

Punti salienti
🔹 Architettura del trasformatore unificato: Un unico modello gestisce la comprensione delle immagini e generazione, eliminando la necessità di sistemi separati.
🔹 Scalabile e open source: Disponibile in 1B e 7B versioni parametriche (con licenza MIT), ottimizzate per diverse applicazioni e uso commerciale.
🔹 Prestazioni all'avanguardia: Supera DALL-E 3 e Stable Diffusion di OpenAI in benchmark come GenEval e DPG-Bench.
🔹 Distribuzione semplificata: L'architettura semplificata riduce i costi di formazione/intervento mantenendo la flessibilità.
Link al modello
- Janus-Pro-7B: Faccia da abbracciare
- Janus-Pro-1B: Faccia da abbracciare
- GitHub: Codice e documenti
Perché Janus-Pro si distingue
1. Due superpoteri in un unico modello
- Modalità di comprensione: Usi SigLIP-L (i "superocchiali") per analizzare immagini (fino a 384×384) e testo.
- Modalità di generazione: Leveraggi Flusso rettificato + SDXL-VAE (il "pennello magico") per creare immagini di alta qualità.
2. Potenza cerebrale e formazione
- Core LLM: Costruito sul potente modello linguistico di DeepSeek (1,5B/7B parametri), che eccelle nel ragionamento contestuale.
- Linea di formazione: Pre-training su enormi insiemi di dati → Messa a punto supervisionata → Ottimizzazione dell'EMA per ottenere le massime prestazioni.
3. Perché la sovradiffusione del trasformatore?
- Versatilità del compito: Privilegia la comprensione e la generazione unificata, mentre i modelli di diffusione si concentrano esclusivamente sulla qualità dell'immagine.
- Efficienza: Generazione autoregressiva (a passo singolo) e denoising iterativo della diffusione (ad esempio, 20 passi per la diffusione stabile).
- Costo-efficacia: Un'unica dorsale Transformer semplifica la formazione e l'implementazione.
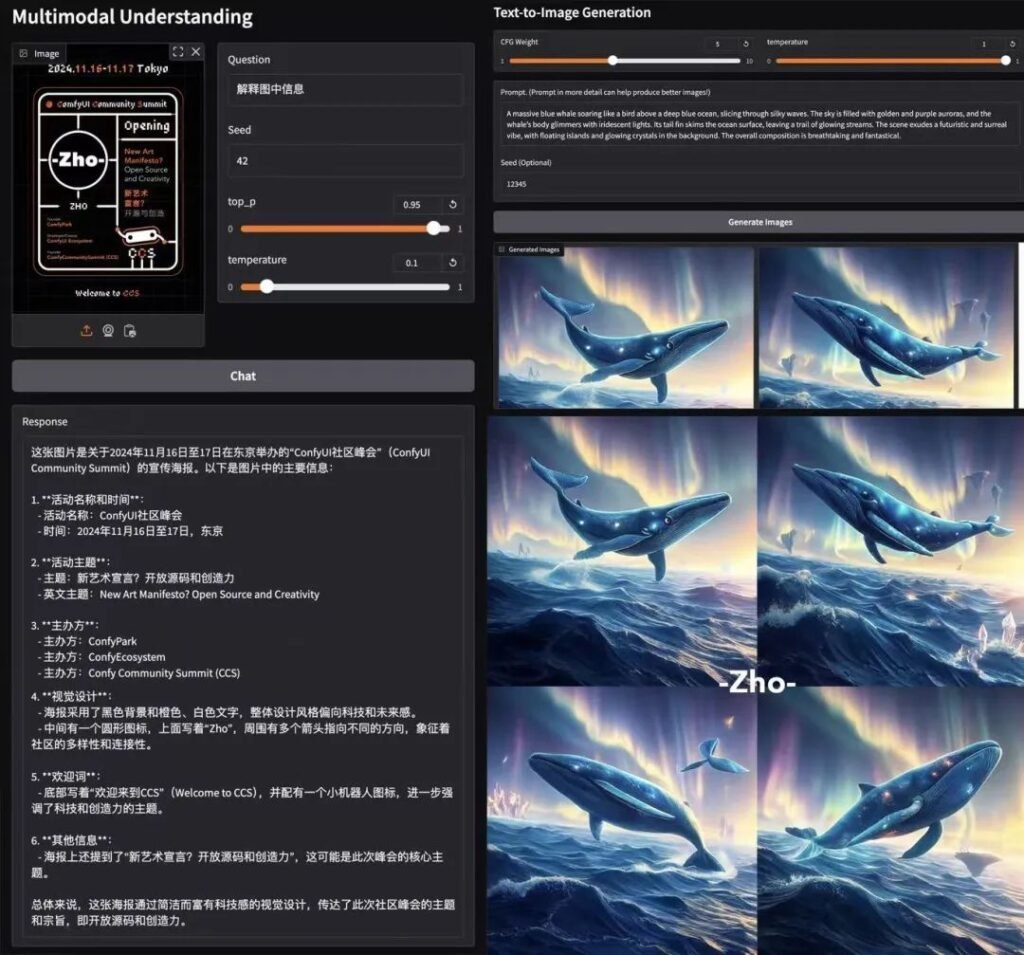
Dominanza del benchmark
📊 Comprensione multimodale
L'Janus-Pro-7B supera i modelli specializzati (ad esempio, LLaVA) su quattro benchmark chiave, con una scala uniforme con la dimensione dei parametri.
