春節の前夜、DeepSeek-R1モデルがリリースされた。純粋なRLアーキテクチャーを採用し、CoTの偉大な革新から学んだこのモデルは、以下を凌駕する。 チャットGPT 数学、コード、論理的推論において。
さらに、オープンソースのモデルウェイト、低いトレーニングコスト、安価なAPI価格は、ディープシークをインターネット上でヒットさせ、エヌビディアとASMLの株価を一時急落させたほどだ。
爆発的な人気を博す一方で、DeepSeekはマルチモーダル大型モデルJanus(ヤヌス)のアップデート版であるJanus-Proもリリースしており、前世代のマルチモーダル理解・生成の統一アーキテクチャを継承しつつ、学習戦略を最適化し、学習データとモデルサイズを拡張することで、より強力なパフォーマンスをもたらしている。

Janus-Pro
Janus-Pro マルチモーダル言語モデル(MLLM)は、マルチモーダル理解タスクと生成タスクを同時に処理することができる。
マルチモーダル理解と生成のための視覚的エンコーダを切り離し(つまり、画像理解の入力と画像生成の入力と出力に異なるトークナイザを使用)、統一された自己回帰変換器を使用して処理する。
先進的なマルチモーダル理解・生成モデルとして、従来のヤヌス・モデルのアップグレード版である。
ローマ神話では、ヤヌス(Janus)は矛盾と変遷を象徴する2つの顔を持つ守護神である。彼は2つの顔を持っており、ヤヌスモデルがイメージを理解し、生成できることも示唆しており、非常に適切である。では、PROは具体的に何をアップグレードしたのか?
Janusは1.3Bの小型モデルであり、正式版というよりはプレビュー版に近い。統一的なマルチモーダル理解と生成を探求しているが、不安定な画像生成効果、ユーザー指示との大きな乖離、不十分な細部など多くの問題を抱えている。
Proバージョンは、トレーニング戦略を最適化し、トレーニングデータセットを増やし、1Bモデルを提供しながら、より大きなモデル(7B)から選択できるようにする。
モデル・アーキテクチャ
ジャウス・プロとヤヌス はモデル・アーキテクチャの点で同一である。(たった1.3億ドル!マルチモーダルな理解と生成を可能にするヤヌス)
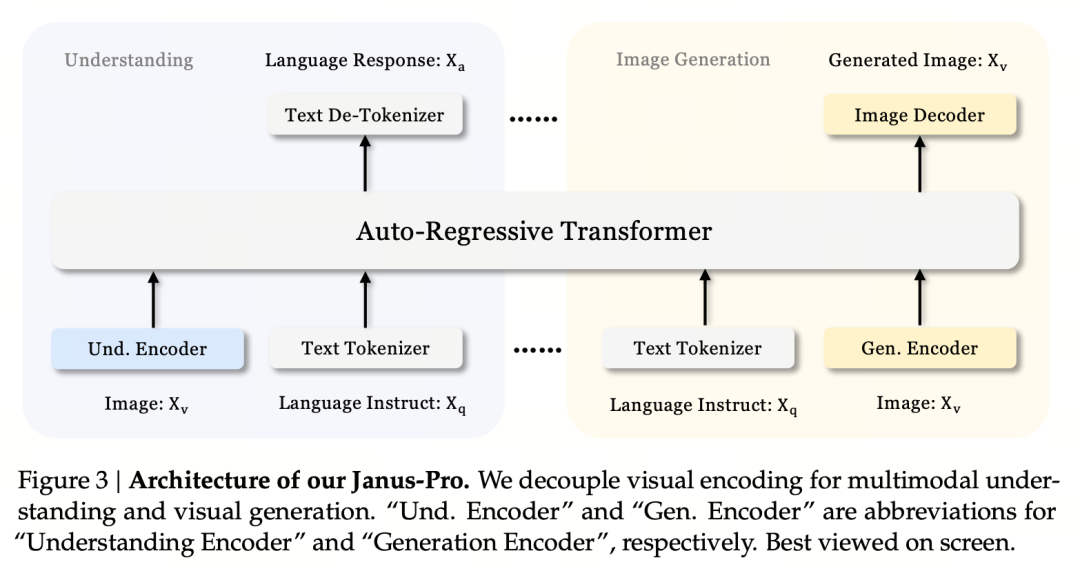
核となる設計原理は、マルチモーダルな理解と生成をサポートするために、視覚的エンコーディングを切り離すことである。Janus-Proは元の画像/テキスト入力を別々にエンコードし、高次元の特徴を抽出し、統一された自己回帰変換器を通して処理する。
