ディープシークがウェブサイトを更新した。
大晦日の未明、ディープシークは突然GitHubで、JanusプロジェクトスペースがJanus-Proモデルとテクニカルレポートのソースを公開したと発表した。
まず、重要なポイントをいくつか挙げてみよう:
- について Janus-Proモデル 今回発表されたのは、以下のようなマルチモーダルモデルである。 は、マルチモーダル理解と画像生成タスクを同時に実行できる。合計2つのパラメータ・バージョンがある、 Janus-Pro-1BおよびJanus-Pro-7B.
- Janus-Proの革新の核心は、次のような点にある。 マルチモーダル理解と生成という2つの異なるタスク。そのため、この2つのタスクを同じモデルで効率的にこなすことができる。.
- Janus-Proは昨年10月にDeepSeekが発表したJanusモデルのアーキテクチャと一致しているが、当時Janusはあまりボリュームがなかった。視覚分野のアルゴリズム専門家であるチャールズ博士は、以前のJanusは「平均的」で「DeepSeekの言語モデルほどではない」と語っている。

マルチモーダル理解と画像生成の両立という業界の難題を解決することを目的としている
ディープシークの公式紹介によると Janus-Pro は絵を理解し、絵の中のテキストを抽出して理解するだけでなく、同時に絵を生成することもできる。
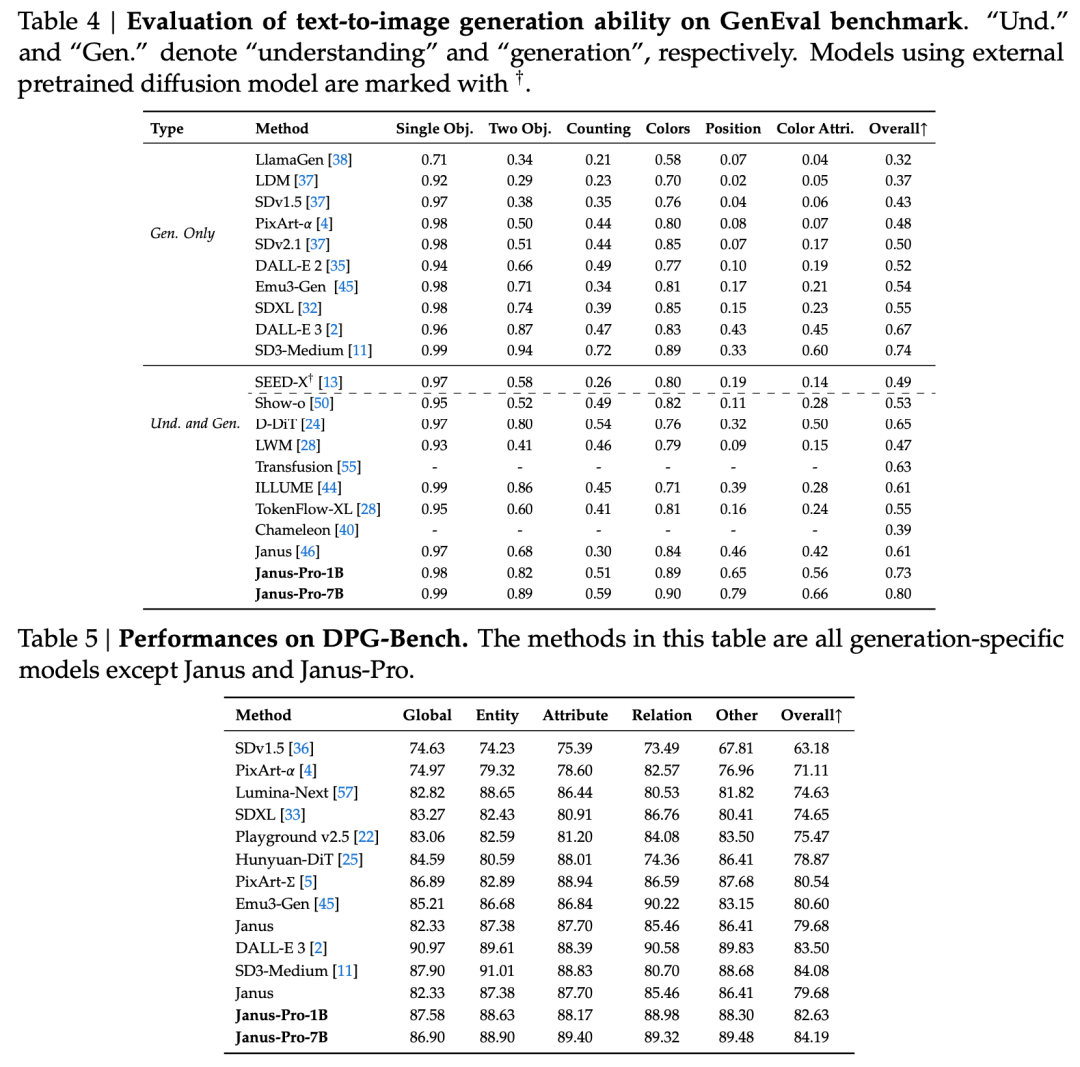
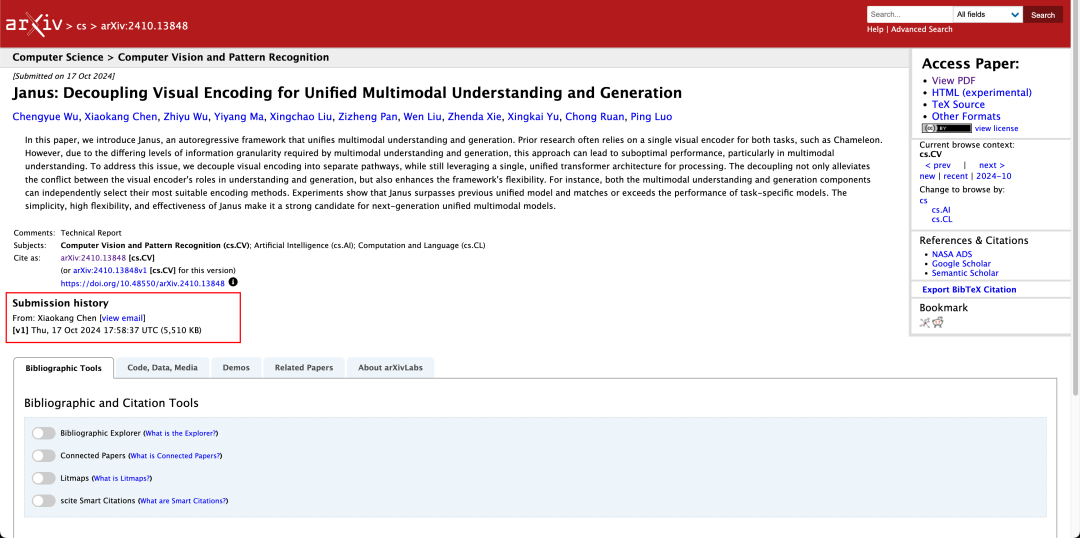
技術報告書では、同タイプで同程度の他のモデルと比較して、Janus-Pro-7BのGenEvalおよびDPG-Benchテストセットでのスコアが以下のように言及されている。 SD3-MediumやDALL-E 3などの他モデルを上回る。
オフィシャルも例を挙げている👇:
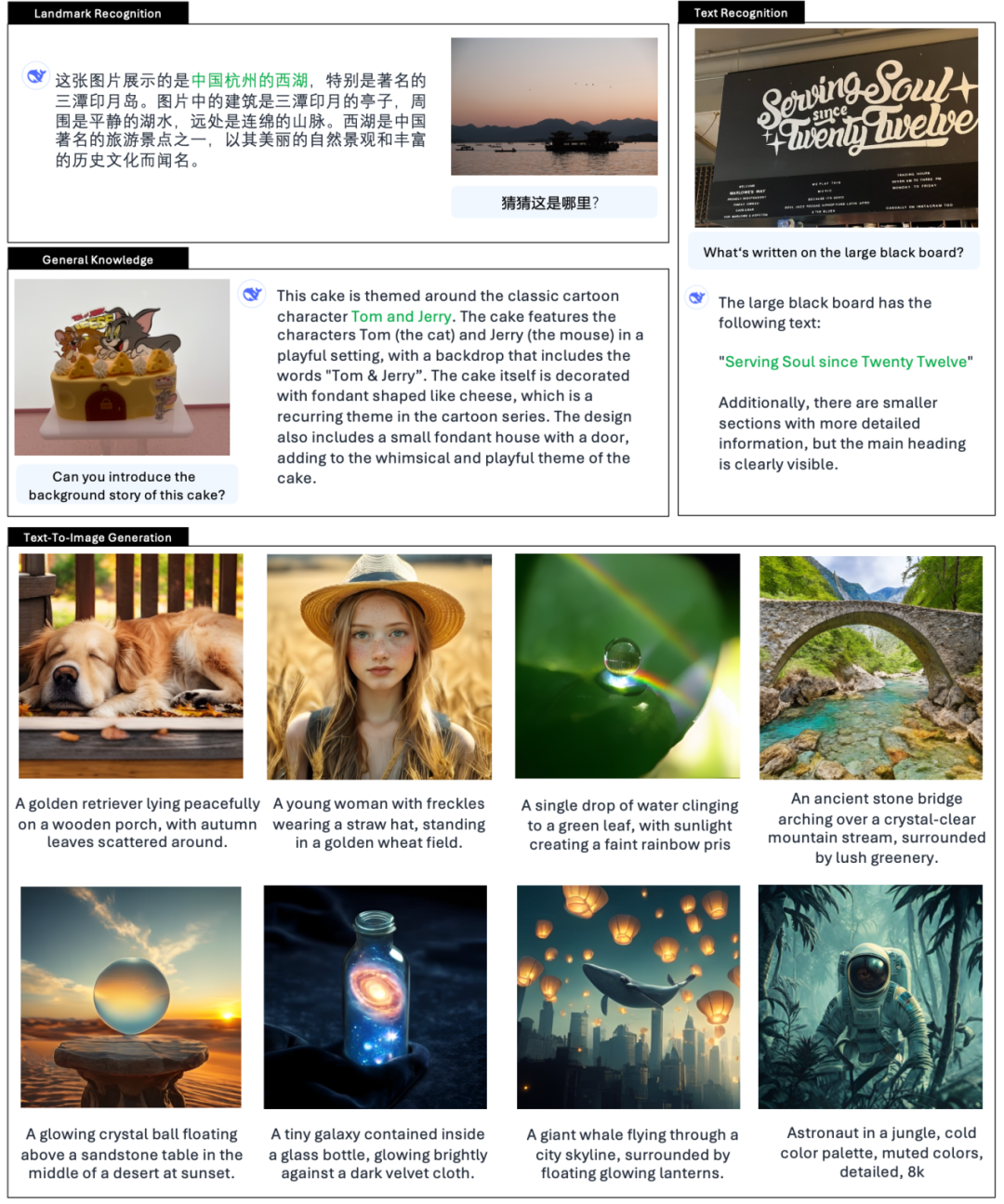
また、Xでは多くのネットユーザーが新機能を試している。

しかし、時折クラッシュもある。
のテクニカルペーパーを参照する。 ディープシークその結果、Janus Proは3ヶ月前にリリースされたJanusをベースにした最適化であることがわかった。
