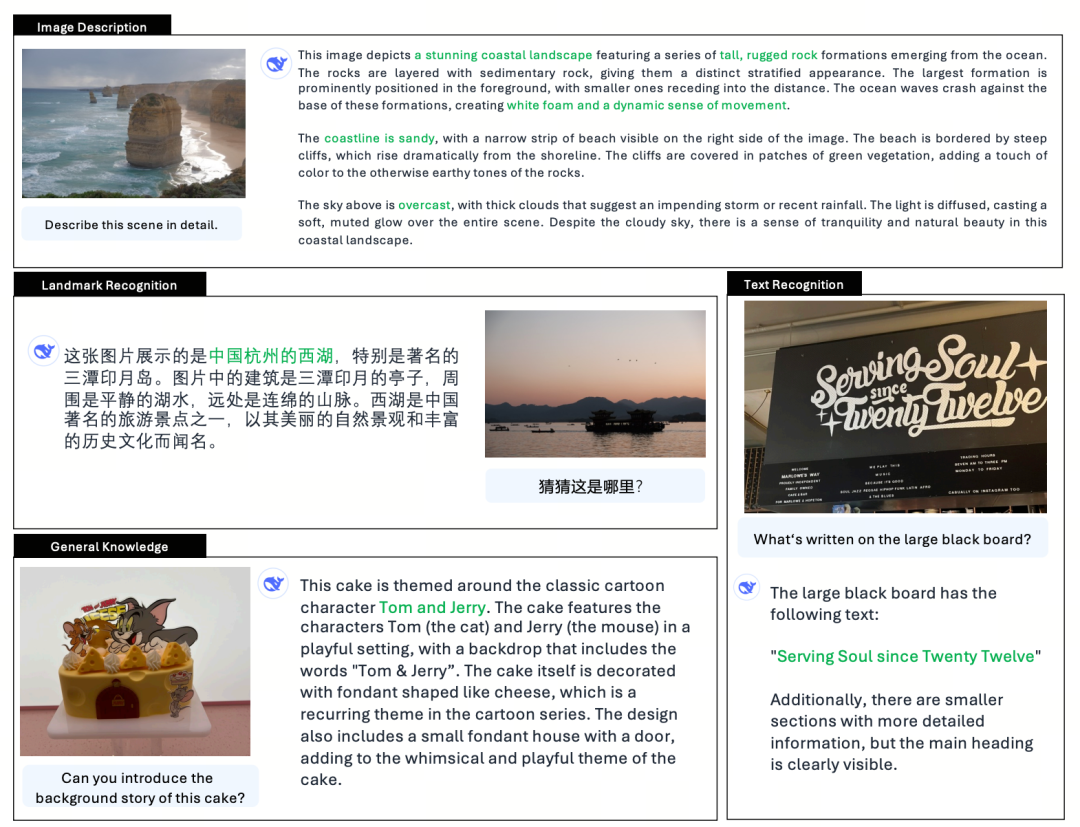
Alla vigilia del Festival di Primavera, è stato rilasciato il modello DeepSeek-R1. Con la sua architettura RL pura, ha imparato dalle grandi innovazioni di CoT e supera le prestazioni di ChatGPT in matematica, codice e ragionamento logico.
Inoltre, i pesi dei modelli open-source, i bassi costi di addestramento e i prezzi convenienti delle API hanno reso DeepSeek un successo su Internet, facendo addirittura crollare i prezzi delle azioni di NVIDIA e ASML per un certo periodo.
Mentre esplode la popolarità, DeepSeek ha anche rilasciato una versione aggiornata del modello multimodale di grandi dimensioni Janus (Giano), Janus-Pro, che eredita l'architettura unificata della precedente generazione di comprensione e generazione multimodale, e ottimizza la strategia di addestramento, scalando i dati di addestramento e le dimensioni del modello, portando prestazioni più forti.

Janus-Pro
Janus-Pro è un modello linguistico multimodale unificato (MLLM) in grado di elaborare simultaneamente compiti di comprensione multimodale e di generazione, cioè di comprendere il contenuto di un'immagine e di generare testo.
Disaccoppia i codificatori visivi per la comprensione e la generazione multimodale (cioè, vengono utilizzati tokenizer diversi per l'ingresso della comprensione delle immagini e per l'ingresso e l'uscita della generazione delle immagini) e li elabora utilizzando un trasformatore autoregressivo unificato.
Come modello avanzato di comprensione e generazione multimodale, è una versione aggiornata del precedente modello Janus.
