
Ⅰ. Che cos'è la distillazione della conoscenza?
La distillazione della conoscenza è una tecnica di compressione del modello utilizzata per trasferire la conoscenza da un modello grande e complesso (il modello dell'insegnante) a un modello piccolo (il modello dello studente).
Il principio fondamentale è che il modello insegnante insegna al modello studente prevedendo i risultati (come le distribuzioni di probabilità o i processi di inferenza) e il modello studente migliora le sue prestazioni imparando da queste previsioni.
Questo metodo è particolarmente adatto ai dispositivi con risorse limitate, come i telefoni cellulari o i dispositivi embedded.
II.Concetti fondamentali
2.1 Progettazione del modello
- Modello: Un formato strutturato utilizzato per standardizzare l'output del modello. Ad esempio
- : Segna l'inizio del processo di ragionamento.
- : Segna la fine del processo di ragionamento.
- : Indica l'inizio della risposta finale.
- : Indica la fine della risposta finale.
- Funzione:
- Chiarezza: Come le "parole guida" in una domanda a riempimento di spazi vuoti, indica al modello "il processo di riflessione va qui e la risposta va lì".
- Coerenza: Assicura che tutti gli output seguano la stessa struttura, facilitando l'elaborazione e l'analisi successive.
- Leggibilità: gli esseri umani possono distinguere facilmente tra il processo di ragionamento e la risposta, migliorando l'esperienza dell'utente.
2.2 Traiettoria di ragionamento: La "catena di pensiero" della soluzione del modello
- Traiettoria del ragionamento: Le fasi dettagliate generate dal modello durante la risoluzione di un problema mostrano la catena logica del modello.
- Esempio:
2.3 Campionamento di scarto: Filtrare i dati buoni da "prove ed errori
- Campionamento di scarto: Generare più risposte candidate e conservare quelle buone, come se si scrivesse una bozza e poi si copiasse la risposta corretta in un esame.
Ⅲ.Generazione di dati distillati
Il primo passo nella distillazione della conoscenza è la generazione di "dati didattici" di alta qualità da cui i piccoli modelli possano imparare.
Fonti di dati:
- 80% dai dati di ragionamento generati da DeepSeek-R1
- 20% dai dati generali di DeepSeek-V3.
Processo di generazione dei dati di distillazione:
- Filtraggio delle regole: verifica automaticamente la correttezza della risposta (ad esempio, se la risposta matematica è conforme alla formula).
- Controllo della leggibilità: elimina le lingue miste (ad es. cinese e inglese) o i paragrafi lunghi.
- Generazione guidata da modellirichiede a DeepSeek-R1 di produrre traiettorie di inferenza secondo il modello.
- Filtraggio del campionamento di rifiuto:
- Integrazione dei datiSono stati infine generati 800.000 campioni di alta qualità, di cui circa 600.000 dati di inferenza e circa 200.000 dati generali.
Ⅳ.Processo di distillazione
Ruolo dell'insegnante e dello studente:
- DeepSeek-R1 come modello di insegnante;
- Modelli della serie Qwen come modello di studente.
Fasi di formazione:
Innanzitutto, l'inserimento dei dati: è necessario inserire la parte di domanda degli 800.000 campioni nel modello Qwen e chiedergli di generare una traiettoria di inferenza completa (processo di pensiero + risposta) secondo il modello. Questo è un passo molto importante
Quindi, il calcolo delle perdite: confrontare l'output generato dal modello dello studente con la traiettoria di inferenza del modello dell'insegnante e allineare la sequenza di testo attraverso la messa a punto supervisionata (SFT). Se non siete sicuri di cosa sia la SFT, cercate questa parola chiave per saperne di più.
Completare gli aggiornamenti dei parametri per il modello più grande dello studente: Ottimizzare i parametri del modello Qwen tramite backpropagation per approssimare l'output del modello insegnante.
