LLM til behandling.
Træningsstrategi
Med hensyn til træningsstrategi har Janus-Pro foretaget flere forbedringer. Den gamle version af Janus brugte en tretrins træningsstrategi, hvor trin I træner inputadapteren og billedgenereringshovedet til billedforståelse og billedgenerering, trin II udfører samlet fortræning, og trin III finjusterer forståelseskoderen på dette grundlag. (Janus' træningsstrategi er vist i figuren nedenfor).
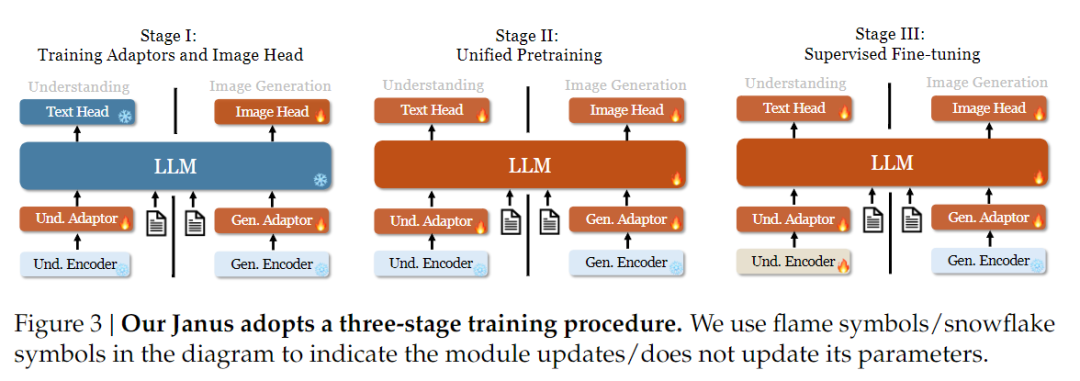
Denne strategi bruger dog PixArt-metoden til at opdele træningen af tekst-til-billede-generering i fase II, hvilket resulterer i lav beregningseffektivitet.
Til dette formål forlængede vi træningstiden i fase I og tilføjede træning med ImageNet-data, så modellen effektivt kan modellere pixelafhængigheder med faste LLM-parametre. I fase II kasserede vi ImageNet-data og brugte direkte tekst-billedpar-data til at træne, hvilket forbedrer træningseffektiviteten. Derudover justerede vi dataforholdet i fase III (multimodal:kun tekst:visuel-semantisk grafdata fra 7:3:10 til 5:1:4), hvilket forbedrede den multimodale forståelse, samtidig med at den visuelle genereringsevne blev bevaret.
Skalering af træningsdata
Janus-Pro skalerer også Janus' træningsdata med hensyn til multimodal forståelse og visuel generering.
Multimodal forståelse: Fase II-prætræningsdataene er baseret på DeepSeek-VL2 og omfatter ca. 90 millioner nye prøver, herunder data om billedtekster (f.eks. YFCC) og data om tabel-, diagram- og dokumentforståelse (f.eks. Docmatix).
Den tredje fase med overvåget finjustering introducerer yderligere MEME-forståelse, kinesiske dialogdata osv. for at forbedre modellens ydeevne inden for multi-task-behandling og dialogfunktioner.
Visuel generering: Tidligere versioner brugte reelle data af lav kvalitet og med meget støj, hvilket påvirkede stabiliteten og æstetikken i de tekstgenererede billeder.
Janus-Pro introducerer omkring 72 millioner syntetiske æstetiske data, hvilket bringer forholdet mellem reelle data og syntetiske data op på 1:1. Eksperimenter har vist, at syntetiske data fremskynder modelkonvergensen og forbedrer stabiliteten og den æstetiske kvalitet af de genererede billeder betydeligt.
Skalering af modeller
Janus Pro udvider modelstørrelsen til 7B, mens den tidligere version af Janus brugte 1,5B DeepSeek-LLM til at verificere effektiviteten af at afkoble visuel kodning. Eksperimenter viser, at en større LLM markant fremskynder konvergensen af multimodal forståelse og visuel generering, hvilket yderligere bekræfter metodens stærke skalerbarhed.