このシリーズの中核となる技術革新は以下の通りである。 視覚理解タスクと視覚生成タスクを切り離し、2つのタスクの効果をバランスさせる。
マルチモーダルな理解と生成を同時に行うモデルも珍しくない。今回のテストセットのD-DiTとTokenFlow-XLは、どちらもこの能力を持っている。
しかし、ヤヌスに特徴的なのは、次の点である。 処理を切り離すことで、マルチモーダルな理解と生成を行うことができるモデルは、2つのタスクの有効性をバランスさせる。
この2つのタスクの有効性をバランスさせることは、業界では難しい問題である。 以前は、同じエンコーダーを使って、できるだけマルチモーダルな理解と生成を実現しようと考えていた。
このアプローチの利点は、シンプルなアーキテクチャ、冗長な展開がないこと、テキストモデル(テキスト生成とテキスト理解を達成するために同じ手法も使用する)との整合性である。また、複数の能力を融合させることで、ある程度の創発性を持たせることもできる。
しかし実際には、生成と理解を融合させた後では、この2つのタスクは相反することになる。画像理解では、モデルが高次元で抽象化し、画像の核となる意味論を抽出する必要があるが、これは巨視的なものに偏っている。一方、画像生成は、ピクセルレベルでの局所的な詳細の表現と生成に重点を置く。
業界の常套手段は、画像生成能力を優先することだ。その結果、以下のようなマルチモーダルモデルが生まれる。 はより高画質な画像を生成できるが、画像理解の結果は平凡なことが多い。
Janusの非結合アーキテクチャとJanus-Proの最適化されたトレーニング戦略
ヤヌスの非結合型アーキテクチャは、モデルがそれ自体で理解と生成のタスクをバランスさせることを可能にする。
公式テクニカルレポートの結果によると、マルチモーダル理解であろうと画像生成であろうと、Janus-Pro-7Bは複数のテストセットで好成績を収めている。

マルチモーダルな理解のために、 Janus-Pro-7Bは、7つの評価データセットのうち4つのデータセットで1位を獲得し、残りの3つのデータセットでも2位を獲得した。
