DeepSeek a mis à jour son site web.
Dans les premières heures de la nuit de la Saint-Sylvestre, DeepSeek a soudainement annoncé sur GitHub que l'espace du projet Janus avait ouvert la source du modèle Janus-Pro et du rapport technique.
Tout d'abord, soulignons quelques points essentiels :
- Le Modèle Janus-Pro Cette fois-ci, le modèle publié est un modèle multimodal qui peut effectuer simultanément des tâches de compréhension multimodale et de génération d'images. Il existe au total deux versions de paramètres, Janus-Pro-1B et Janus-Pro-7B.
- L'innovation principale de Janus-Pro est de découpler la compréhension et la génération multimodales, deux tâches différentes. Cela permet d'accomplir efficacement ces deux tâches dans le même modèle.
- Janus-Pro est conforme à l'architecture du modèle Janus publié par DeepSeek en octobre dernier, mais à l'époque, Janus n'avait pas beaucoup de volume. Charles, un expert en algorithmes dans le domaine de la vision, nous a dit que le Janus précédent était "moyen" et "pas aussi bon que le modèle de langage de DeepSeek".

Il est destiné à résoudre le problème difficile de l'industrie : l'équilibre entre la compréhension multimodale et la génération d'images.
Selon la présentation officielle de DeepSeek, Janus-Pro peut non seulement comprendre les images, extraire et comprendre le texte dans les images, mais aussi générer des images en même temps.
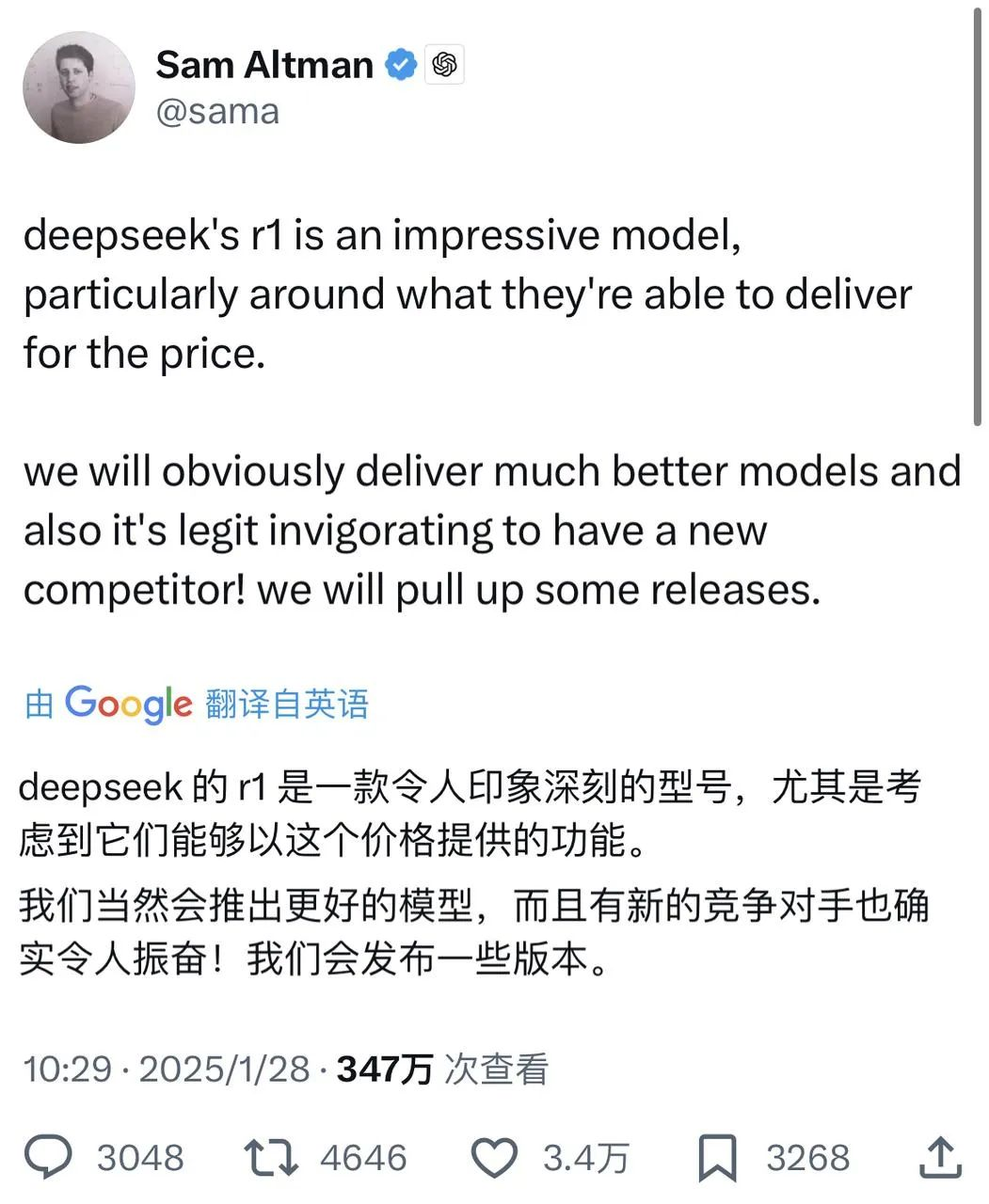
Le rapport technique mentionne que, par rapport à d'autres modèles du même type et du même ordre de grandeur, les résultats obtenus par le Janus-Pro-7B sur les jeux de tests GenEval et DPG-Bench dépassent celles d'autres modèles tels que SD3-Medium et DALL-E 3.
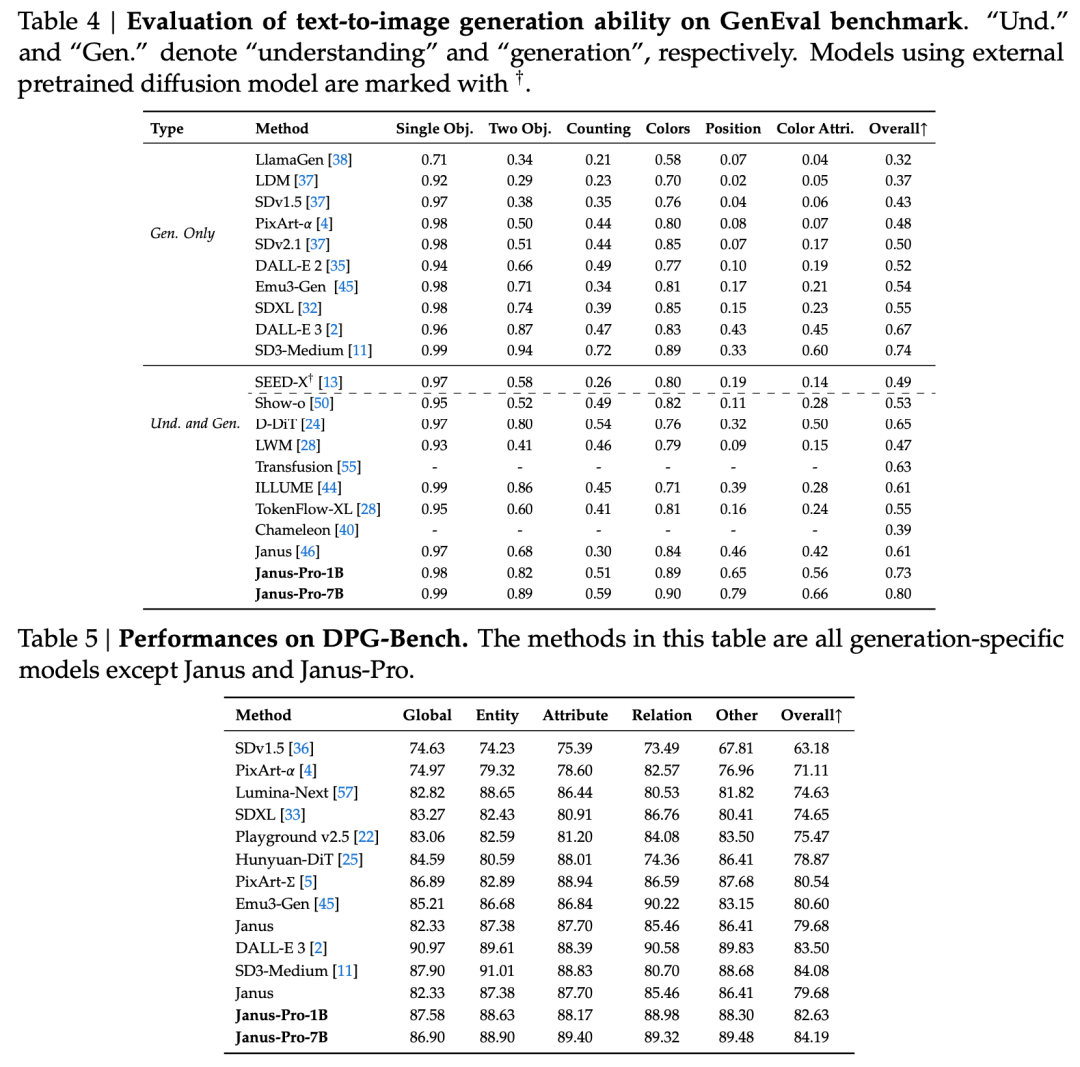
Le fonctionnaire donne également des exemples 👇 :
