Am Vorabend des Frühlingsfestes wurde das Modell DeepSeek-R1 veröffentlicht. Mit seiner reinen RL-Architektur hat es von den großen Innovationen von CoT gelernt und übertrifft ChatGPT in Mathematik, Code und logischem Denken.
Darüber hinaus haben die Open-Source-Modellgewichte, die niedrigen Trainingskosten und die günstigen API-Preise DeepSeek zu einem Hit im Internet gemacht, der sogar die Aktienkurse von NVIDIA und ASML zeitweise in den Keller gehen ließ.
DeepSeek hat außerdem eine aktualisierte Version des multimodalen Großmodells Janus (Janus), Janus-Pro, veröffentlicht, die die einheitliche Architektur der vorherigen Generation des multimodalen Verstehens und Erzeugens übernimmt und die Trainingsstrategie optimiert, indem sie die Trainingsdaten und die Modellgröße skaliert und so eine höhere Leistung erzielt.

Janus-Pro
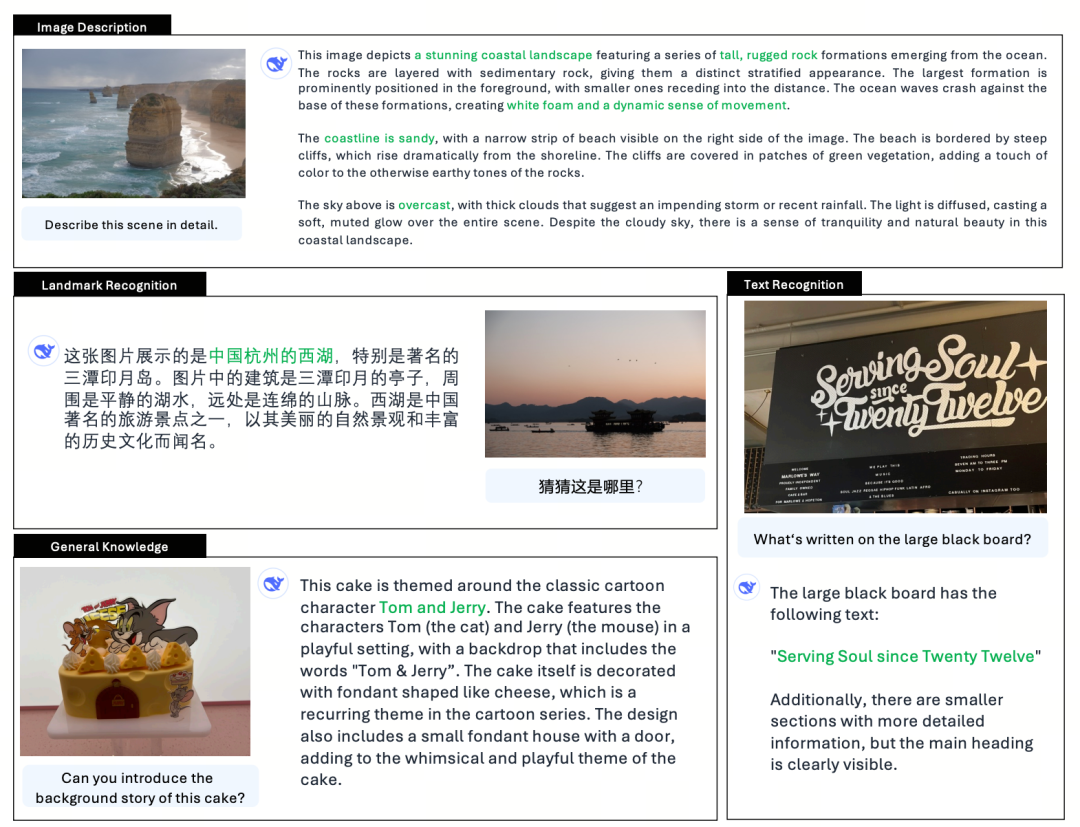
Janus-Pro ist ein einheitliches multimodales Sprachmodell (MLLM), das gleichzeitig multimodale Verstehens- und Generierungsaufgaben bearbeiten kann, d.h. es kann den Inhalt eines Bildes verstehen und auch Text generieren.
Es entkoppelt die visuellen Kodierer für multimodales Verstehen und Generieren (d.h. für den Input des Bildverstehens und den Input und Output der Bilderzeugung werden unterschiedliche Tokenizer verwendet) und verarbeitet sie mit einem einheitlichen autoregressiven Transformator.
Als fortschrittliches multimodales Verstehens- und Generierungsmodell ist es eine verbesserte Version des früheren Janus-Modells.
