
Ⅰ. Czym jest destylacja wiedzy?
Destylacja wiedzy to technika kompresji modelu wykorzystywana do przenoszenia wiedzy z dużego, złożonego modelu (modelu nauczyciela) do małego modelu (modelu ucznia).
Podstawową zasadą jest to, że model nauczyciela uczy model ucznia, przewidując wyniki (takie jak rozkłady prawdopodobieństwa lub procesy wnioskowania), a model ucznia poprawia swoją wydajność, ucząc się na podstawie tych przewidywań.
Metoda ta jest szczególnie odpowiednia dla urządzeń o ograniczonych zasobach, takich jak telefony komórkowe lub urządzenia wbudowane.
II.Podstawowe pojęcia
2.1 Projekt szablonu
- Szablon: Ustrukturyzowany format używany do standaryzacji danych wyjściowych modelu. Na przykład
- : Oznacza początek procesu rozumowania.
- : Oznacza koniec procesu rozumowania.
- : Oznacza początek ostatecznej odpowiedzi.
- : Oznacza koniec ostatecznej odpowiedzi.
- Funkcja:
- Jasność: Podobnie jak "słowa zachęty" w pytaniu typu "wypełnij puste miejsce", mówi modelowi "proces myślenia przebiega tutaj, a odpowiedź tam".
- Spójność: Zapewnia, że wszystkie dane wyjściowe mają taką samą strukturę, co ułatwia późniejsze przetwarzanie i analizę.
- Czytelność: Ludzie mogą łatwo odróżnić proces rozumowania od odpowiedzi, poprawiając wrażenia użytkownika.
2.2 Trajektoria rozumowania: "Łańcuch myślenia" rozwiązania modelu
- Trajektoria rozumowania: Szczegółowe kroki generowane przez model podczas rozwiązywania problemu pokazują logiczny łańcuch modelu.
- Przykład:
2.3 Próbkowanie odrzucające: Filtrowanie dobrych danych na podstawie "prób i błędów
- Próbkowanie odrzuceń: Generowanie wielu odpowiedzi kandydatów i zachowywanie tych dobrych, podobnie jak pisanie wersji roboczej, a następnie kopiowanie poprawnej odpowiedzi na egzaminie.
Ⅲ.Generowanie danych destylowanych
Pierwszym krokiem w procesie destylacji wiedzy jest wygenerowanie wysokiej jakości "danych uczących", na podstawie których małe modele mogą się uczyć.
Źródła danych:
- 80% z danych rozumowania wygenerowanych przez DeepSeek-R1
- 20% z ogólnych danych zadania DeepSeek-V3.
Proces generowania danych destylacji:
- Filtrowanie reguł: automatycznie sprawdza poprawność odpowiedzi (np. czy odpowiedź matematyczna jest zgodna ze wzorem).
- Kontrola czytelnościeliminuje mieszane języki (np. chiński i angielski) lub długie akapity.
- Generowanie oparte na szablonach: wymaga, aby DeepSeek-R1 wyprowadzał trajektorie wnioskowania zgodnie z szablonem.
- Odrzucanie filtrowania próbkowania:
- Integracja danychOstatecznie wygenerowano 800 000 wysokiej jakości próbek, w tym około 600 000 danych wnioskowania i około 200 000 danych ogólnych.
Proces destylacji
Role nauczyciela i ucznia:
- DeepSeek-R1 jako model nauczyciela;
- Modele z serii Qwen jako model studencki.
Etapy szkolenia:
Po pierwsze, wprowadzanie danych: musisz wprowadzić część pytania z 800 000 próbek do modelu Qwen i poprosić go o wygenerowanie pełnej trajektorii wnioskowania (proces myślenia + odpowiedź) zgodnie z szablonem. To bardzo ważny krok
Następnie obliczenie strat: porównanie danych wyjściowych wygenerowanych przez model ucznia z trajektorią wnioskowania modelu nauczyciela i wyrównanie sekwencji tekstu poprzez nadzorowane dostrajanie (SFT). Jeśli nie wiesz, czym jest SFT, mam nadzieję, że wyszukasz to słowo kluczowe, aby dowiedzieć się więcej
Ukończenie aktualizacji parametrów dla większego modelu ucznia: Optymalizacja parametrów modelu Qwen poprzez propagację wsteczną w celu przybliżenia danych wyjściowych modelu nauczyciela.
