

主なハイライト
🔹 ユニファイド・トランスフォーマー・アーキテクチャ:1つのモデルで両方の画像理解に対応 そして 生成することで、別々のシステムが不要になる。
🔹 スケーラブル&オープンソース:で利用可能 1B そして 7B パラメータバージョン(MITライセンス)、多様なアプリケーションと商用利用に最適化されています。
🔹 最先端のパフォーマンス:GenEvalやDPG-BenchなどのベンチマークでOpenAIのDALL-E 3やStable Diffusionを上回る。
🔹 簡素化された配備:合理化されたアーキテクチャは、柔軟性を維持しながら、トレーニング/干渉コストを削減します。
モデルリンク
- Janus-Pro-7B: ハグ顔
- Janus-Pro-1B: ハグ顔
- ギットハブ: コードとドキュメント
Janus-Proが際立つ理由
1.デュアル・スーパーパワー
- モードを理解する:用途 シグリップL (最大384×384)とテキストを分析するための「スーパーグラス」。
- ジェネレーション・モード:レバレッジ 整流フロー + SDXL-VAE (マジックブラシ)を使って高品質の画像を作成します。
2.脳力とトレーニング
- コアLLM:DeepSeekの強力な言語モデル(1.5B/7Bパラメータ)をベースに構築されており、文脈推論に優れています。
- トレーニング・パイプライン:膨大なデータセットでの事前学習 → 教師ありの微調整 → EMAの最適化で最高のパフォーマンスを実現。
3.なぜトランスの過拡散なのか?
- タスクの多様性:拡散モデルが純粋に画質を重視するのに対し、統一的な理解+生成を優先。
- 効率性:自己回帰生成(シングルステップ)と拡散の反復ノイズ除去(例えば、安定拡散では20ステップ)。
- 費用対効果:単一のTransformerバックボーンにより、トレーニングと配備が簡素化されます。
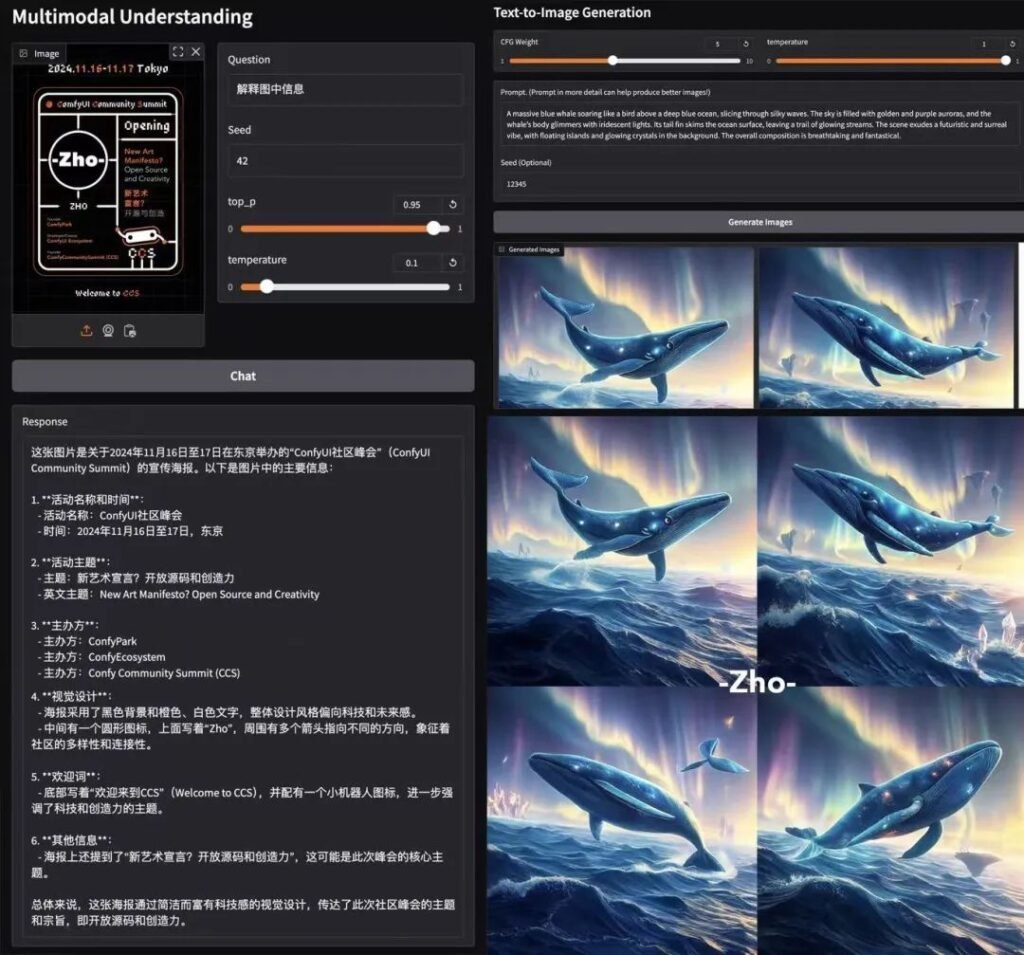
ベンチマークの優位性
📊 マルチモーダル理解
Janus-Pro-7Bは、4つの主要なベンチマークにおいて、特殊なモデル(例えばLLaVA)を凌駕し、パラメータサイズに応じて滑らかにスケーリングする。