In der römischen Mythologie ist Janus (Janus) ein zweigesichtiger Schutzgott, der Widerspruch und Übergang symbolisiert. Er hat zwei Gesichter, was auch darauf hindeutet, dass das Janus-Modell Bilder verstehen und erzeugen kann, was sehr passend ist. Was genau hat PRO also verbessert?
Janus, als kleines Modell von 1.3B, ist eher eine Vorabversion als eine offizielle Version. Es erforscht das einheitliche multimodale Verstehen und Erzeugen, hat aber viele Probleme, wie instabile Bilderzeugungseffekte, große Abweichungen von den Benutzeranweisungen und unzureichende Details.
Die Pro-Version optimiert die Trainingsstrategie, vergrößert den Trainingsdatensatz und bietet ein größeres Modell (7B) zur Auswahl, während ein 1B-Modell bereitgestellt wird.
Modell der Architektur
Jaus-Pro und Janus sind identisch in Bezug auf die Modellarchitektur. (Nur 1.3B! Janus vereinigt multimodales Verstehen und Generieren)
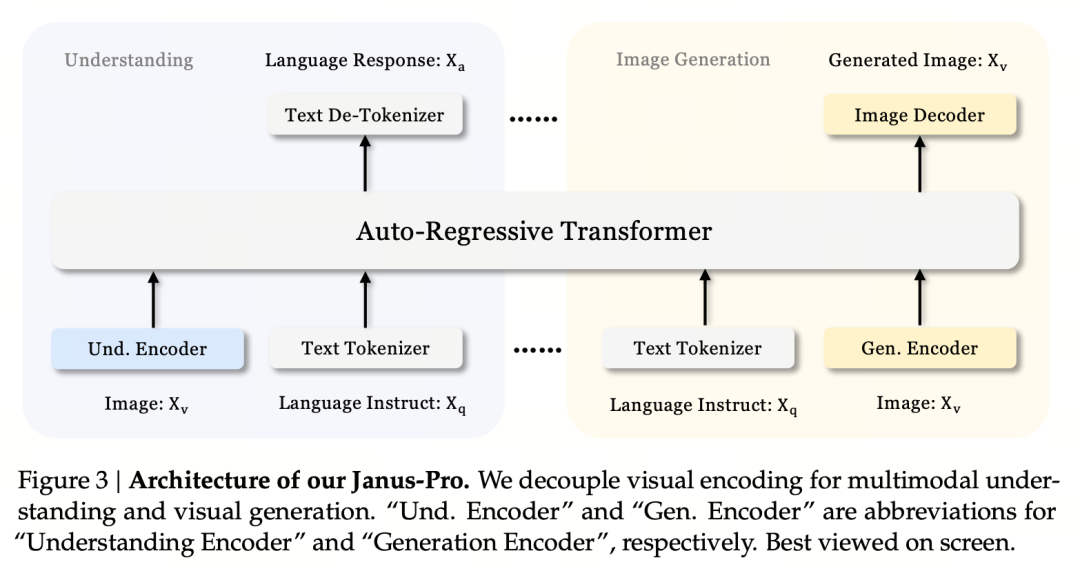
Das zentrale Konstruktionsprinzip ist die Entkopplung der visuellen Kodierung, um multimodales Verstehen und Generieren zu unterstützen. Janus-Pro kodiert die ursprüngliche Bild-/Texteingabe separat, extrahiert hochdimensionale Merkmale und verarbeitet sie durch einen vereinheitlichten autoregressiven Transformator.
Beim multimodalen Bildverständnis wird SigLIP zur Kodierung von Bildmerkmalen verwendet (blauer Kodierer in der Abbildung oben), und bei der Generierungsaufgabe wird der VQ-Tokenizer zur Diskretisierung des Bildes verwendet (gelber Kodierer in der Abbildung oben). Schließlich werden alle Merkmalssequenzen zur Verarbeitung in den LLM eingegeben
Ausbildungsstrategie
Was die Trainingsstrategie betrifft, so hat Janus-Pro weitere Verbesserungen vorgenommen. Die alte Version von Janus verwendete eine dreistufige Trainingsstrategie, bei der in Stufe I der Eingabeadapter und der Bilderzeugungskopf für das Bildverständnis und die Bilderzeugung trainiert werden, in Stufe II ein einheitliches Vortraining durchgeführt wird und in Stufe III eine Feinabstimmung des Verständnis-Encoders auf dieser Grundlage erfolgt. (Die Janus-Trainingsstrategie ist in der Abbildung unten dargestellt).
