
Ⅰ. Что такое дистилляция знаний?
Дистилляция знаний - это техника сжатия модели, используемая для передачи знаний от большой и сложной модели (модели преподавателя) к маленькой модели (модели ученика).
Основной принцип заключается в том, что модель учителя обучает модель ученика, предсказывая результаты (например, распределения вероятностей или процессы вывода), а модель ученика улучшает свои показатели, обучаясь на этих предсказаниях.
Этот метод особенно подходит для устройств с ограниченными ресурсами, таких как мобильные телефоны или встраиваемые устройства.
II.Основные понятия
2.1 Дизайн шаблона
- Шаблон: Структурированный формат, используемый для стандартизации выходных данных модели. Например
- : Отмечает начало процесса рассуждения.
- : Отмечает конец процесса рассуждения.
- : Обозначает начало окончательного ответа.
- : Обозначает конец окончательного ответа.
- Функция:
- Ясность: Как и "слова-подсказки" в вопросе "заполни пустое место", они подсказывают модели: "Процесс мышления идет здесь, а ответ - там".
- Последовательность: Гарантирует, что все выходные данные имеют одинаковую структуру, что облегчает последующую обработку и анализ.
- Читабельность: человек может легко различить процесс рассуждения и ответ, что улучшает пользовательский опыт.
2.2 Траектория рассуждений: "Цепочка мышления" решения модели
- Траектория рассуждений: Подробные шаги, генерируемые моделью при решении задачи, показывают логическую цепочку модели.
- Пример:
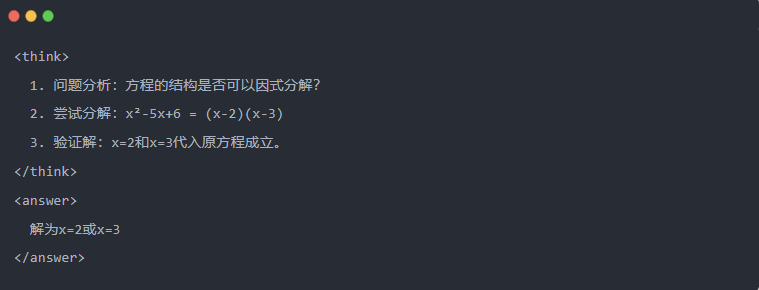
2.3 Выборка отклонений: Фильтрация хороших данных от "проб и ошибок
- Выборка отказов: Генерируйте несколько ответов кандидатов и сохраняйте хорошие, как при написании черновика и последующем копировании правильного ответа на экзамене.
Ⅲ.Генерация дистиллированных данных
Первый шаг в дистилляции знаний - это создание высококачественных "обучающих данных", на которых будут обучаться небольшие модели.
Источники данных:
- 80% из данных рассуждений, созданных DeepSeek-R1
- 20% из данных общего задания DeepSeek-V3.
Процесс генерации дистилляционных данных:
- Фильтрация правил: автоматически проверяет правильность ответа (например, соответствует ли математический ответ формуле).
- Проверка читабельности: исключает смешение языков (например, смешение китайского и английского) или длинные абзацы.
- Генерация, управляемая шаблонами: требует, чтобы DeepSeek-R1 выводил траектории вывода в соответствии с шаблоном.
- Фильтрация выборки отбраковки:
- Интеграция данныхВ итоге было сгенерировано 800 000 высококачественных образцов, включая около 600 000 данных для выводов и около 200 000 общих данных.
Ⅳ.Процесс дистилляции
Роли учителя и ученика:
- DeepSeek-R1 в качестве модели учителя;
- Модели серии Qwen в качестве ученической модели.
Этапы обучения:
Во-первых, ввод данных: вам нужно ввести часть вопроса из 800 000 образцов в модель Qwen и попросить ее сгенерировать полную траекторию умозаключения (процесс мышления + ответ) в соответствии с шаблоном. Это очень важный шаг.
Далее - подсчет потерь: сравнение результатов, полученных моделью ученика, с траекторией вывода модели учителя и выравнивание последовательности текстов с помощью контролируемой тонкой настройки (SFT). Если вы не знаете, что такое SFT, я надеюсь, вы найдете это ключевое слово в поисковике, чтобы узнать больше
Завершите обновление параметров для более крупной модели ученика: Оптимизируйте параметры модели Qwen с помощью обратного распространения, чтобы аппроксимировать выход модели учителя.
Многократное повторение этого процесса обучения гарантирует, что знания будут переданы в достаточном объеме. Таким образом, достигается первоначальная цель обучения. Мы приведем пример, чтобы продемонстрировать это, и надеемся, что вы поймете.
Ⅴ. Пример демонстрации
В статье демонстрируется эффект дистилляции на примере конкретного задания на решение уравнений (solve equation):
- Стандартный вывод модели учителя:
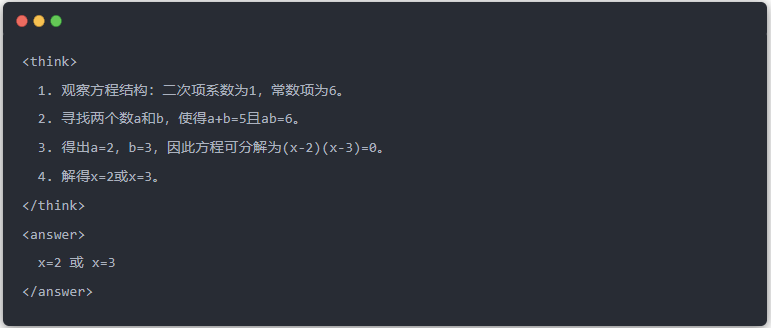
- Выход Qwen-7B перед дистилляцией:
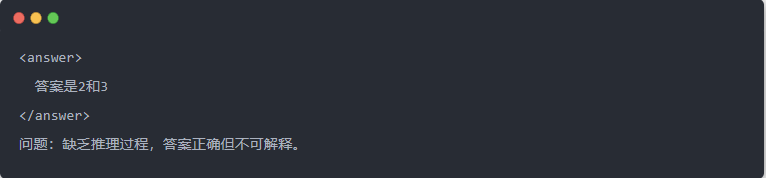
- Выход Qwen-7B после дистилляции:
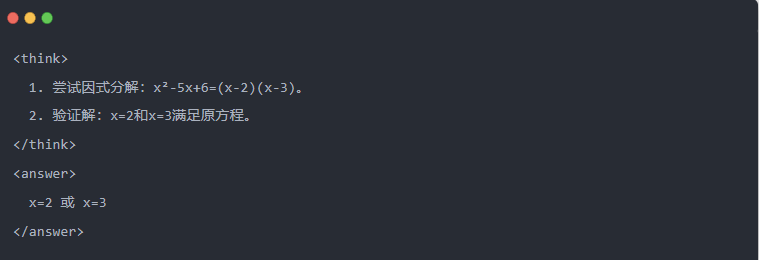
- Оптимизированное решение: Генерируется структурированный процесс вывода, и ответ совпадает с моделью учителя.
Ⅵ. Резюме
Благодаря дистилляции знаний, способность DeepSeek-R1 делать выводы эффективно переносится на серию небольших моделей Qwen. В этом процессе особое внимание уделяется шаблонизированному выводу и выборке отбраковки. Благодаря структурированной генерации данных и усовершенствованному обучению малые модели могут выполнять сложные задачи вывода в сценариях с ограниченными ресурсами. Эта технология является важным эталоном для легкого развертывания моделей ИИ.