テキストから画像へ 🎨 生成
- ジェンエバル:SDXLとDALL-E 3にマッチ。
- DPGベンチ: 84.2%精度 (Janus-Pro-7B)を上回る。
実世界テスト
- スピード:~15秒/イメージ(L4 GPU、22GB VRAM)。
- 品質:細部の改良は必要だが、強力な迅速さ。
- コラボ・デモ: Janus-Pro-7Bを試す (プロ・ティアが必要)。
技術的内訳
建築
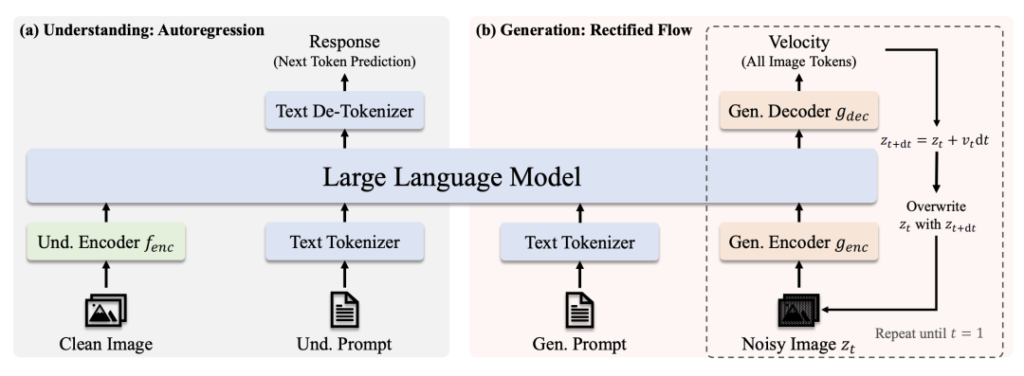
- パスを理解する:きれいな画像→SigLIP-Lエンコーダー→LLM→テキスト応答。
- 世代パス:ノイズ画像 → 整流フローデコーダ+LLM → 反復ノイズ除去。
主なイノベーション
- 非連結ビジュアル・エンコーディング:視覚モジュールにおける「役割の衝突」を防ぐ、理解/生成のための別々の経路。
- 共有トランス・コア:タスク横断的な知識伝達を可能にする(例えば、「猫」の概念を学ぶことは、認識と描画の両方に役立つ)。
コミュニティーの話題
AK(AI研究者): 「Janus-Proのシンプルさと柔軟性は、次世代のマルチモーダルシステムの有力な候補となる。統一されたトランスフォーマーを維持しながら視覚経路を切り離すことで、特殊化と一般化のバランスをとっています。"
MITライセンスが重要な理由
- 自由:最小限の制限で使用、変更、商用配布が可能です。
- 透明性:完全なコードアクセスにより、コミュニティ主導の改良が加速。
ファイナル・テイク
DeepSeekのJanus-Proは単なるAIモデルではなく、パラダイムシフトです。理解と生成をひとつ屋根の下で統合することで、よりスマートな創造的ツール、リアルタイムのアプリケーション、コスト効率の高い展開への扉を開く。オープンソースアクセスとMITライセンスにより、これはマルチモーダルイノベーションの次の波を起こすきっかけになるかもしれない。🚀
開発者のために:をチェックしてください。 ComfyUIノード そして実験の波に加わろう!
この記事のスポンサー