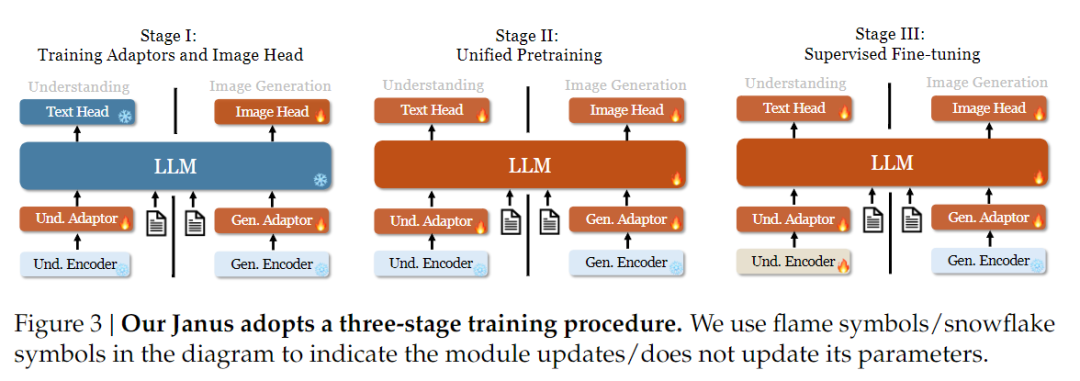
Bei dieser Strategie wird jedoch die PixArt-Methode verwendet, um das Training der Text-Bild-Erzeugung in Phase II aufzuteilen, was zu einer geringen Recheneffizienz führt.
Zu diesem Zweck verlängerten wir die Trainingszeit von Phase I und fügten ein Training mit ImageNet-Daten hinzu, so dass das Modell Pixelabhängigkeiten mit festen LLM-Parametern effektiv modellieren kann. In Phase II haben wir die ImageNet-Daten verworfen und direkt Text-Bild-Paar-Daten zum Training verwendet, was die Trainingseffizienz verbessert. Darüber hinaus haben wir das Datenverhältnis in Phase III (multimodale:reine Textdaten:visuell-semantische Graphdaten von 7:3:10 auf 5:1:4) angepasst, um das multimodale Verständnis zu verbessern und gleichzeitig die visuellen Generierungsfähigkeiten zu erhalten.
Skalierung der Trainingsdaten
Janus-Pro skaliert auch die Trainingsdaten von Janus in Bezug auf multimodales Verstehen und visuelle Erzeugung.
Multimodales Verstehen: Die Pre-Trainingsdaten der Stufe II basieren auf DeepSeek-VL2 und umfassen etwa 90 Millionen neue Samples, darunter Bildbeschriftungsdaten (wie YFCC) und Daten zum Verständnis von Tabellen, Diagrammen und Dokumenten (wie Docmatix).
In der überwachten Feinabstimmungsphase der Stufe III werden MEME-Verständnis, chinesische Dialogdaten usw. eingeführt, um die Leistung des Modells bei der Multi-Task-Verarbeitung und den Dialogfähigkeiten zu verbessern.
Visuelle Erzeugung: In früheren Versionen wurden reale Daten von geringer Qualität und starkem Rauschen verwendet, was die Stabilität und Ästhetik der textgenerierten Bilder beeinträchtigte.
Janus-Pro führt etwa 72 Millionen synthetische ästhetische Daten ein, wodurch das Verhältnis von realen zu synthetischen Daten 1:1 beträgt. Experimente haben gezeigt, dass synthetische Daten die Modellkonvergenz beschleunigen und die Stabilität und ästhetische Qualität der erzeugten Bilder erheblich verbessern.
Skalierung der Modelle
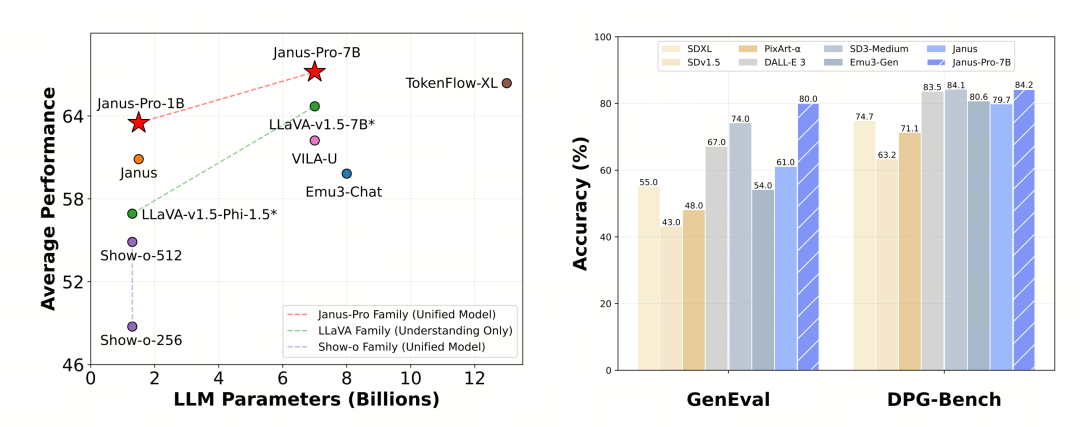
Janus Pro erweitert die Modellgröße auf 7B, während die vorherige Version von Janus 1,5B DeepSeek-LLM verwendete, um die Wirksamkeit der Entkopplung der visuellen Kodierung zu überprüfen. Experimente zeigen, dass eine größere LLM die Konvergenz von multimodalem Verstehen und visueller Generierung signifikant beschleunigt, was die starke Skalierbarkeit der Methode weiter verifiziert.

