

ShareGPT-4o-Image は、すべての画像が GPT-4o の画像生成機能を使用して生成される大規模で高品質の画像生成データセットです。
このデータセットは、オープンソースのマルチモーダル モデルの利点と、視覚コンテンツ作成における GPT-4o の強みを組み合わせることを目的としています。
これには、テキストから画像へのサンプルが 45,000 件、画像からテキストへのサンプルが 46,000 件含まれており、画像生成および編集タスクにおけるマルチモーダル モデルを強化するための実用的なリソースになります。

Janus-4oは、テキストから画像への変換とテキスト+画像から画像への変換が可能なマルチモーダルLLMです。Janus-Proをベースとし、ShareGPT-4o-Imageデータセットを用いて微調整されています。Janus-Proと比較して、Janus-4oはテキスト+画像から画像への変換機能を導入し、テキストから画像への変換において大幅な改善を実現しています。
データセットの概要
ShareGPT-4o-Image データセットには、次のように分類された 91,000 個の GPT-4o 画像生成サンプルが含まれています。
- テキストから画像へ: 45,717
- テキスト+画像から画像へ: 46,539
関連リンク
コード: githubはこちらをクリック
モデル: ShareGPT-4o-Imageモデルを取得する
紙: ここをクリック
論文紹介
マルチモーダル生成モデルの近年の進歩により、リアルで命令に沿った画像生成が可能になりました。しかし、GPT-4o-Imageのような先進的なシステムは依然として独自仕様であり、アクセスが困難です。
これらの機能を一般に公開するために、論文では ShareGPT-4o-Image を紹介しています。これは、テキストから画像への変換例 45,000 件とテキスト + 画像から画像への変換例 46,000 件を含む最初のデータセットです。これらはすべて GPT-4o の画像生成機能を使用して合成され、高度な画像生成機能を改良しています。このデータセットを使用して、論文ではテキストから画像への変換とテキスト + 画像から画像への変換が可能なマルチモーダル大規模言語モデル Janus-4o を開発しました。