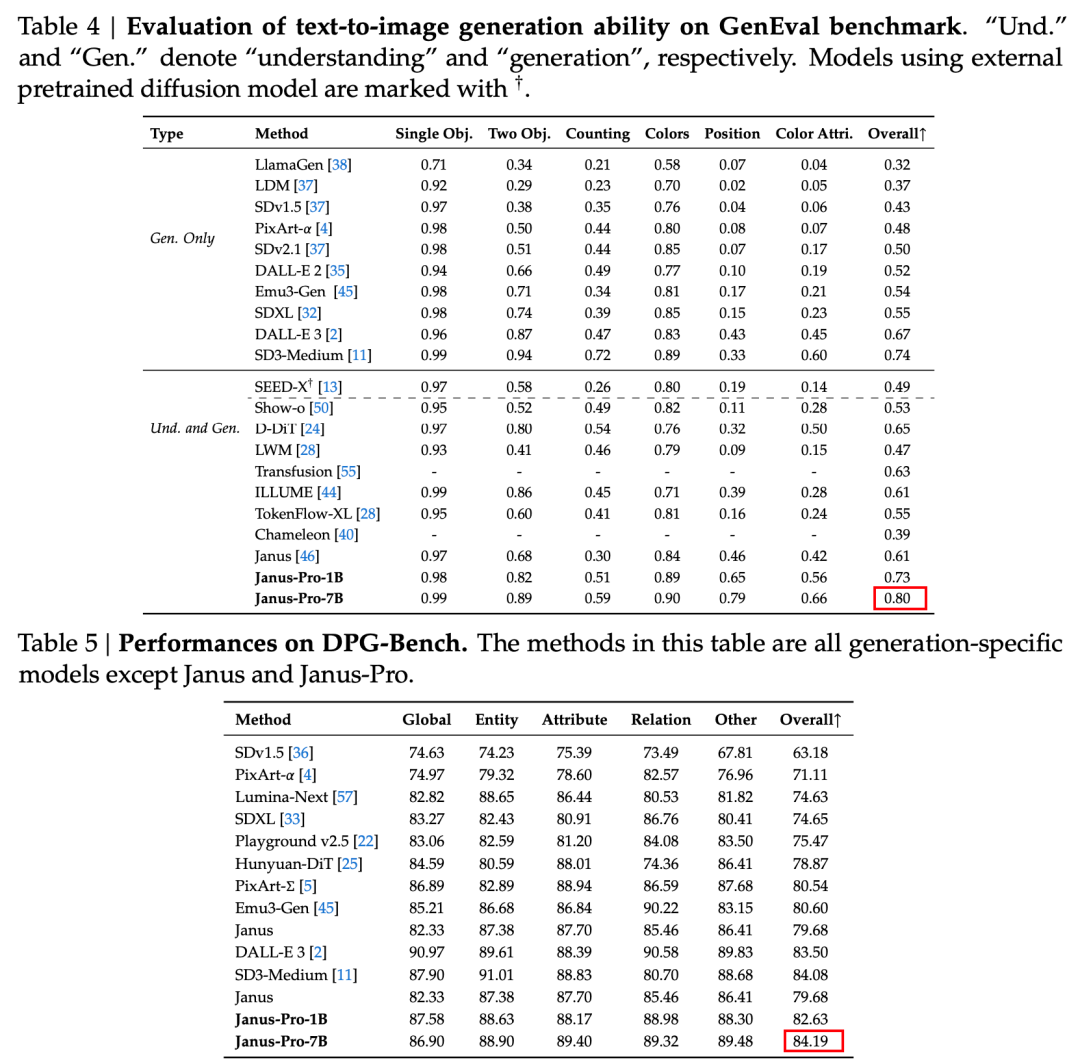
画像生成のため、 Janus-Pro-7Bは、GenEvalとDPG-Benchの両評価データセットで総合スコア1位を獲得した。
このマルチタスク効果は、主にヤヌス・シリーズが異なるタスクに2つの視覚エンコーダーを使用していることによる:
- エンコーダーを理解する: 画像理解タスク(画像の質問と回答、視覚的分類など)のために、画像の意味的特徴を抽出するために使用される。
- ジェネレーティブ・エンコーダー: は、テキストから画像への生成タスクのために、画像を離散表現に変換する(例えば、VQエンコーダを使用する)。
このアーキテクチャでは、 このモデルは、各エンコーダーの性能を独立して最適化できるため、マルチモーダル理解と生成タスクがそれぞれ最高の性能を発揮できる。
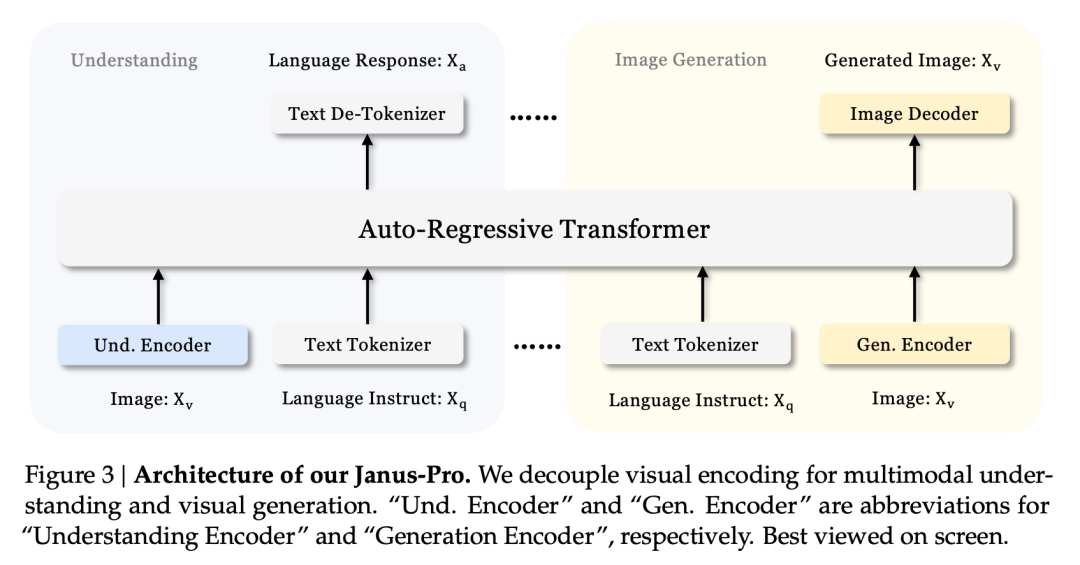
この非連結アーキテクチャは、Janus-Proとヤヌスに共通するものだ。では、Janus-Proはこの数カ月でどのようなイテレーションを繰り返してきたのだろうか?