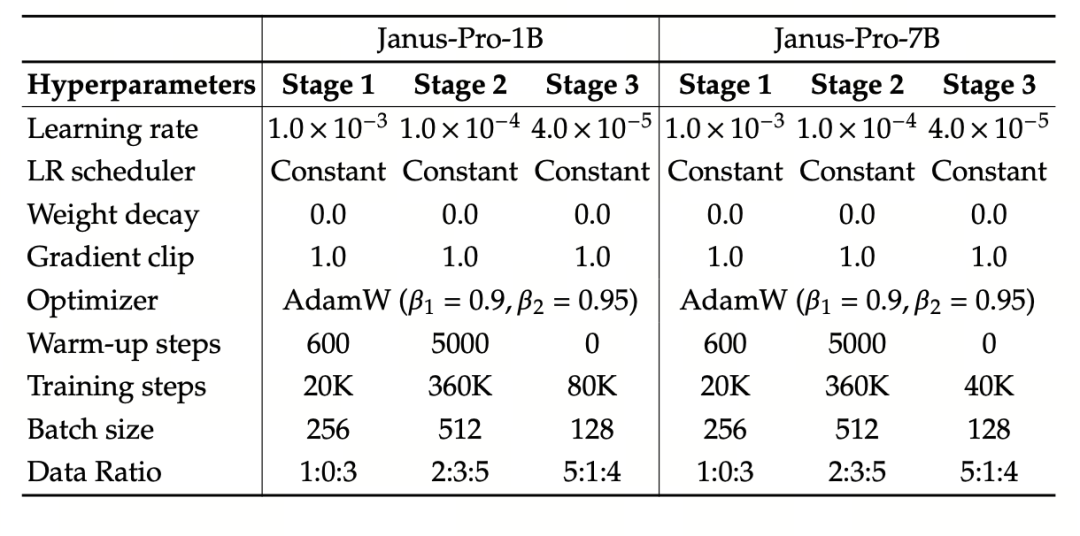
Das Experiment verwendet DeepSeek-LLM (1.5B und 7B, unterstützt eine maximale Sequenz von 4096) als grundlegendes Sprachmodell. Für die multimodale Verstehensaufgabe wird SigLIP-Large-Patch16-384 als visueller Kodierer verwendet, die Wörterbuchgröße des Kodierers beträgt 16384, das Bild-Downsampling-Multiple ist 16, und sowohl der Verstehens- als auch der Generierungsadapter sind zweischichtige MLPs.
Beim Training der Stufe II wird eine 270K-Frühstoppstrategie verwendet, alle Bilder werden einheitlich auf eine Auflösung von 384×384 eingestellt, und die Sequenzpackung wird zur Verbesserung der Trainingseffizienz verwendet. Janus-Pro wird mit HAI-LLM trainiert und bewertet. Die Versionen 1.5B/7B wurden auf 16/32 Knoten (8×Nvidia A100 40GB pro Knoten) jeweils 9/14 Tage lang trainiert.
Bewertung des Modells
Janus-Pro wurde separat für das multimodale Verstehen und die Generierung bewertet. Insgesamt mag das Verstehen etwas schwach sein, aber es wird unter den Open-Source-Modellen derselben Größe als ausgezeichnet angesehen (vermutlich ist es weitgehend durch die feste Eingabeauflösung und die OCR-Fähigkeiten begrenzt).
Im MMBench-Benchmark-Test erzielte der Janus-Pro-7B 79,2 Punkte, was in etwa dem Niveau von Open-Source-Modellen der ersten Reihe entspricht (die gleiche Größe von InternVL2.5 und Qwen2-VL liegt bei 82 Punkten). Dennoch ist dies eine gute Verbesserung gegenüber der vorherigen Generation von Janus.
Bei der Bilderzeugung ist die Verbesserung gegenüber der Vorgängergeneration sogar noch deutlicher und gilt als ausgezeichnetes Niveau unter den Open-Source-Modellen. Die Punktzahl von Janus-Pro im GenEval-Benchmark-Test (0,80) übertrifft auch Modelle wie DALL-E 3 (0,67) und Stable Diffusion 3 Medium (0,74).