Janus-4o は、前身の Janus-Pro と比べてテキストから画像への生成機能を大幅に向上させただけでなく、テキストと画像から画像への生成機能も導入しています。特に、わずか 91K の合成サンプルを使用し、8×A800 GPU マシンで 6 時間トレーニングしただけで、テキストと画像を最初から生成するという優れたパフォーマンスを実現しています。
ShareGPT-4o-Image と Janus-4o のリリースにより、写真のようにリアルで、命令に沿った画像生成に関するオープン リサーチが促進されることを期待しています。
方法の概要
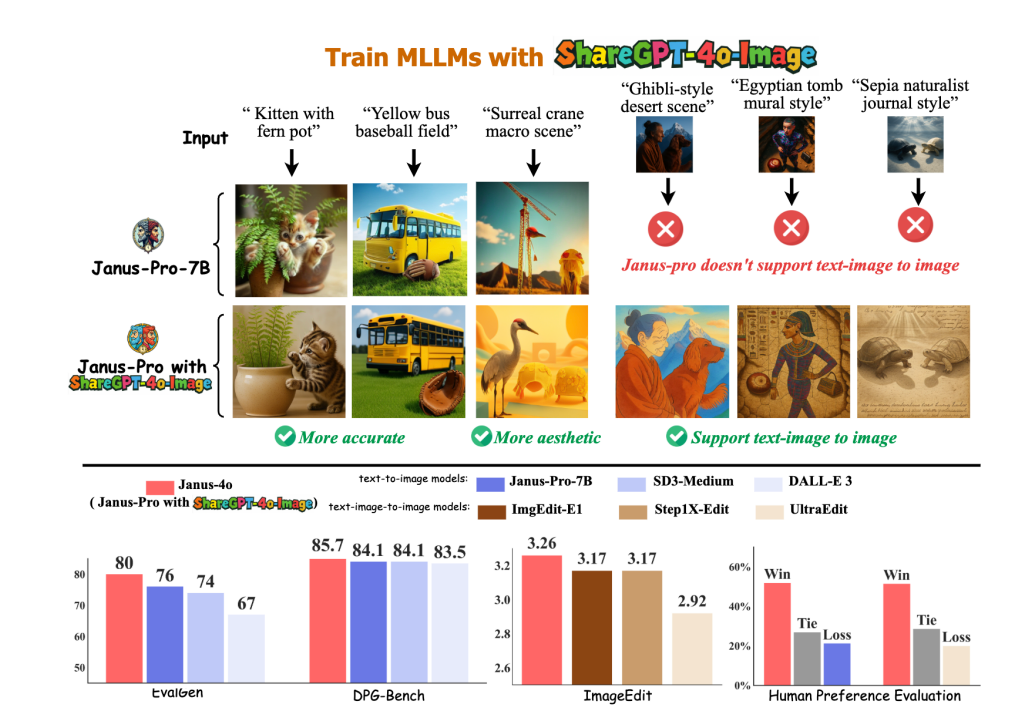
ShareGPT-4o-Image は画像生成のパフォーマンスを向上させます。 ShareGPT-4o-Imageを用いてJanus-Proを微調整することで、画像生成性能が大幅に向上したJanus-4oを生成しました。Janus-4oはテキストから画像への生成と画像から画像への生成もサポートしており、わずか91,000個の学習サンプルで他のベンチマークを上回る性能を発揮しました。
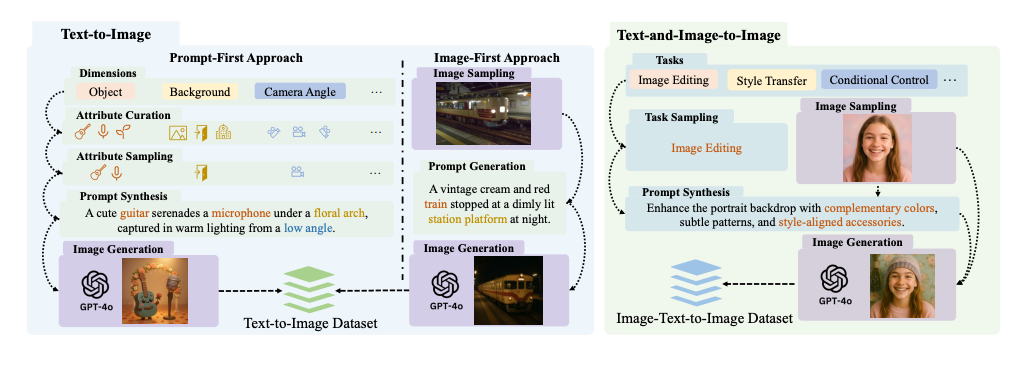
Janus-4o モデルの概要。 このモデルはJanus-Proをベースとし、ShareGPT-4o-Imageで微調整して構築されています。テキストから画像への変換と画像から画像への変換をサポートするための機能強化が組み込まれています。テキストから画像への変換とテキストから画像への変換のタスクは、両方とも共同で学習されます。
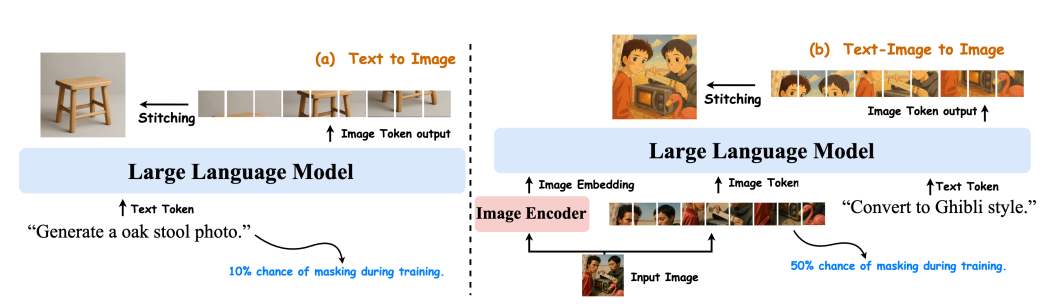
実験結果

結論
ShareGPT-4o-Imageは、テキストから画像への変換とテキストから画像への変換におけるGPT-4oの高度な画像生成機能を捉えることができる初の大規模データセットです。このデータセットに基づいて、本論文では、純粋なテキストまたは画像とテキストの組み合わせから高品質の画像を生成できる機械学習モデル(MLLM)であるJanus-4oを開発しました。
Janus-4o は、テキストから画像への生成において大幅な改善を実現し、テキストから画像へのタスクで非常に競争力のある結果を達成し、ShareGPT-4o-Image の高品質と実用性を実証しています。
MLLM に基づく自己回帰画像生成の効率性により、Janus-4o は 8×A800 GPU マシンでわずか 6 時間でトレーニングでき、非常に低い計算要件で大幅なパフォーマンスの向上を実現します。




