
Ⅰ. Qu'est-ce que la distillation des connaissances ?
La distillation des connaissances est une technique de compression de modèles utilisée pour transférer les connaissances d'un grand modèle complexe (le modèle de l'enseignant) à un petit modèle (le modèle de l'étudiant).
Le principe de base est que le modèle de l'enseignant enseigne au modèle de l'étudiant en prédisant des résultats (tels que des distributions de probabilités ou des processus d'inférence), et que le modèle de l'étudiant améliore ses performances en apprenant à partir de ces prédictions.
Cette méthode est particulièrement adaptée aux appareils dont les ressources sont limitées, tels que les téléphones mobiles ou les appareils intégrés.
II. Concepts fondamentaux
2.1 Conception du modèle
- Modèle : Format structuré utilisé pour normaliser les résultats d'un modèle. Par exemple
- : Marque le début du processus de raisonnement.
- : Marque la fin du processus de raisonnement.
- : Marque le début de la réponse finale.
- : Marque la fin de la réponse finale.
- Fonction :
- Clarté : Comme les "mots d'incitation" dans une question à compléter, il indique au modèle "le processus de réflexion se déroule ici, et la réponse se déroule là".
- Cohérence : garantit que tous les résultats suivent la même structure, ce qui facilite le traitement et l'analyse ultérieurs.
- Lisibilité : les êtres humains peuvent facilement faire la distinction entre le processus de raisonnement et la réponse, ce qui améliore l'expérience de l'utilisateur.
2.2 Trajectoire de raisonnement : La "chaîne de pensée" de la solution du modèle
- Trajectoire de raisonnement : Les étapes détaillées générées par le modèle lors de la résolution d'un problème montrent la chaîne logique du modèle.
- Exemple :
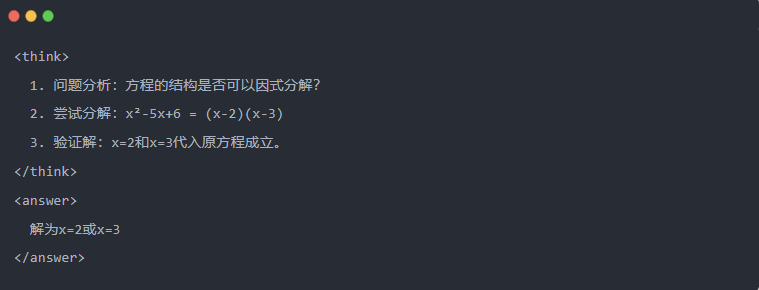
2.3 Échantillonnage par rejet : Filtrer les bonnes données à partir des "essais et erreurs
- Échantillonnage de rejet : Générer plusieurs réponses de candidats et retenir les bonnes, comme lorsqu'on rédige un brouillon et qu'on recopie ensuite la bonne réponse dans un examen.
Ⅲ.Génération de données distillées
La première étape de la distillation des connaissances consiste à générer des "données d'apprentissage" de haute qualité à partir desquelles les petits modèles peuvent apprendre.
Sources de données:
- 80% à partir des données de raisonnement générées par Profondeur de l'eau - R1
- 20% à partir des données de la tâche générale DeepSeek-V3.
Processus de génération des données de distillation:
- Filtrage des règlesL'outil d'aide à la décision : vérifie automatiquement l'exactitude de la réponse (par exemple, si la réponse mathématique est conforme à la formule).
- Contrôle de lisibilitéLe système d'information sur les langues : élimine les langues mixtes (par exemple, le chinois et l'anglais mélangés) ou les longs paragraphes.
- Génération guidée par un modèleLe modèle : exige que DeepSeek-R1 produise des trajectoires d'inférence conformément au modèle.
- Filtre d'échantillonnage de rejet:
- Intégration des donnéesAu final, 800 000 échantillons de haute qualité ont été générés, dont environ 600 000 données d'inférence et environ 200 000 données générales.
Ⅳ.processus de distillation
Rôles de l'enseignant et de l'élève :
- DeepSeek-R1 comme modèle d'enseignant ;
- Les modèles de la série Qwen servent de modèle à l'étudiant.