🎨 Generazione da testo a immagine
- GenEval: Corrisponde a SDXL e DALL-E 3.
- Banco DPG: 84.2% precisione (Janus-Pro-7B), superando tutti i concorrenti.
Test nel mondo reale
- Velocità: ~15 secondi/immagine (GPU L4, 22 GB di VRAM).
- Qualità: Forte aderenza ai tempi, anche se i dettagli minori devono essere perfezionati.
- Demo di Colab: Prova Janus-Pro-7B (è richiesto il livello Pro).
Ripartizione tecnica
Architettura
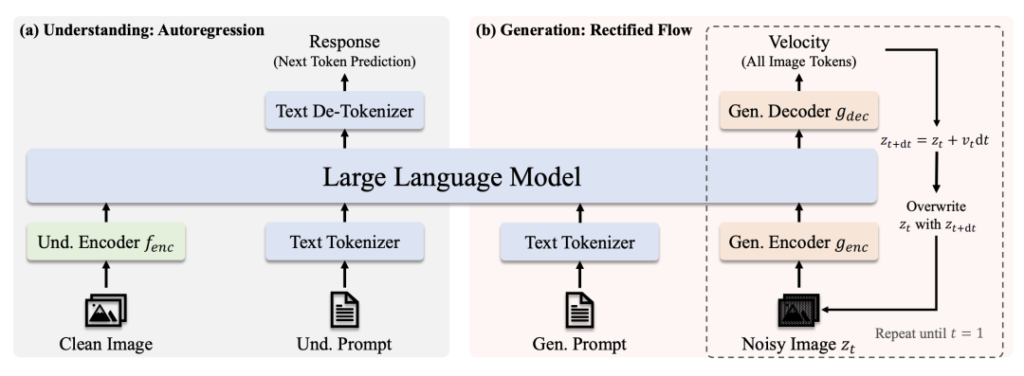
- Comprensione del percorso: Immagine pulita → Codificatore SigLIP-L → LLM → Risposta testuale.
- Percorso di generazione: Immagine rumorosa → Decodificatore di flusso rettificato + LLM → Denoising iterativo.
Innovazioni chiave
- Codifica visiva disaccoppiata: Percorsi separati per la comprensione/generazione impediscono il "conflitto di ruolo" nei moduli di visione.
- Nucleo del trasformatore condiviso: Permette di trasferire le conoscenze tra i vari compiti (ad esempio, l'apprendimento dei concetti di "gatto" aiuta sia il riconoscimento che il disegno).
Buzz della comunità
AK (Ricercatore AI): "La semplicità e la flessibilità dell'Janus-Pro lo rendono un candidato privilegiato per i sistemi multimodali di prossima generazione. Disaccoppiando i percorsi visivi e mantenendo un trasformatore unificato, bilancia la specializzazione con la generalizzazione: un'impresa rara".
Perché la licenza MIT è importante
- Libertà: Utilizzate, modificate e distribuite commercialmente con restrizioni minime.
- Trasparenza: L'accesso completo al codice accelera i miglioramenti della comunità.
Conclusione
L'Janus-Pro di DeepSeek non è solo un altro modello di AI: è un cambiamento di paradigma. Unificando la comprensione e la generazione sotto un unico tetto, apre le porte a strumenti creativi più intelligenti, applicazioni in tempo reale e implementazioni efficienti dal punto di vista dei costi. Con l'accesso open-source e la licenza MIT, potrebbe essere il catalizzatore della prossima ondata di innovazione multimodale. 🚀
Per gli sviluppatori: Date un'occhiata al sito Nodi ComfyUI e unirsi all'onda della sperimentazione!
questo post è sponsorizzato da:




