
et l'ère de l'IA est tranquillement arrivée.
Personne ne s'attendait probablement à ce que, pour le Nouvel An chinois, le sujet le plus brûlant ne soit plus la traditionnelle bataille de l'enveloppe rouge de l'internet, qui s'est associée au gala de la fête du printemps, mais les entreprises d'intelligence artificielle.
À l'approche de la fête du printemps, les grandes entreprises de modélisme n'ont pas relâché leurs efforts, mettant à jour une vague de modèles et de produits. Toutefois, c'est DeepSeek, une "grande entreprise de modélisme" apparue l'année dernière, qui a fait couler le plus d'encre.
Dans la soirée du 20 janvier, ProfondeurSeek a publié la version officielle de son modèle de raisonnement DeepSeek-R1. En utilisant un faible coût de formation, il a directement formé une performance qui n'est pas inférieure au modèle de raisonnement OpenAI o1. De plus, ce modèle est entièrement gratuit et open source, ce qui a directement déclenché un tremblement de terre dans l'industrie.
C'est la première fois qu'une IA nationale provoque des remous dans le monde de la technologie à grande échelle, en particulier aux États-Unis. Des développeurs ont exprimé qu'ils envisageaient d'utiliser DeepSeek pour "tout reconstruire". Dans le sillage de cette vague, après une semaine de fermentation, et même à peine sortie en janvier, l'application mobile DeepSeek a rapidement atteint le sommet du classement des applications gratuites sur l'App Store d'Apple aux États-Unis, dépassant non seulement ChatGPT, mais aussi d'autres applications populaires aux États-Unis.
Le succès de DeepSeek a même eu un impact direct sur le marché boursier américain. Un modèle formé sans utiliser un grand nombre de GPU coûteux a incité les gens à repenser le processus de formation de l'IA, provoquant directement la plus forte chute de 17% dans la première action de l'IA, NVIDIA.
Et ce n'est pas tout.
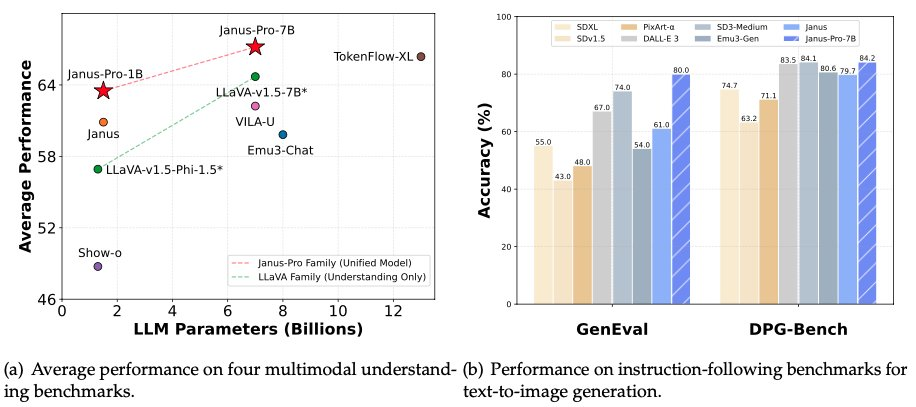
Au petit matin du 28 janvier, la veille de la Saint-Sylvestre, DeepSeek a de nouveau ouvert la source de son modèle multimodal Janus-Pro-7B, annonçant qu'il avait battu DALL-E 3 (d'OpenAI) et Stable Diffusion dans les tests de référence GenEval et DPG-Bench.
DeepSeek va-t-il vraiment balayer la communauté de l'IA ? Des modèles d'inférence aux modèles multimodaux, DeepSeek est-il en train de restructurer tout le premier sujet de l'année du serpent ?
Janus ProLa validation d'un modèle innovant d'architecture multimodale
DeepSeek a publié un total de deux modèles tard dans la nuit cette fois-ci : Janus-Pro-7B et Janus-Pro-1B (paramètres de 1,5B).
Comme son nom l'indique, le modèle lui-même est une amélioration par rapport au modèle Janus précédent.
DeepSeek n'a publié le modèle Janus pour la première fois qu'en octobre 2024. Comme d'habitude avec DeepSeek, le modèle adopte une architecture innovante. Dans de nombreux modèles de génération de vision, le modèle adopte une architecture de transformateur unifiée qui peut traiter simultanément les tâches texte-image et image-texte.
DeepSeek propose une nouvelle idée, découplant l'encodage visuel des tâches de compréhension (graphique vers texte) et de génération (texte vers graphique), qui améliore la flexibilité de l'apprentissage du modèle et atténue efficacement les conflits et les goulots d'étranglement de performance causés par l'utilisation d'un encodage visuel unique.
C'est pourquoi DeepSeek a baptisé le modèle Janus. Janus est l'ancien dieu romain des portes et est représenté avec deux visages orientés dans des directions opposées. DeepSeek a expliqué que le modèle s'appelle Janus parce qu'il peut regarder des données visuelles avec des yeux différents, coder les caractéristiques séparément, puis utiliser le même corps (Transformer) pour traiter ces signaux d'entrée.