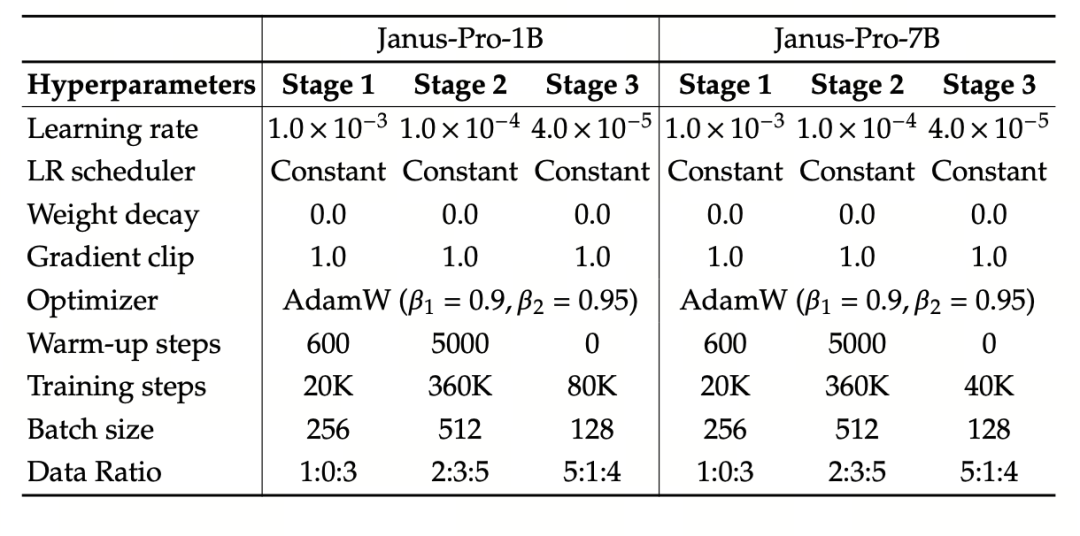
Eksperimentet bruger DeepSeek-LLM (1,5B og 7B, der understøtter en maksimal sekvens på 4096) som den grundlæggende sprogmodel. Til den multimodale forståelsesopgave bruges SigLIP-Large-Patch16-384 som den visuelle koder, ordbogsstørrelsen på koderen er 16384, billednedsamplingsmultiplen er 16, og både forståelses- og genereringsadapterne er to-lags MLP'er.
Fase II-træning bruger en 270K tidlig stopstrategi, alle billeder justeres ensartet til en opløsning på 384×384, og sekvenspakning bruges til at forbedre træningseffektiviteten. Janus-Pro er trænet og evalueret ved hjælp af HAI-LLM. 1.5B/7B-versionerne blev trænet på 16/32 noder (8×Nvidia A100 40GB pr. node) i henholdsvis 9/14 dage.
Evaluering af modeller
Janus-Pro blev evalueret separat i multimodal forståelse og generering. Samlet set kan forståelsen være lidt svag, men den anses for at være fremragende blandt open source-modeller af samme størrelse (gæt på, at den i høj grad er begrænset af den faste inputopløsning og OCR-funktioner).
Janus-Pro-7B scorede 79,2 i MMBench-benchmark-testen, hvilket er tæt på niveauet for førsteklasses open source-modeller (samme størrelse på InternVL2.5 og Qwen2-VL er omkring 82 point). Det er dog en god forbedring i forhold til den forrige generation af Janus.
Med hensyn til billedgenerering er forbedringen i forhold til den forrige generation endnu mere markant, og det anses for at være et fremragende niveau blandt open source-modeller. Janus-Pro's score i GenEval-benchmark-testen (0,80) overgår også modeller som DALL-E 3 (0,67) og Stable Diffusion 3 Medium (0,74).