Les étapes de la formation :
Tout d'abord, la saisie des données : vous devez saisir la partie "question" des 800 000 échantillons dans le modèle Qwen et lui demander de générer une trajectoire d'inférence complète (processus de réflexion + réponse) conformément au modèle. Il s'agit d'une étape très importante
Ensuite, le calcul des pertes : comparer la sortie générée par le modèle de l'étudiant avec la trajectoire d'inférence du modèle de l'enseignant, et aligner la séquence de texte par le biais d'un réglage fin supervisé (SFT). Si vous n'êtes pas sûr de ce qu'est le SFT, j'espère que vous ferez une recherche sur ce mot-clé pour en savoir plus.
Compléter les mises à jour des paramètres pour le plus grand modèle de l'étudiant : Optimiser les paramètres du modèle Qwen par rétropropagation afin d'obtenir une approximation de la sortie du modèle de l'enseignant.
En répétant plusieurs fois ce processus de formation, on s'assure que les connaissances sont suffisamment transférées. L'objectif initial de la formation est ainsi atteint. Nous allons vous donner un exemple pour le démontrer, et nous espérons que vous comprendrez
Ⅴ. Exemple de démonstration
L'article démontre l'effet de distillation à travers une tâche spécifique de résolution d'équation (résoudre l'équation) :
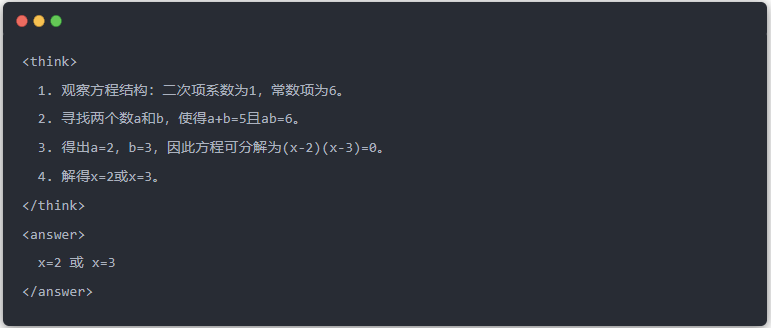
- Sortie standard du modèle de l'enseignant :
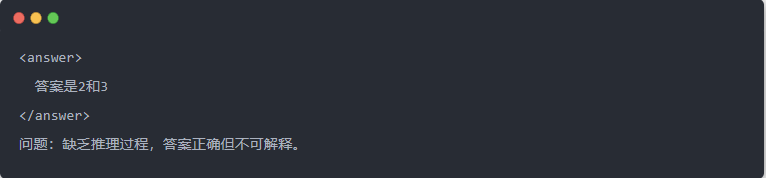
- Sortie du Qwen-7B avant distillation :
- Sortie du Qwen-7B après distillation :
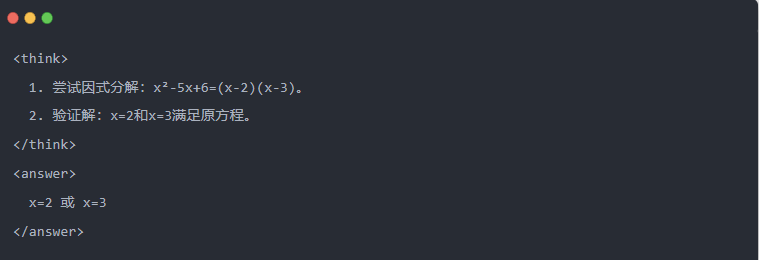
- Solution optimisée : Un processus d'inférence structuré est généré et la réponse est identique au modèle de l'enseignant.
Ⅵ. Résumé
Grâce à la distillation des connaissances, la capacité d'inférence de DeepSeek-R1 est efficacement transférée vers la série de petits modèles Qwen. Ce processus se concentre sur les sorties modélisées et l'échantillonnage de rejet. Grâce à la génération de données structurées et à une formation affinée, les petits modèles peuvent également effectuer des tâches d'inférence complexes dans des scénarios où les ressources sont limitées. Cette technologie constitue une référence importante pour le déploiement léger de modèles d'intelligence artificielle.


