
Ⅰ. Was ist Wissensdestillation?
Die Wissensdestillation ist eine Modellkomprimierungstechnik, die dazu dient, Wissen von einem großen, komplexen Modell (dem Lehrermodell) auf ein kleines Modell (das Schülermodell) zu übertragen.
Das Grundprinzip besteht darin, dass das Lehrermodell dem Schülermodell durch Vorhersage von Ergebnissen (z. B. Wahrscheinlichkeitsverteilungen oder Inferenzprozesse) etwas beibringt und das Schülermodell seine Leistung durch Lernen aus diesen Vorhersagen verbessert.
Diese Methode eignet sich besonders für Geräte mit eingeschränkten Ressourcen wie Mobiltelefone oder eingebettete Geräte.
II. Kernbegriffe
2.1 Entwurf der Vorlage
- Vorlage: Ein strukturiertes Format, das zur Standardisierung der Modellausgabe verwendet wird. Zum Beispiel
- : Markiert den Beginn des Argumentationsprozesses.
- : Markiert das Ende des Argumentationsprozesses.
- : Markiert den Anfang der endgültigen Antwort.
- : Markiert das Ende der endgültigen Antwort.
- Funktion:
- Klarheit: Wie die "Aufforderungswörter" in einer Lückentext-Frage sagt sie dem Modell: "Der Denkprozess beginnt hier und die Antwort dort".
- Konsistenz: Es wird sichergestellt, dass alle Ausgaben der gleichen Struktur folgen, was die spätere Verarbeitung und Analyse erleichtert.
- Lesbarkeit: Menschen können leicht zwischen dem Argumentationsprozess und der Antwort unterscheiden, was die Benutzererfahrung verbessert.
2.2 Der Denkweg: Die "Denkkette" der Lösung des Modells
- Trajektorie des Denkens: Die detaillierten Schritte, die das Modell bei der Lösung eines Problems ausführt, zeigen die logische Kette des Modells.
- Beispiel:
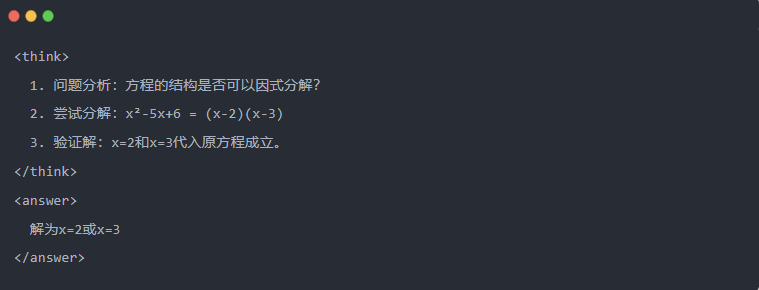
2.3 Zurückweisung von Stichproben: Herausfiltern guter Daten aus "Versuch und Irrtum
- Ablehnende Stichproben: Generieren Sie mehrere Kandidatenantworten und behalten Sie die guten Antworten, ähnlich wie beim Schreiben eines Entwurfs und dem anschließenden Kopieren der richtigen Antwort in einer Prüfung.
Ⅲ.Erzeugung von destillierten Daten
Der erste Schritt bei der Wissensdestillation besteht darin, hochwertige "Lerndaten" zu erzeugen, aus denen kleine Modelle lernen können.
Datenquellen:
- 80% aus den Argumentationsdaten, die von DeepSeek-R1
- 20% aus den allgemeinen Aufgabendaten von DeepSeek-V3.
Verfahren zur Erzeugung von Destillationsdaten:
- Regelmäßige Filterung: prüft automatisch die Korrektheit der Antwort (z.B. ob die mathematische Antwort mit der Formel übereinstimmt).
- Überprüfung der Lesbarkeit: eliminiert gemischte Sprachen (z.B. Chinesisch und Englisch gemischt) oder lange Absätze.
- Vorlagengeführte Generierung: erfordert, dass DeepSeek-R1 Inferenz-Trajektorien entsprechend der Vorlage ausgibt.
- Filterung von Rückweisungsproben:
- Integration von DatenEs wurden schließlich 800.000 qualitativ hochwertige Stichproben erzeugt, darunter etwa 600.000 Inferenzdaten und etwa 200.000 allgemeine Daten.
Ⅳ.Destillationsverfahren
Die Rollen von Lehrern und Schülern:
- DeepSeek-R1 als Lehrermodell;
- Modelle der Qwen-Serie als Schülermodell.