De nombreux net-citoyens sur X testent également les nouvelles fonctionnalités.

Mais il y a aussi des plantages occasionnels.
En consultant les documents techniques sur DeepSeekNous avons constaté que Janus Pro est une optimisation basée sur Janus, qui a été publié il y a trois mois.
L'innovation principale de cette série de modèles consiste à dissocier les tâches de compréhension visuelle des tâches de génération visuelle, afin d'équilibrer les effets des deux tâches.
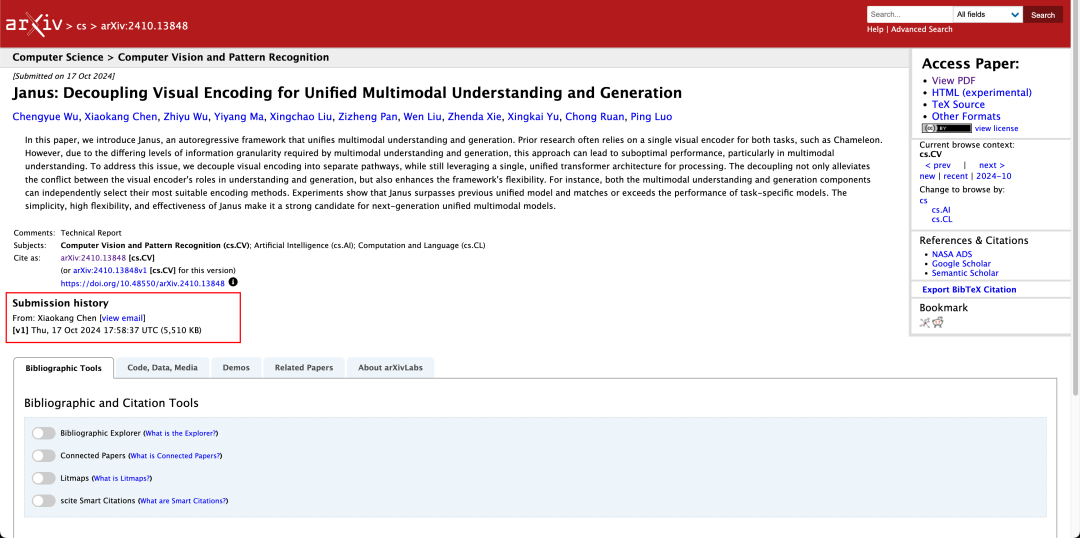
Il n'est pas rare qu'un modèle soit capable de comprendre et de générer des données multimodales en même temps. D-DiT et TokenFlow-XL dans cet ensemble de tests ont tous deux cette capacité.
Cependant, ce qui caractérise Janus, c'est que en découplant le traitement, un modèle capable d'effectuer une compréhension et une génération multimodales équilibre l'efficacité des deux tâches.
