В преддверии весеннего фестиваля вышла модель DeepSeek-R1. Благодаря чистой RL-архитектуре она переняла опыт инноваций CoT и превзошла ChatGPT в математике, кодексе и логических рассуждениях.
Кроме того, открытые веса моделей, низкая стоимость обучения и дешевые цены на API сделали DeepSeek хитом во всем интернете, даже вызвав на некоторое время резкое падение цен на акции NVIDIA и ASML.
Набирая популярность, DeepSeek также выпустила обновленную версию мультимодальной большой модели Janus (Янус), Janus-Pro, которая унаследовала единую архитектуру предыдущего поколения мультимодального понимания и генерации, а также оптимизировала стратегию обучения, масштабируя обучающие данные и размер модели, обеспечивая более высокую производительность.

Janus-Pro
Janus-Pro Это унифицированная мультимодальная языковая модель (MLLM), которая может одновременно обрабатывать мультимодальные задачи понимания и генерации, т.е. понимать содержание картинки и генерировать текст.
Он разделяет визуальные кодировщики для мультимодального понимания и генерации (т. е. на входе для понимания изображения, на входе и выходе для генерации изображения используются разные токенизаторы) и обрабатывает их с помощью унифицированного авторегрессионного трансформатора.
Являясь усовершенствованной мультимодальной моделью понимания и генерации, она представляет собой модернизированную версию предыдущей модели Janus.
В римской мифологии Янус (Janus) - двуликий бог-хранитель, символизирующий противоречие и переход. У него два лица, что также говорит о том, что модель Janus может понимать и генерировать образы, что очень уместно. Так что же именно модернизировал PRO?
Janus, как небольшая модель 1.3B, больше похожа на предварительную версию, чем на официальную. Она исследует унифицированное мультимодальное понимание и генерацию, но имеет множество проблем, таких как нестабильные эффекты генерации изображений, большие отклонения от инструкций пользователя и недостаточная детализация.
Версия Pro оптимизирует стратегию обучения, увеличивает набор обучающих данных и предоставляет большую модель (7B) на выбор, обеспечивая при этом модель 1B.
Архитектура модели
Jaus-Pro и Janus идентичны с точки зрения архитектуры модели. (Всего 1,3 Б! Janus объединяет мультимодальное понимание и генерацию)
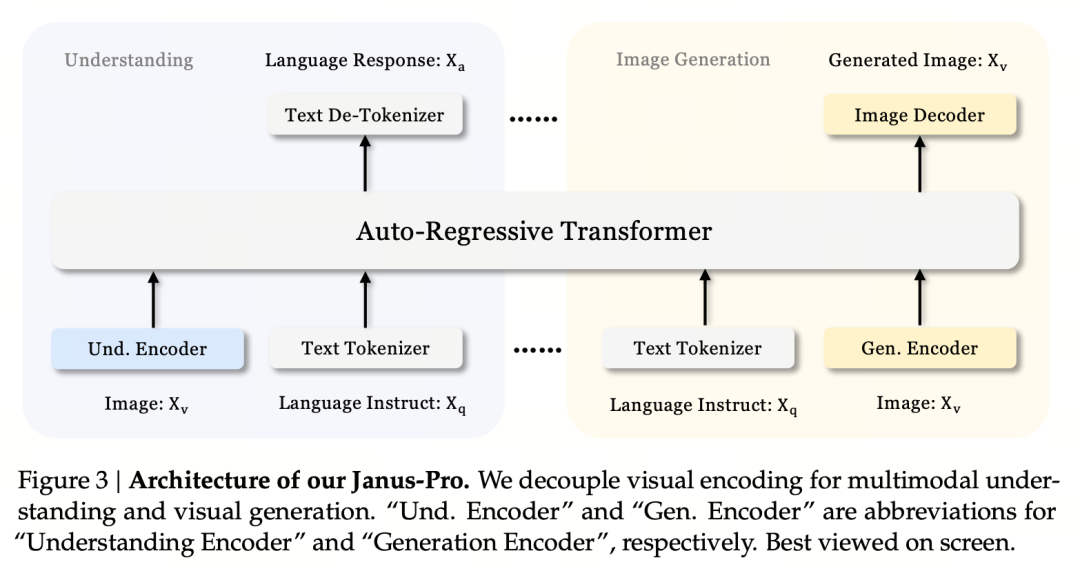
Основной принцип разработки - разделение визуального кодирования для поддержки мультимодального понимания и генерации. Janus-Pro отдельно кодирует исходное изображение/текст, извлекает высокоразмерные признаки и обрабатывает их с помощью унифицированного авторегрессионного трансформатора.