評価セットの結果からわかるように、今回リリースしたJanus-Pro-1Bは、従来のJanusと比較して、異なる評価セットのスコアが約10%から20%向上している。Janus-Pro-7Bは、パラメータ数を拡張した後のJanusと比較して、約45%と最も向上している。

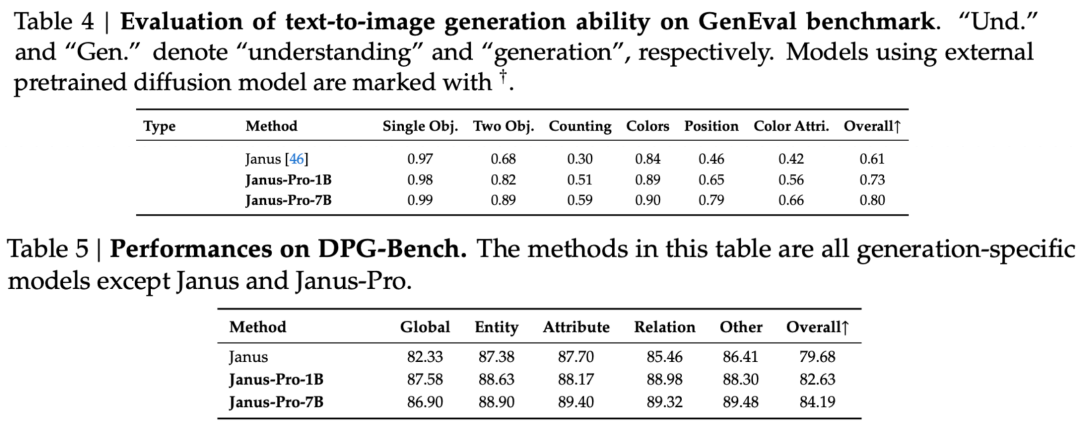
トレーニングの詳細については、技術報告書によると、Janus-Proの現在のリリースは、以前のJanusモデルと比較して、コアとなる非結合型アーキテクチャーの設計を維持し、さらに以下の点を反復している。 パラメータサイズ、トレーニング戦略、トレーニングデータ。
まず、パラメータを見てみよう。.