L'équilibre entre l'efficacité de ces deux tâches est un problème difficile à résoudre dans l'industrie. Auparavant, l'idée était d'utiliser le même encodeur pour mettre en œuvre une compréhension et une génération multimodales autant que possible.
Les avantages de cette approche sont une architecture simple, l'absence de déploiement redondant et un alignement sur les modèles de texte (qui utilisent également les mêmes méthodes pour générer et comprendre du texte). Un autre argument est que cette fusion de capacités multiples peut conduire à un certain degré d'émergence.
En effet, la compréhension d'une image exige que le modèle fasse abstraction des dimensions élevées et extraie la sémantique centrale de l'image, ce qui est biaisé en faveur du macroscopique. La génération d'images, quant à elle, se concentre sur l'expression et la génération de détails locaux au niveau du pixel.
La pratique habituelle de l'industrie est de donner la priorité aux capacités de génération d'images. Il en résulte des modèles multimodaux qui peuvent générer des images de meilleure qualité, mais les résultats de la compréhension des images sont souvent médiocres.
L'architecture découplée de Janus et la stratégie de formation optimisée de Janus-Pro
L'architecture découplée de Janus permet au modèle d'équilibrer les tâches de compréhension et de génération de manière autonome.
D'après les résultats du rapport technique officiel, qu'il s'agisse de compréhension multimodale ou de génération d'images, le Janus-Pro-7B obtient de bons résultats sur de nombreux ensembles de tests.

Pour une compréhension multimodale, Janus-Pro-7B a obtenu la première place dans quatre des sept ensembles de données d'évaluation, et la deuxième place dans les trois autres, légèrement derrière le modèle le mieux classé.
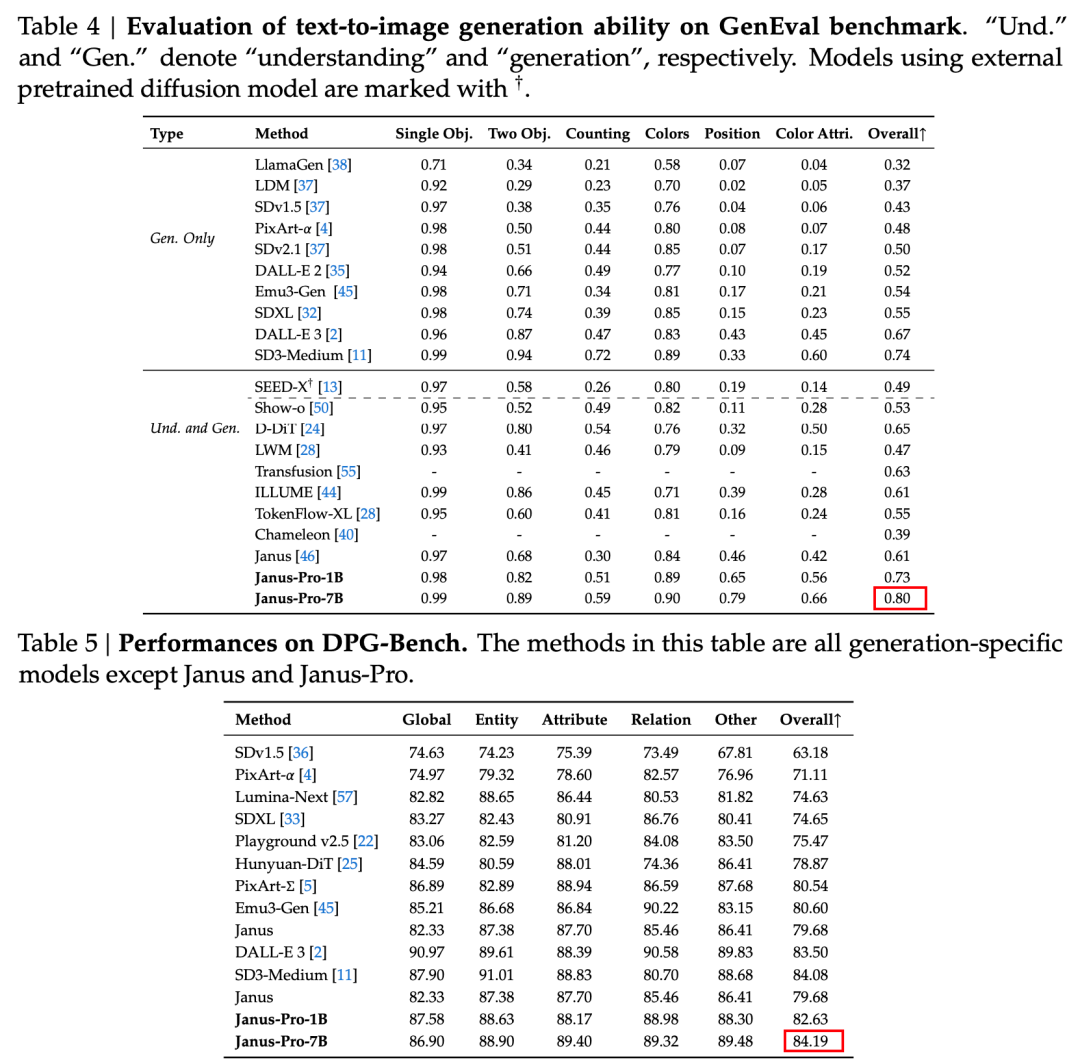
Pour la génération d'images, Janus-Pro-7B a obtenu la première place pour le score global sur les ensembles de données d'évaluation GenEval et DPG-Bench.
Cet effet multitâche est principalement dû à l'utilisation, dans la série Janus, de deux encodeurs visuels pour des tâches différentes :
- Comprendre le codeur : utilisé pour extraire des caractéristiques sémantiques dans les images pour des tâches de compréhension d'images (telles que les questions et réponses sur les images, la classification visuelle, etc.)
- Encodeur génératif : convertit les images en une représentation discrète (par exemple, à l'aide d'un encodeur VQ) pour les tâches de génération de texte à partir d'images.
Avec cette architecture, le modèle peut optimiser de manière indépendante les performances de chaque encodeur, de sorte que les tâches de compréhension et de génération multimodales puissent chacune atteindre leur meilleure performance.
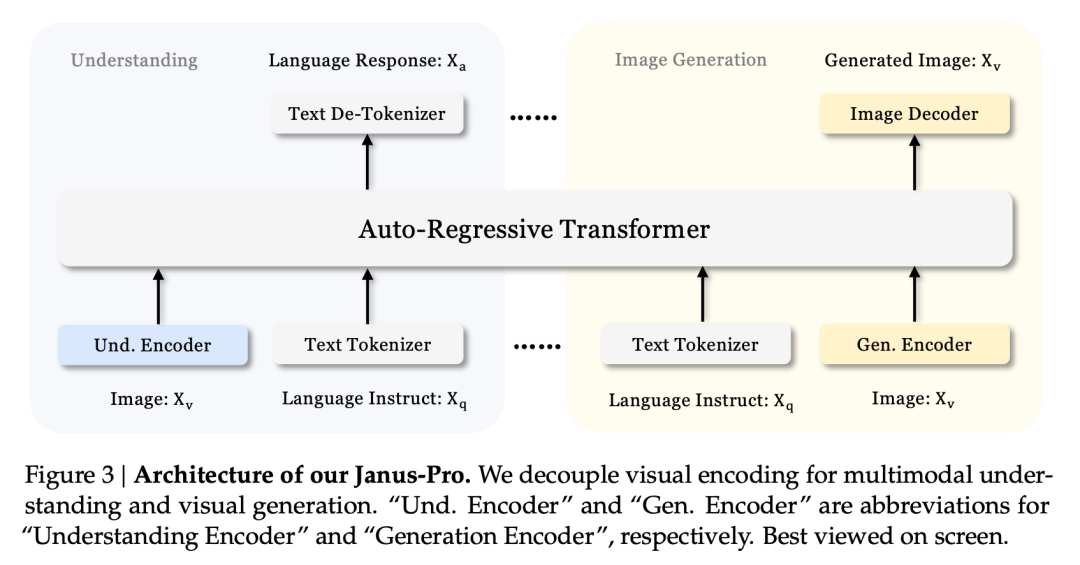
Cette architecture découplée est commune à Janus-Pro et Janus. Quelles ont été les itérations de Janus-Pro au cours des derniers mois ?