Мультимодальное понимание изображений использует SigLIP для кодирования признаков изображения (синий кодер на рисунке выше), а задача генерации использует VQ-токенизатор для дискретизации изображения (желтый кодер на рисунке выше). Наконец, все последовательности признаков поступают в LLM для обработки
Стратегия обучения
Что касается стратегии обучения, то в Janus-Pro было сделано больше улучшений. В старой версии Janus использовалась трехэтапная стратегия обучения, в которой на первом этапе происходит обучение входного адаптера и головки формирования изображения для понимания и формирования изображения, на втором этапе выполняется унифицированное предварительное обучение, а на третьем этапе на этой основе производится тонкая настройка кодера понимания. (Стратегия обучения Janus показана на рисунке ниже).
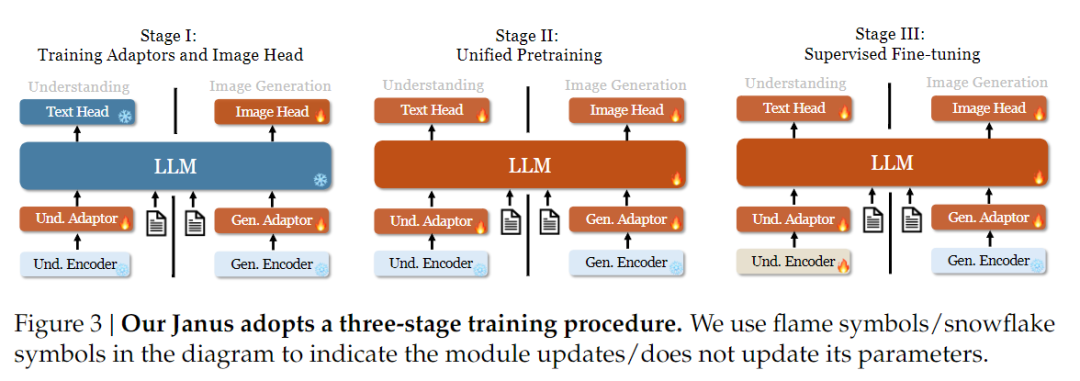
Однако эта стратегия использует метод PixArt для разделения обучения генерации текста в изображение на втором этапе, что приводит к низкой вычислительной эффективности.
Для этого мы увеличили время обучения на первом этапе и добавили обучение на данных ImageNet, чтобы модель могла эффективно моделировать пиксельные зависимости при фиксированных параметрах LLM. На II этапе мы отказались от данных ImageNet и использовали для обучения непосредственно данные пары текст-изображение, что повысило эффективность обучения. Кроме того, на третьем этапе мы изменили соотношение данных (мультимодальные данные:только текст:визуально-семантический граф с 7:3:10 до 5:1:4), улучшив мультимодальное понимание при сохранении возможностей визуальной генерации.
Масштабирование обучающих данных
Janus-Pro также масштабирует обучающие данные Janus с точки зрения мультимодального понимания и визуальной генерации.
Мультимодальное понимание: Данные для предварительного обучения на этапе II основаны на DeepSeek-VL2 и включают около 90 миллионов новых образцов, в том числе данные о подписях к изображениям (например, YFCC) и данные о понимании таблиц, графиков и документов (например, Docmatix).
На этапе III контролируемой тонкой настройки в модель добавляется понимание MEME, данные китайских диалогов и т. д., чтобы улучшить ее многозадачную обработку и диалоговые возможности.
Визуальная генерация: В предыдущих версиях использовались реальные данные низкого качества и с высоким уровнем шума, что влияло на стабильность и эстетику генерируемых текстом изображений.
В Janus-Pro представлено около 72 миллионов синтетических эстетических данных, что позволяет довести соотношение реальных и синтетических данных до 1:1. Эксперименты показали, что синтетические данные ускоряют сходимость модели и значительно повышают стабильность и эстетическое качество генерируемых изображений.
Масштабирование модели
Janus Pro увеличивает размер модели до 7 Б, в то время как предыдущая версия Janus использовала 1,5 Б DeepSeek-LLM для проверки эффективности развязывания визуального кодирования. Эксперименты показывают, что больший размер LLM значительно ускоряет сходимость мультимодального понимания и визуального генерирования, что еще раз подтверждает высокую масштабируемость метода.