Nella mitologia romana, Giano (Janus) è un dio guardiano bifronte che simboleggia la contraddizione e la transizione. Ha due facce, il che suggerisce anche che il modello Giano può comprendere e generare immagini, il che è molto appropriato. Quindi, che cosa ha aggiornato esattamente PRO?
Janus, come piccolo modello di 1.3B, è più simile a una versione di anteprima che a una versione ufficiale. Esplora la comprensione e la generazione multimodale unificata, ma presenta molti problemi, come effetti di generazione di immagini instabili, grandi deviazioni dalle istruzioni dell'utente e dettagli inadeguati.
La versione Pro ottimizza la strategia di addestramento, aumenta il set di dati di addestramento e fornisce un modello più ampio (7B) tra cui scegliere, pur fornendo un modello 1B.
Modello di architettura
Jaus-Pro e Janus sono identici in termini di architettura del modello. (Solo 1,3B! Janus unifica la comprensione e la generazione multimodale)
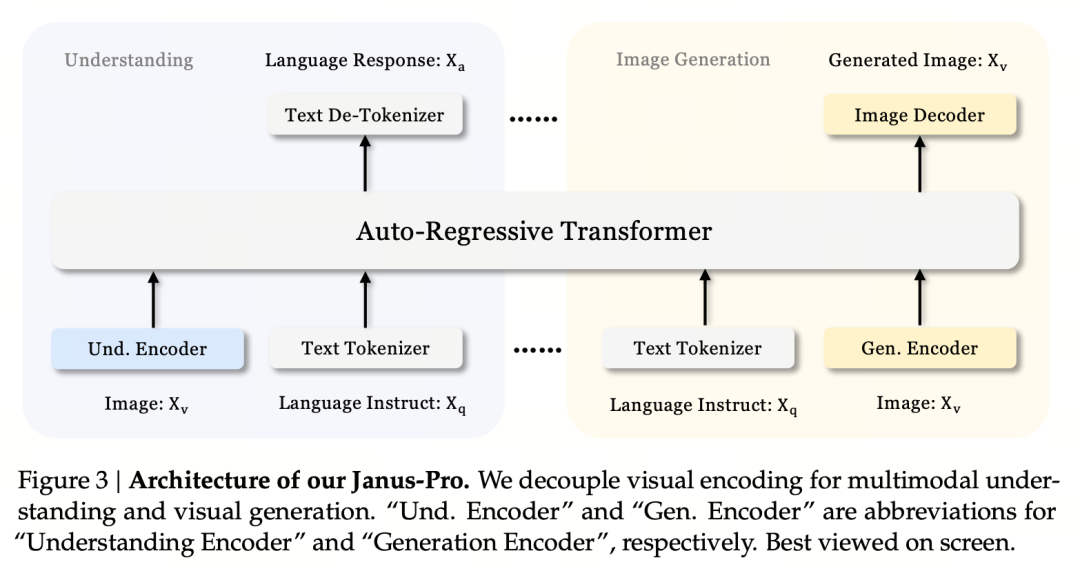
Il principio di base del progetto consiste nel disaccoppiare la codifica visiva per supportare la comprensione e la generazione multimodale. Janus-Pro codifica separatamente l'immagine originale e il testo in ingresso, estrae caratteristiche ad alta dimensionalità e le elabora attraverso un trasformatore autoregressivo unificato.
La comprensione multimodale delle immagini utilizza SigLIP per codificare le caratteristiche dell'immagine (codificatore blu nella figura precedente), mentre il compito di generazione utilizza il tokenizer VQ per discretizzare l'immagine (codificatore giallo nella figura precedente). Infine, tutte le sequenze di caratteristiche vengono inviate all'LLM per l'elaborazione.
Strategia di formazione
In termini di strategia di addestramento, Janus-Pro ha apportato ulteriori miglioramenti. La vecchia versione di Janus utilizzava una strategia di addestramento a tre fasi, in cui la Fase I addestrava l'adattatore di ingresso e la testa di generazione delle immagini per la comprensione e la generazione delle immagini, la Fase II eseguiva un pre-addestramento unificato e la Fase III metteva a punto il codificatore di comprensione su questa base. (La strategia di addestramento di Janus è illustrata nella figura seguente).