Comme le montrent les résultats de l'ensemble d'évaluation, la version actuelle de Janus-Pro-1B présente une amélioration d'environ 10% à 20% dans les résultats des différents ensembles d'évaluation par rapport à l'ancienne version de Janus. La version Janus-Pro-7B présente l'amélioration la plus importante, d'environ 45%, par rapport à Janus, après avoir élargi le nombre de paramètres.

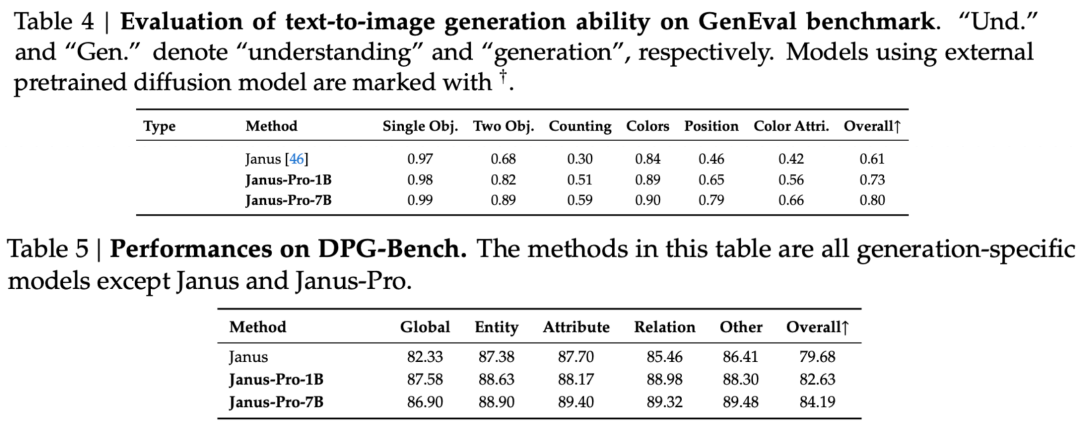
En ce qui concerne les détails de la formation, le rapport technique indique que la version actuelle de Janus-Pro, comparée au modèle Janus précédent, conserve la conception de l'architecture découplée de base et itère en outre sur les éléments suivants la taille des paramètres, la stratégie d'apprentissage et les données d'apprentissage.
Tout d'abord, examinons les paramètres.
La première version de Janus n'avait que 1,3 milliard de paramètres, et la version actuelle de Pro comprend des modèles avec 1 milliard et 7 milliards de paramètres.
Ces deux tailles reflètent l'évolutivité de l'architecture Janus. Le modèle 1B, qui est le plus léger, a déjà été utilisé par des utilisateurs externes pour fonctionner dans le navigateur à l'aide de WebGPU.
Il y a aussi les stratégie de formation.
Conformément à la division des phases de formation de Janus, le Janus Pro comporte un total de trois phases de formation, et le document les divise directement en phase I, phase II et phase III.
Tout en conservant les idées et les objectifs de formation de base de chaque phase, Janus-Pro a apporté des améliorations à la durée et aux données de la formation dans les trois phases. Voici les améliorations spécifiques apportées aux trois phases :
Phase I - Temps de formation plus long
Par rapport à Janus, Janus-Pro a allongé le temps de formation dans la phase I, en particulier pour la formation des adaptateurs et des têtes d'image dans la partie visuelle. Cela signifie que l'apprentissage des caractéristiques visuelles a bénéficié d'un temps de formation plus long, et l'on espère que le modèle pourra comprendre pleinement les caractéristiques détaillées des images (telles que la correspondance pixel-sémantique).
Cette formation élargie permet de s'assurer que la formation de la partie visuelle n'est pas perturbée par d'autres modules.
Étape II - Suppression des données ImageNet et ajout de données multimodales
À l'étape II, Janus a référencé PixArt au préalable et s'est entraîné en deux parties. La première partie a été entraînée en utilisant l'ensemble de données ImageNet pour la tâche de classification d'images, et la seconde partie a été entraînée en utilisant des données texte-image normales. Environ deux tiers du temps de la phase II ont été consacrés à l'apprentissage de la première partie.