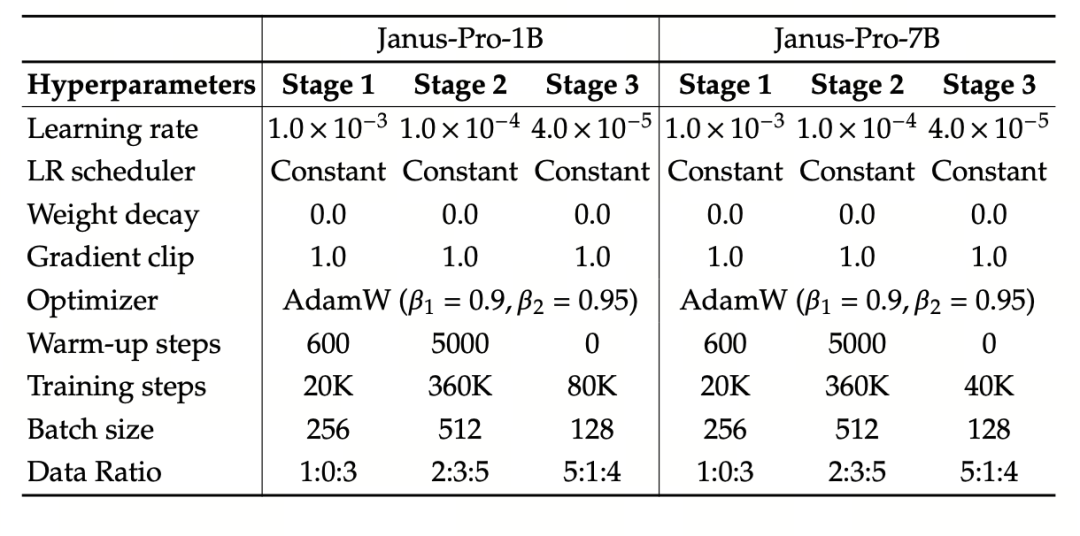
В качестве базовой языковой модели в эксперименте используется DeepSeek-LLM (1.5B и 7B, поддерживающая максимальную последовательность 4096). Для задачи мультимодального понимания в качестве визуального кодера используется SigLIP-Large-Patch16-384, размер словаря кодера составляет 16384, кратность понижающей дискретизации изображения - 16, а адаптеры понимания и генерации представляют собой двухслойные MLP.
На втором этапе обучения используется стратегия ранней остановки 270K, все изображения равномерно подгоняются под разрешение 384×384, а для повышения эффективности обучения используется упаковка последовательностей. Janus-Pro обучен и оценен с помощью HAI-LLM. Версии 1.5B/7B обучались на 16/32 узлах (8×Nvidia A100 по 40 ГБ на узел) в течение 9/14 дней соответственно.
Оценка модели
Janus-Pro оценивался отдельно по мультимодальному пониманию и генерации. В целом, понимание может быть немного слабым, но оно считается отличным среди открытых моделей того же размера (предположительно, оно в значительной степени ограничено фиксированным разрешением ввода и возможностями OCR).
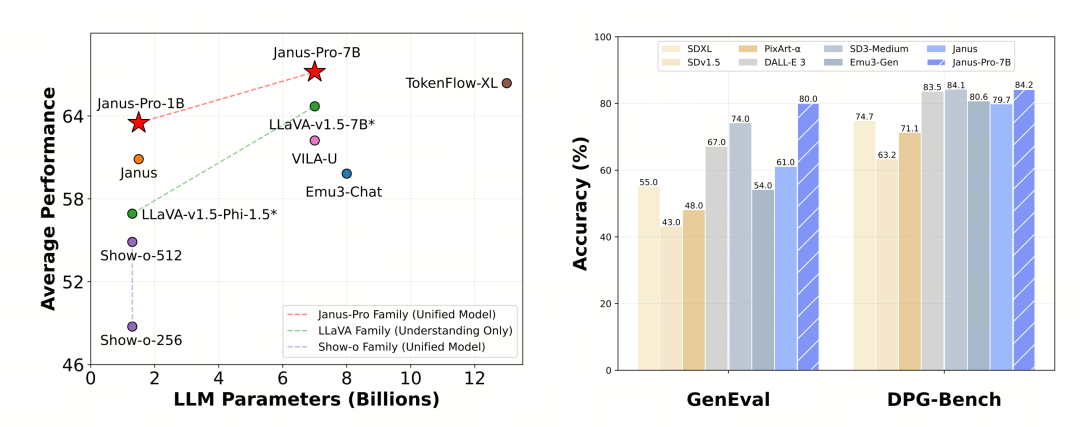
Janus-Pro-7B набрал 79,2 балла в бенчмарк-тесте MMBench, что близко к уровню моделей первого уровня с открытым исходным кодом (аналогичный показатель InternVL2.5 и Qwen2-VL составляет около 82 баллов). Тем не менее, это хорошее улучшение по сравнению с предыдущим поколением Janus.
В плане генерации изображений улучшение по сравнению с предыдущим поколением еще более значительное, и это считается отличным уровнем среди моделей с открытым исходным кодом. Результат Janus-Pro в бенчмарк-тесте GenEval (0,80) также превосходит такие модели, как DALL-E 3 (0,67) и Stable Diffusion 3 Medium (0,74).