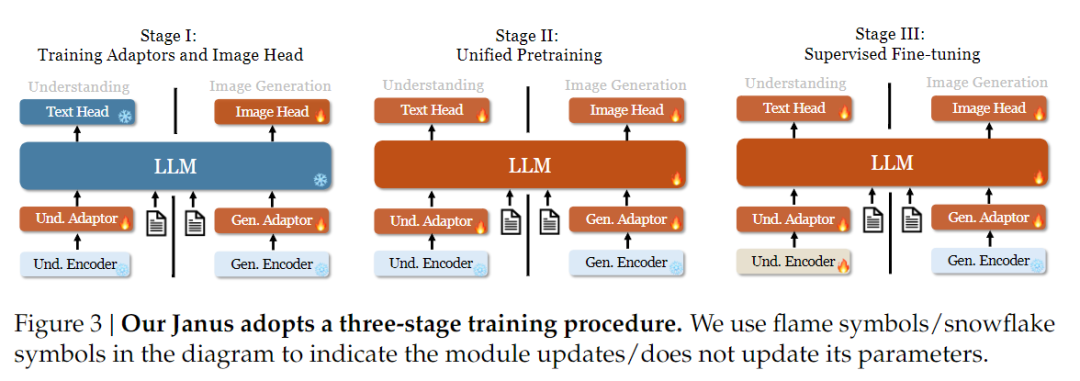
Tuttavia, questa strategia utilizza il metodo PixArt per suddividere l'addestramento della generazione da testo a immagine nella fase II, con conseguente bassa efficienza computazionale.
A tal fine, abbiamo esteso il tempo di addestramento della Fase I e aggiunto l'addestramento con i dati di ImageNet, in modo che il modello possa modellare efficacemente le dipendenze dai pixel con parametri LLM fissi. Nella fase II, abbiamo scartato i dati di ImageNet e abbiamo utilizzato direttamente i dati della coppia testo-immagine per l'addestramento, migliorando così l'efficienza dell'addestramento. Inoltre, nella fase III abbiamo modificato il rapporto tra i dati (dati multimodali:solo testo:grafo visivo-semantico da 7:3:10 a 5:1:4), migliorando la comprensione multimodale e mantenendo le capacità di generazione visiva.
Scala dei dati di addestramento
Janus-Pro scala anche i dati di addestramento di Janus in termini di comprensione multimodale e generazione visiva.
Comprensione multimodale: I dati della fase II di pre-addestramento si basano su DeepSeek-VL2 e comprendono circa 90 milioni di nuovi campioni, tra cui dati di didascalie di immagini (come YFCC) e dati di comprensione di tabelle, grafici e documenti (come Docmatix).
La fase III di messa a punto supervisionata introduce ulteriormente la comprensione di MEME, i dati di dialogo cinesi, ecc. per migliorare le prestazioni del modello nell'elaborazione multi-task e le capacità di dialogo.
Generazione visiva: Le versioni precedenti utilizzavano dati reali di bassa qualità ed elevato rumore, che influivano sulla stabilità e sull'estetica delle immagini generate dal testo.
Janus-Pro introduce circa 72 milioni di dati estetici sintetici, portando a 1:1 il rapporto tra dati reali e dati sintetici. Gli esperimenti hanno dimostrato che i dati sintetici accelerano la convergenza del modello e migliorano significativamente la stabilità e la qualità estetica delle immagini generate.
Scala del modello
Janus Pro estende la dimensione del modello a 7B, mentre la versione precedente di Janus utilizzava 1,5B DeepSeek-LLM per verificare l'efficacia del disaccoppiamento della codifica visiva. Gli esperimenti dimostrano che un LLM più grande accelera significativamente la convergenza della comprensione multimodale e della generazione visiva, verificando ulteriormente la forte scalabilità del metodo.