Janus-Pro supprime la formation ImageNet dans la phase II. Cette conception permet au modèle de se concentrer sur les données texte-image pendant la formation de la phase II. D'après les résultats expérimentaux, cela permet d'améliorer considérablement l'utilisation des données texte-image.
Outre l'ajustement de la conception de la méthode de formation, l'ensemble de données de formation utilisé dans la phase II n'est plus limité à une seule tâche de classification d'images, mais inclut également d'autres types de données multimodales, telles que la description d'images et le dialogue, pour une formation conjointe.
Étape III - Optimisation du rapport de données
Au cours de la phase III de la formation, Janus-Pro ajuste le rapport entre les différents types de données de formation.
Auparavant, le rapport entre les données de compréhension multimodale, les données de texte simple et les données texte-image dans les données de formation utilisées par Janus à l'étape III était de 7:3:10. Janus-Pro réduit le ratio des deux derniers types de données et ajuste le ratio des trois types de données à 5:1:4, c'est-à-dire qu'il accorde plus d'attention à la tâche de compréhension multimodale.
Examinons les données d'apprentissage.
Par rapport à Janus, Janus-Pro augmente cette fois-ci de manière significative la quantité de produits de haute qualité. des données synthétiques.
Il augmente la quantité et la variété des données de formation pour la compréhension multimodale et la génération d'images.
Expansion des données de compréhension multimodale :
Janus-Pro se réfère à l'ensemble de données DeepSeek-VL2 pendant l'entraînement et ajoute environ 90 millions de points de données supplémentaires, y compris non seulement des ensembles de données de description d'images, mais aussi des ensembles de données de scènes complexes telles que des tableaux, des graphiques et des documents.
Au cours de la phase d'affinage supervisé (phase III), il continue d'ajouter des ensembles de données liés à la compréhension de MEME et à l'amélioration de l'expérience en matière de dialogue (y compris le dialogue chinois).
Expansion des données de génération visuelle :
Les données réelles d'origine étaient de mauvaise qualité et comportaient des niveaux de bruit élevés, ce qui a conduit le modèle à produire des résultats instables et des images d'une qualité esthétique insuffisante dans les tâches de conversion de texte en image.
Janus-Pro a ajouté environ 72 millions de nouvelles données synthétiques très esthétiques à la phase d'entraînement, ce qui a porté le rapport entre les données réelles et les données synthétiques dans la phase de pré-entraînement à 1:1.
Les invites pour les données synthétiques ont toutes été tirées de ressources publiques. Les expériences ont montré que l'ajout de ces données permet au modèle de converger plus rapidement, et que les images générées présentent des améliorations évidentes en termes de stabilité et de beauté visuelle.
La poursuite d'une révolution de l'efficacité ?
Dans l'ensemble, avec cette version, DeepSeek a apporté la révolution de l'efficacité aux modèles visuels.
Contrairement aux modèles visuels qui se concentrent sur une seule fonction ou aux modèles multimodaux qui favorisent une tâche spécifique, Janus-Pro équilibre les effets des deux principales tâches de génération d'images et de compréhension multimodale dans le même modèle.
En outre, malgré ses paramètres réduits, il a battu OpenAI DALL-E 3 et SD3-Medium dans l'évaluation.
Étendue au sol, l'entreprise n'a plus qu'à déployer un modèle pour mettre en œuvre directement les deux fonctions de génération et de compréhension d'images. Avec une taille de seulement 7B, la difficulté et le coût du déploiement sont bien moindres.
En relation avec les versions précédentes de R1 et V3, DeepSeek remet en question les règles du jeu existantes avec "innovation architecturale compacte, modèles légers, modèles open source et coûts de formation très faibles".. C'est la raison pour laquelle les géants occidentaux de la technologie et même Wall Street ont paniqué.
A l'instant, Sam Altman, emporté par l'opinion publique depuis plusieurs jours, a finalement répondu positivement aux informations sur DeepSeek on X. Tout en faisant l'éloge de R1, il a déclaré que l'OpenAI allait faire des annonces.