
Ⅰ. 知識の蒸留とは何か?
知識蒸留は、大きく複雑なモデル(教師モデル)から小さなモデル(生徒モデル)に知識を伝達するために使用されるモデル圧縮技術です。
核となる原理は、教師モデルが結果(確率分布や推論プロセスなど)を予測することによって生徒モデルに教え、生徒モデルはこれらの予測から学習することによってパフォーマンスを向上させるというものである。
この方法は、携帯電話や組み込み機器など、リソースに制約のある機器に特に適している。
II.コア・コンセプト
2.1 テンプレートデザイン
- テンプレート:モデルの出力を標準化するために使用される構造化されたフォーマット。例
- :推理プロセスの始まりを示す。
- :推理プロセスの終了を示す。
- :最終的な答えの始まりを示す。
- :最終的な答えの終わりを示す。
- 機能:
- 明確さ:穴埋め問題の「促しの言葉」のように、「思考プロセスはここにあり、答えはそこにある」ということをモデルに伝える。
- 一貫性:すべての出力が同じ構造に従っていることを保証し、その後の処理や分析を容易にする。
- 読みやすさ:人間は推論プロセスと答えを容易に区別することができ、ユーザーエクスペリエンスを向上させる。
2.2 推論の軌跡:モデル解答の「思考の連鎖
- 推論の軌跡:問題を解く際にモデルが生成する詳細なステップは、モデルの論理的連鎖を示す。
- 例
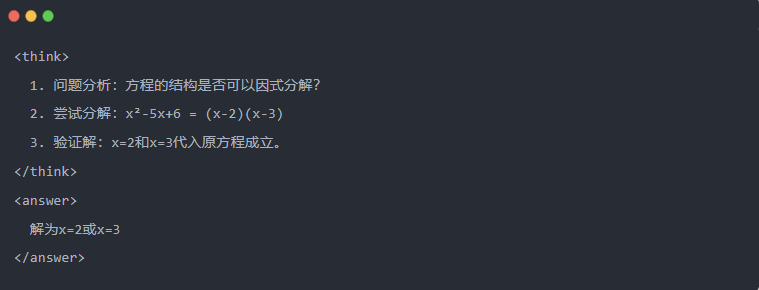
2.3 拒否サンプリング:試行錯誤」から良いデータを選別する
- 不合格サンプリング:試験で下書きを書いてから正解を書き写すのと同じように、複数の回答候補を作成し、良いものを残す。
.蒸留データの生成
知識抽出の最初のステップは、小さなモデルが学習するための高品質な「ティーチングデータ」を生成することである。
データソース:
- によって生成された推論データから80%を得た。 ディープシーク-R1
- DeepSeek-V3の一般タスクデータから20%。
蒸留データ生成プロセス:
- ルール・フィルタリング例えば、数学的な答えが数式に合っているかどうかなど)。
- 読みやすさのチェック中国語と英語の混在言語や長い段落を排除。
- テンプレート誘導型生成DeepSeek-R1がテンプレートに従って推論軌跡を出力する必要があります。
- 拒絶サンプリング・フィルタリング:
- データ統合最終的に、約60万件の推論データと約20万件の一般データを含む、80万件の高品質サンプルが生成された。
IV.蒸留プロセス
教師と生徒の役割
- 教師モデルとしてのDeepSeek-R1;
- Qwenシリーズの学生モデル。
トレーニングのステップ
まず、データ入力:80万サンプルの質問部分をQwenモデルに入力し、テンプレートに従って完全な推論の軌跡(思考プロセス+回答)を生成するように依頼する必要がある。これは非常に重要なステップである
次に、損失計算:生徒モデルが生成した出力と教師モデルの推論軌跡を比較し、教師あり微調整(SFT)によりテキスト列を揃える。SFTとは何かわからない方は、このキーワードで検索していただければと思います。
生徒の大きなモデルのパラメータ更新を完了する:教師モデルの出力を近似するために、バックプロパゲーションを通してQwenモデルのパラメータを最適化する。
このトレーニングプロセスを何度も繰り返すことで、知識が十分に伝達される。これにより、本来のトレーニングの目的が達成される。このことを実証するために例を挙げますので、ご理解いただければ幸いです。
Ⅴ.デモンストレーション例
この記事では、特定の方程式を解くタスク(方程式を解く)を通して、蒸留効果を実証している:
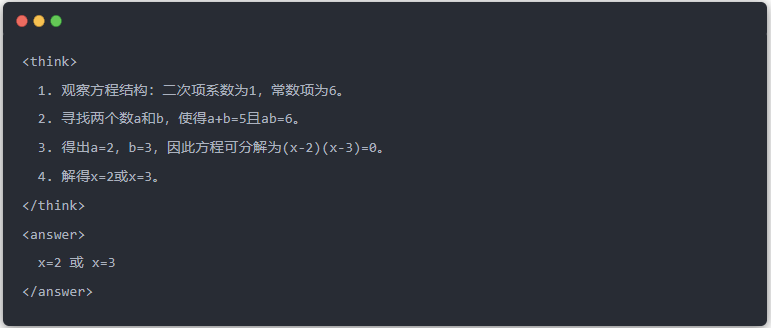
- 教師モデルの標準出力:
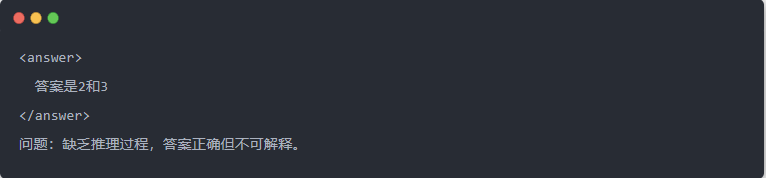
- 蒸留前のQwen-7Bの出力:
- 蒸留後のQwen-7Bの出力:
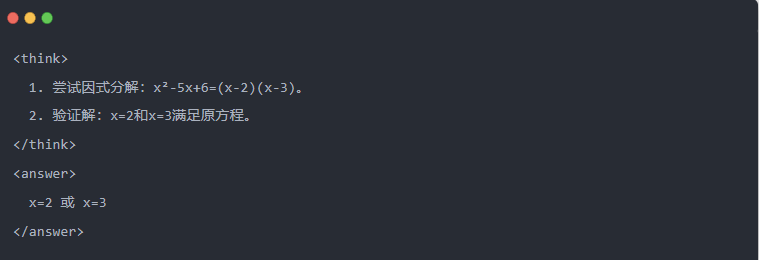
- 最適化された解:構造化された推論プロセスが生成され、答えは教師モデルと同じになる。
Ⅵ.まとめ
知識の蒸留を通じて、DeepSeek-R1 の推論能力は、Qwen シリーズの小さなモデルに効率的に移行されます。このプロセスは、テンプレート化された出力と拒絶サンプリングに重点を置いています。構造化されたデータ生成と洗練された学習により、小型モデルはリソースに制約のあるシナリオでも複雑な推論タスクを実行することができる。この技術は、AIモデルの軽量展開のための重要なリファレンスを提供する。