Ausbildungsschritte:
Erstens, die Dateneingabe: Sie müssen den Frageteil der 800.000 Stichproben in das Qwen-Modell eingeben und es auffordern, eine vollständige Inferenzkurve (Denkprozess + Antwort) gemäß der Vorlage zu erstellen. Dies ist ein sehr wichtiger Schritt
Als Nächstes folgt die Verlustberechnung: Vergleichen Sie die vom Schülermodell erzeugte Ausgabe mit der Inferenzkurve des Lehrermodells und gleichen Sie die Textabfolge durch überwachte Feinabstimmung (SFT) ab. Wenn Sie sich nicht sicher sind, was SFT ist, suchen Sie nach diesem Stichwort, um mehr zu erfahren
Vollständige Aktualisierung der Parameter für das größere Modell des Schülers: Optimieren Sie die Parameter des Qwen-Modells durch Backpropagation, um die Ausgabe des Lehrermodells zu approximieren.
Durch die mehrfache Wiederholung dieses Ausbildungsprozesses wird sichergestellt, dass das Wissen ausreichend übertragen wird. Damit wird das ursprüngliche Ausbildungsziel erreicht. Wir werden Ihnen dies anhand eines Beispiels demonstrieren und hoffen, dass Sie es verstehen werden
Ⅴ. Beispiel Demonstration
Der Artikel demonstriert den Destillationseffekt anhand einer speziellen Gleichungslösungsaufgabe (Gleichung lösen):
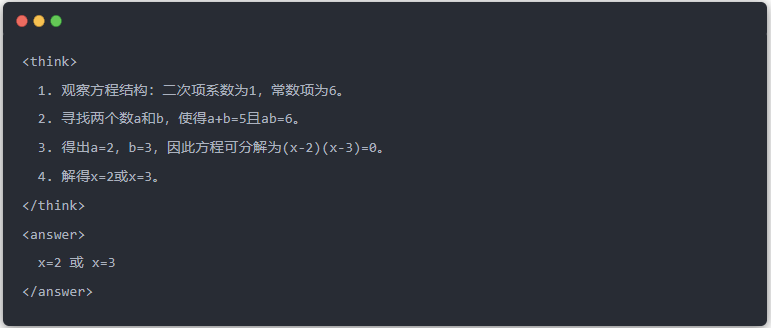
- Standardausgabe des Lehrermodells:
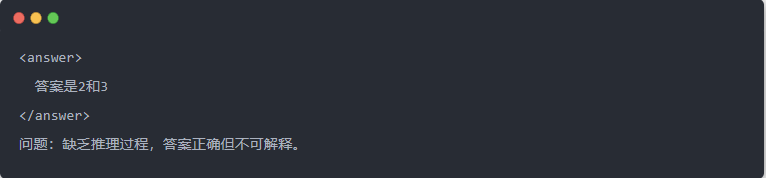
- Qwen-7B-Ausgang vor der Destillation:
- Qwen-7B-Ausgang nach der Destillation:
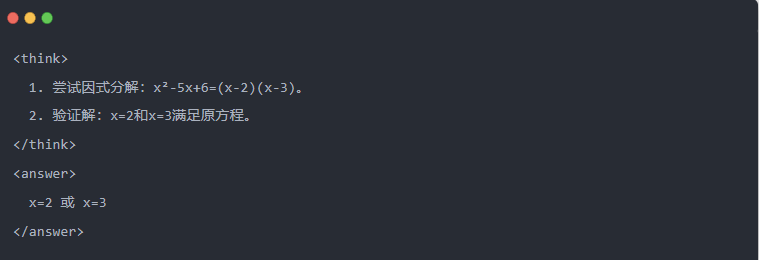
- Optimierte Lösung: Es wird ein strukturierter Schlussfolgerungsprozess generiert, und die Antwort ist dieselbe wie das Lehrermodell.
Ⅵ. Zusammenfassung
Durch Wissensdestillation wird die Inferenzfähigkeit von DeepSeek-R1 effizient auf die Qwen-Serie kleiner Modelle übertragen. Dieser Prozess konzentriert sich auf eine schablonenhafte Ausgabe und ein Rejection Sampling. Durch strukturierte Datengenerierung und verfeinertes Training können kleine Modelle auch komplexe Inferenzaufgaben in ressourcenbeschränkten Szenarien durchführen. Diese Technologie stellt eine wichtige Referenz für den leichtgewichtigen Einsatz von KI-Modellen dar.