Cette nouvelle idée a donné de bons résultats avec la série de modèles Janus. L'équipe indique que le modèle Janus possède de solides capacités de suivi des commandes, des capacités multilingues, et qu'il est plus intelligent, capable de lire les images de mèmes. Il peut également prendre en charge des tâches telles que la conversion de formules Latex et la conversion de graphiques en code.
Dans la série de modèles Janus Pro, l'équipe a partiellement modifié le processus d'entraînement du modèle, ce qui a permis d'obtenir directement des résultats supérieurs à ceux de DALL-E 3 et de Stable Diffusion dans les tests de référence GenEval et DPG-Bench.
Outre le modèle lui-même, DeepSeek a également publié le nouveau cadre d'IA multimodale Janus Flow, qui vise à unifier les tâches de compréhension et de génération d'images.
Le modèle Janus Pro peut fournir des résultats plus stables à l'aide d'invites courtes, avec une meilleure qualité visuelle, des détails plus riches et la capacité de générer un texte simple.
Le modèle peut générer des images et décrire des images, identifier des attractions touristiques (comme le lac de l'Ouest à Hangzhou), reconnaître du texte dans des images et décrire des connaissances dans des images (comme les gâteaux "Tom et Jerry").
One x.com, De nombreuses personnes ont déjà commencé à expérimenter le nouveau modèle.

Le test de reconnaissance d'images est représenté à gauche dans la figure ci-dessus, tandis que le test de génération d'images est représenté à droite.

Comme on peut le constater, le Janus Pro est également capable de lire des images avec une grande précision. Il peut reconnaître une composition mixte d'expressions mathématiques et de texte. À l'avenir, il pourrait être plus important de l'utiliser avec un modèle de raisonnement.
Les paramètres de 1B et 7B peuvent débloquer de nouveaux scénarios d'application
Dans les tâches de compréhension multimodale, le nouveau modèle Janus-Pro utilise SigLIP-L comme codeur visuel et prend en charge des entrées d'images de 384 x 384 pixels. Dans les tâches de génération d'images, Janus-Pro utilise un tokenizer provenant d'une source spécifique avec un taux de sous-échantillonnage de 16.
La taille de l'image reste relativement petite. X Selon l'analyse de l'utilisateur, le modèle Janus Pro est plutôt une vérification directionnelle. Si la vérification est fiable, un modèle pouvant être mis en production sera publié.
Toutefois, il convient de noter que le nouveau modèle publié par Janus cette fois-ci n'est pas seulement innovant sur le plan architectural pour les modèles multimodaux, mais qu'il constitue également une nouvelle exploration en termes de nombre de paramètres.
Le modèle comparé par DeepSeek Janus Pro cette fois-ci, DALL-E 3, a annoncé précédemment qu'il avait 12 milliards de paramètres, alors que le modèle de grande taille de Janus Pro n'en a que 7 milliards. Avec une taille aussi compacte, il est déjà très bon que Janus Pro puisse atteindre de tels résultats.
En particulier, le modèle 1B de Janus Pro n'utilise que 1,5 milliard de paramètres. Des utilisateurs ont déjà ajouté la prise en charge du modèle à transformers.js sur le réseau externe. Cela signifie que le modèle peut maintenant exécuter 100% dans les navigateurs sur WebGPU !