ヤヌスの最初のバージョンは1.3Bのパラメーターしか持っていなかったが、現在のProのリリースには1Bと7Bのパラメーターを持つモデルが含まれている。
この2つのサイズは、Janusアーキテクチャのスケーラビリティを反映している。最も軽量な1Bモデルは、WebGPUを使用してブラウザー上で実行するために、すでに外部ユーザーによって使用されている。
もある。 その トレーニング戦略。
Janus Proは、ヤヌスのトレーニング・フェーズの区分に従って、全部で3つのトレーニング・フェーズがあり、本稿では直接、ステージI、ステージII、ステージIIIに分けている。
Janus-Proでは、各フェーズの基本的なトレーニングの考え方やトレーニングの目的はそのままに、3つのフェーズにおいてトレーニング期間やトレーニングデータの改善を行いました。以下は、3つの段階における具体的な改善点である:
ステージI - トレーニング時間が長い
Janusと比較して、Janus-ProはStage Iの学習時間、特に視覚部分のアダプタと画像ヘッドの学習時間を延長した。これは、視覚的特徴の学習に多くの学習時間が与えられたことを意味し、モデルが画像の詳細な特徴(画素から意味へのマッピングなど)を完全に理解できるようになることが期待される。
この拡張トレーニングは、視覚部分のトレーニングが他のモジュールによって妨げられないようにするのに役立つ。
ステージ II - ImageNetデータの削除とマルチモーダルデータの追加
ステージIIでは、Janusは事前にPixArtを参照し、2つのパートに分けて学習した。最初のパートは画像分類タスクのImageNetデータセットを使って学習し、2番目のパートは通常のテキストから画像へのデータを使って学習した。ステージIIの約3分の2の時間は、最初の部分の学習に費やされた。
Janus-ProはStage IIでImageNetの学習を削除する。この設計により、モデルはStage IIの学習中、テキストから画像へのデータに集中することができる。実験結果によると、これによりテキストから画像へのデータの利用率を大幅に向上させることができる。
学習方法設計の調整に加え、ステージIIで使用される学習データセットは、単一の画像分類タスクに限定されなくなり、共同学習のために、画像記述や対話など、より多くの他のタイプのマルチモーダルデータも含まれるようになった。
ステージIII - データ比率の最適化
ステージIIIのトレーニングでは、Janus-Proは異なるタイプのトレーニングデータの比率を調整する。
従来、JanusがStage IIIで使用した学習データにおけるマルチモーダル理解データ、プレーンテキストデータ、テキスト画像データの比率は7:3:10であった。Janus-Proでは、後者2種類のデータの比率を減らし、3種類のデータの比率を5:1:4に調整した。
トレーニングデータを見てみよう。
今回のJanus-Proはヤヌスと比較して、高品質なプレーヤーの量を大幅に増加させた。 合成データ。
マルチモーダル理解と画像生成のためのトレーニングデータの量と多様性を拡大する。
マルチモーダル理解データの拡充:
Janus-Proは、学習時にDeepSeek-VL2データセットを参照し、画像記述データセットだけでなく、表やグラフ、文書などの複雑なシーンのデータセットも含め、約9000万点のデータを追加する。
教師ありの微調整段階(ステージIII)では、MEME理解と対話(中国語対話を含む)の経験向上に関連するデータセットを追加し続ける。
ビジュアル生成データの拡張:
元の実世界データは品質が悪く、ノイズレベルも高かったため、テキストから画像への変換タスクでは、モデルの出力が不安定になり、画像の美的品質も不十分だった。
Janus-Proでは、新たに約7,200万件の高美的合成データをトレーニング段階に追加し、事前トレーニング段階における実データと合成データの比率を1:1にした。
合成データのプロンプトはすべて公開リソースから取得した。実験によると、このデータを追加することでモデルの収束が速くなり、生成された画像は安定性と視覚的な美しさが明らかに向上した。
効率革命の継続?
全体として、今回のリリースでDeepSeekはビジュアルモデルに効率化革命をもたらした。
単一の機能に焦点を当てた視覚モデルや、特定のタスクに有利なマルチモーダルモデルとは異なり、Janus-Proは画像生成とマルチモーダル理解という2つの主要タスクの効果を同じモデルでバランスさせている。
さらに、パラメータが小さいにもかかわらず、評価ではOpenAI DALL-E 3とSD3-Mediumを上回った。
地上まで拡張され、企業は画像生成と理解の2つの機能を直接実装するモデルを配置するだけでよい。わずか7Bのサイズと相まって、展開の難易度とコストははるかに低い。
R1とV3のリリースに関連して、ディープシークは次のような既存のゲームルールに挑戦している。 "コンパクトなアーキテクチャーの革新、軽量モデル、オープンソースモデル、超低トレーニングコスト".これが欧米のテクノロジー大手やウォール街のパニックの理由である。
数日前から世論に振り回されていたサム・アルトマンが、ついにXのディープシークに関する情報に肯定的な反応を示した。