Wielokrotne powtarzanie tego procesu szkoleniowego zapewnia wystarczający transfer wiedzy. Pozwala to osiągnąć pierwotny cel szkolenia. Podamy przykład, aby to zademonstrować i mamy nadzieję, że to zrozumiesz
Ⅴ. Przykładowa demonstracja
Artykuł demonstruje efekt destylacji poprzez konkretne zadanie rozwiązywania równań (rozwiązywanie równań):
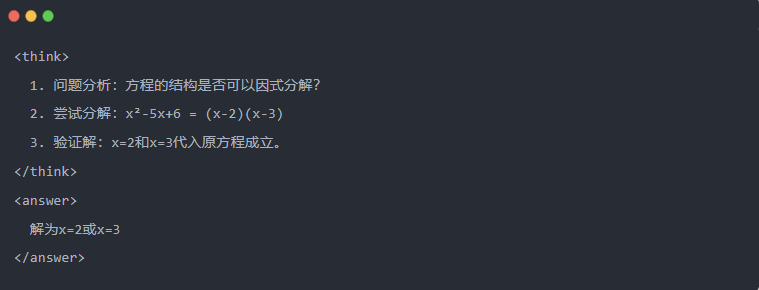
- Standardowe dane wyjściowe modelu nauczyciela:
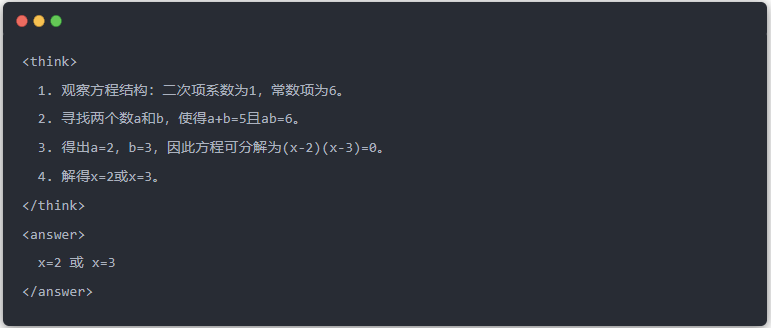
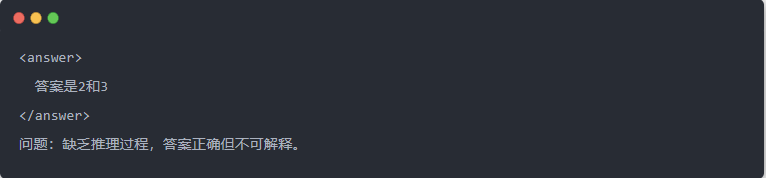
- Wyjście Qwen-7B przed destylacją:
- Wyjście Qwen-7B po destylacji:
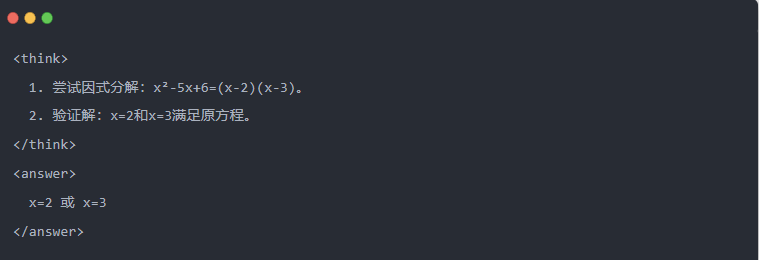
- Zoptymalizowane rozwiązanie: Generowany jest ustrukturyzowany proces wnioskowania, a odpowiedź jest taka sama jak w modelu nauczyciela.
Ⅵ. Podsumowanie
Poprzez destylację wiedzy, zdolność wnioskowania DeepSeek-R1 jest efektywnie migrowana do serii małych modeli Qwen. Proces ten koncentruje się na szablonowych danych wyjściowych i próbkowaniu odrzucenia. Dzięki ustrukturyzowanemu generowaniu danych i wyrafinowanemu szkoleniu małe modele mogą również wykonywać złożone zadania wnioskowania w scenariuszach o ograniczonych zasobach. Technologia ta stanowi ważne odniesienie dla lekkiego wdrażania modeli AI.