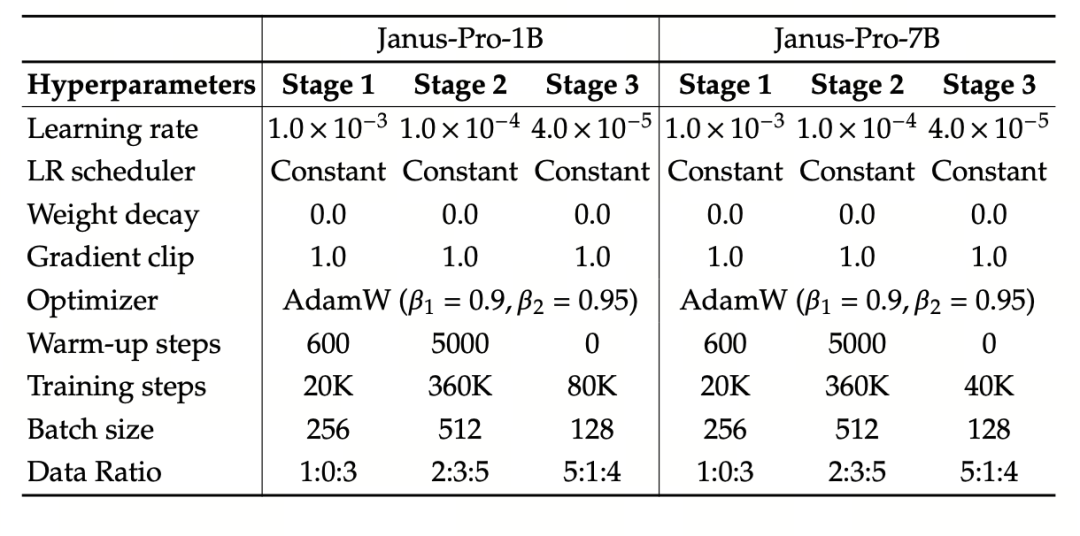
L'esperimento utilizza DeepSeek-LLM (1,5B e 7B, che supporta una sequenza massima di 4096) come modello linguistico di base. Per il compito di comprensione multimodale, si utilizza SigLIP-Large-Patch16-384 come codificatore visivo, la dimensione del dizionario del codificatore è di 16384, il multiplo di downsampling dell'immagine è di 16 e entrambi gli adattatori di comprensione e generazione sono MLP a due strati.
La fase II dell'addestramento utilizza una strategia di arresto precoce a 270K, tutte le immagini sono regolate uniformemente a una risoluzione di 384×384 e il confezionamento della sequenza viene utilizzato per migliorare l'efficienza dell'addestramento. Janus-Pro è stato addestrato e valutato utilizzando HAI-LLM. Le versioni 1.5B/7B sono state addestrate su 16/32 nodi (8×Nvidia A100 40GB per nodo) per 9/14 giorni rispettivamente.
Valutazione del modello
Janus-Pro è stato valutato separatamente nella comprensione e nella generazione multimodale. Nel complesso, la comprensione può essere leggermente debole, ma è considerata eccellente tra i modelli open source della stessa dimensione (si suppone che sia in gran parte limitata dalla risoluzione fissa dell'input e dalle capacità OCR).
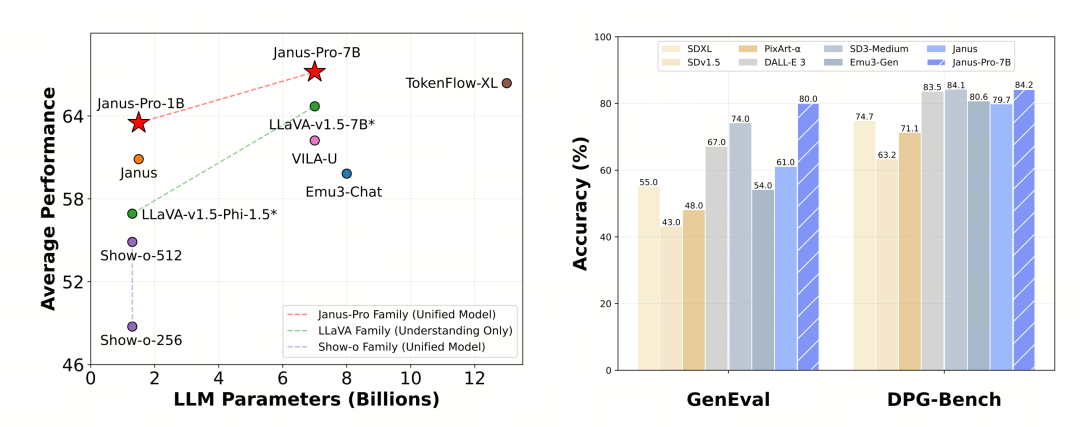
L'Janus-Pro-7B ha ottenuto un punteggio di 79,2 nel test di benchmark MMBench, che si avvicina al livello dei modelli open source di primo livello (la stessa dimensione di InternVL2.5 e Qwen2-VL è di circa 82 punti). Tuttavia, si tratta di un buon miglioramento rispetto alla precedente generazione di Janus.
In termini di generazione di immagini, il miglioramento rispetto alla generazione precedente è ancora più significativo ed è considerato un livello eccellente tra i modelli open source. Il punteggio di Janus-Pro nel test di benchmark GenEval (0,80) supera anche modelli come DALL-E 3 (0,67) e Stable Diffusion 3 Medium (0,74).