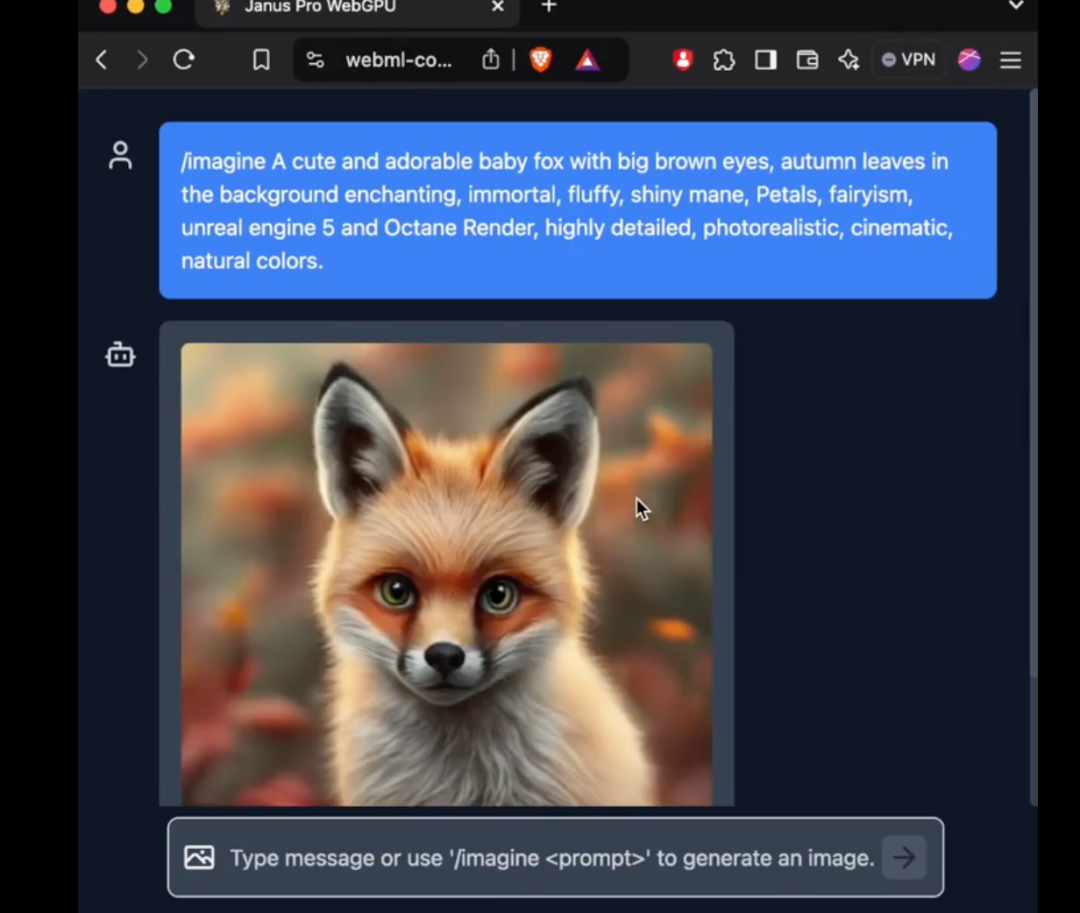
Bien qu'à l'heure où nous mettons sous presse, l'auteur n'ait pas encore été en mesure d'utiliser avec succès le nouveau modèle de Janus Pro sur la version web, le fait que le nombre de paramètres soit suffisamment réduit pour être exécuté directement sur le côté web constitue toujours une amélioration étonnante.
Cela signifie que le coût de la génération et de la compréhension d'images continue de baisser. Nous avons la possibilité d'utiliser l'IA dans un plus grand nombre d'endroits où les images brutes et la compréhension d'images ne pouvaient pas être utilisées auparavant, ce qui changera nos vies.
En 2024, la façon dont le matériel d'IA doté d'une compréhension multimodale accrue peut intervenir dans nos vies constitue un point d'intérêt majeur. Les modèles de compréhension multimodale avec des paramètres de plus en plus bas, ou les modèles qui peuvent fonctionner à la limite, peuvent permettre au matériel d'IA de continuer à exploser.
DeepSeek a mis le feu aux poudres en ce début d'année. Peut-on tout refaire avec l'IA chinoise ?
Le monde de l'IA évolue de jour en jour.
L'année dernière, à l'occasion de la fête du printemps, le modèle Sora d'OpenAI a fait sensation dans le monde entier. Cependant, au cours de l'année, les entreprises chinoises ont complètement rattrapé leur retard en termes de production de vidéos, ce qui rend la sortie de Sora à la fin de l'année un peu sombre.
Cette année, c'est le DeepSeek chinois qui a mis le monde en émoi.
DeepSeek n'est pas une entreprise technologique traditionnelle, mais elle a réalisé des modèles extrêmement innovants à un coût bien inférieur à celui des cartes GPU des grandes entreprises américaines, ce qui a directement choqué ses homologues américains. Les Américains se sont exclamés : "La formation du modèle R1 n'a coûté que 5,6 millions de dollars américains, ce qui équivaut même au salaire de n'importe quel cadre de l'équipe de Meta GenAI. Quelle est cette mystérieuse puissance orientale ?"
Un compte parodique imitant le fondateur de DeepSeek, Liang Wenfeng, a posté une image intéressante directement sur X :

L'image reprenait le mème à la mode du tireur turc mondialement connu en 2024.
Lors de la finale du pistolet à air comprimé de 10 mètres des épreuves de tir des Jeux olympiques de Paris, le tireur turc Mithat Dikec, 51 ans, qui ne portait qu'une paire de lunettes de myope ordinaire et une paire de bouchons d'oreille pour dormir, a calmement empoché la médaille d'argent, une seule main dans la poche. Tous les autres tireurs présents avaient besoin de deux lentilles professionnelles pour la mise au point et le blocage de la lumière, ainsi que d'une paire de bouchons d'oreille anti-bruit pour commencer la compétition.
Depuis que DeepSeek a "craqué" Le modèle de raisonnement de l'OpenAILes grandes entreprises technologiques américaines ont fait l'objet de pressions intenses. Aujourd'hui, Sam Altman a finalement répondu par une déclaration officielle.

L'année 2025 sera-t-elle l'année où l'IA chinoise aura un impact sur les perceptions américaines ?
DeepSeek a encore quelques secrets dans sa manche - ce sera un festival de printemps extraordinaire.