La ripetizione di questo processo di formazione più volte garantisce un trasferimento sufficiente delle conoscenze. In questo modo si raggiunge l'obiettivo formativo originale. Vi forniamo un esempio per dimostrarlo e ci auguriamo che possiate capire
Ⅴ. Esempio di dimostrazione
L'articolo dimostra l'effetto di distillazione attraverso un compito specifico di risoluzione di equazioni (solve equation):
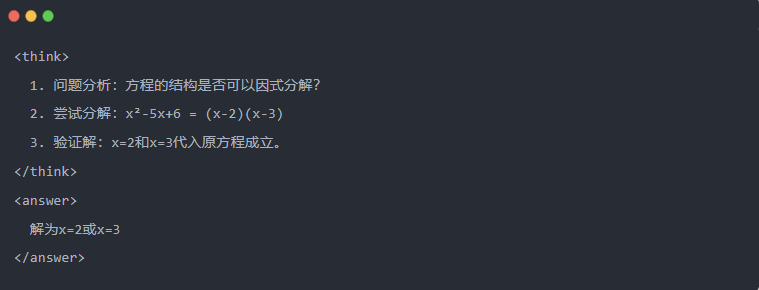
- Output standard del modello insegnante:
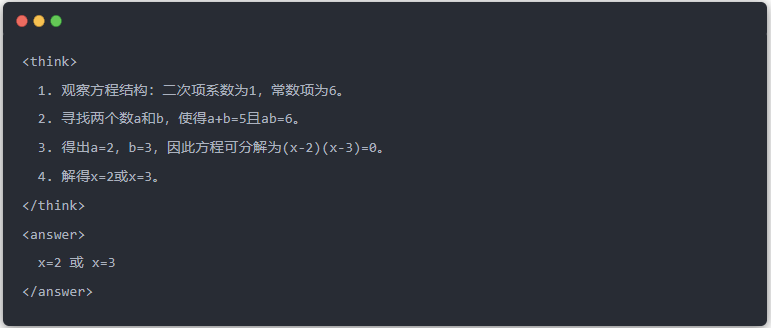
- Uscita del Qwen-7B prima della distillazione:
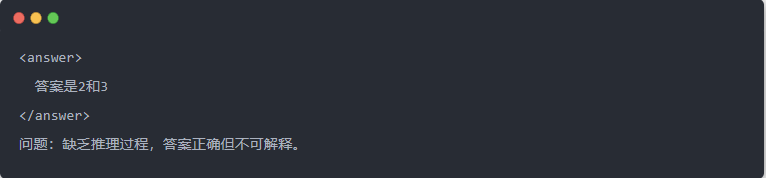
- Uscita Qwen-7B dopo la distillazione:
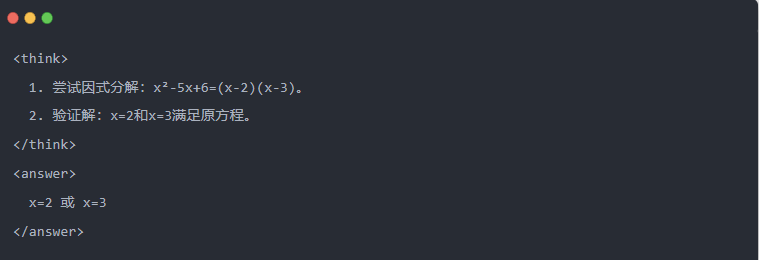
- Soluzione ottimizzata: Viene generato un processo di inferenza strutturato e la risposta è la stessa del modello dell'insegnante.
Ⅵ. Sintesi
Attraverso la distillazione della conoscenza, la capacità di inferenza di DeepSeek-R1 viene migrata in modo efficiente alla serie di piccoli modelli Qwen. Questo processo si concentra sull'output templato e sul campionamento di scarto. Grazie alla generazione di dati strutturati e all'addestramento raffinato, i modelli di piccole dimensioni possono eseguire compiti di inferenza complessi anche in scenari con risorse limitate. Questa tecnologia fornisce un importante riferimento per l'implementazione leggera di modelli di intelligenza artificiale.