マルチモーダル画像理解では、SigLIPを使用して画像の特徴を符号化し(上図の青色のエンコーダー)、生成タスクではVQトークナイザーを使用して画像を離散化する(上図の黄色のエンコーダー)。最後に、すべての特徴列はLLMに入力され、処理される。
トレーニング戦略
トレーニング戦略に関しては、Janus-Proはさらに改良を加えている。旧バージョンのJanusは3段階のトレーニング戦略を採用しており、ステージIでは画像理解と画像生成のために入力アダプターと画像生成ヘッドをトレーニングし、ステージIIでは統一的な事前トレーニングを行い、ステージIIIではこれに基づいて理解エンコーダを微調整する。(ヤヌスのトレーニング戦略を下図に示す)。
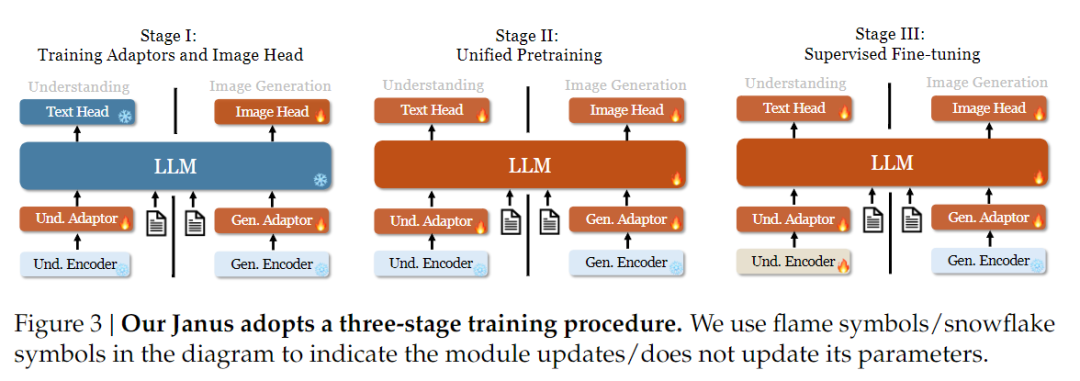
しかし、この戦略では、PixArt法を使用して、ステージIIでテキストから画像への生成の学習を分割するため、計算効率が低くなる。
そのため、ステージIの学習時間を延長し、ImageNetデータを用いた学習を追加することで、固定LLMパラメータで効果的に画素依存性をモデル化できるようにした。StageIIでは、ImageNetのデータを破棄し、テキストと画像のペアデータを直接学習に用いることで、学習効率を向上させた。また、ステージIIIではデータ比率を調整し(マルチモーダル:テキストのみ:視覚的意味グラフデータを7:3:10から5:1:4に)、視覚的生成能力を維持しつつマルチモーダル理解を向上させた。
トレーニングデータのスケーリング
Janus-Proはまた、マルチモーダル理解とビジュアル生成という点で、ヤヌスのトレーニングデータをスケールアップする。
マルチモーダル理解:ステージIIの事前学習データはDeepSeek-VL2に基づいており、画像キャプションデータ(YFCCなど)、表、グラフ、文書理解データ(Docmatixなど)を含む約9000万の新しいサンプルが含まれている。
ステージIIIの教師あり微調整ステージでは、さらにMEME理解、中国語対話データなどを導入し、マルチタスク処理と対話能力におけるモデルの性能を向上させる。
ビジュアル生成:以前のバージョンでは、低品質でノイズの多い実データを使用していたため、テキスト生成画像の安定性と美観に影響を与えていた。
Janus-Proは約7200万件の合成美的データを導入し、実データと合成データの比率を1:1にした。実験によると、合成データはモデルの収束を早め、生成される画像の安定性と美的品質を大幅に向上させます。
モデルのスケーリング
Janus Proはモデルサイズを7Bまで拡張したが、Janusの前バージョンは1.5BのDeepSeek-LLMを使用し、視覚エンコーディングをデカップリングすることの有効性を検証した。実験によると、より大きなLLMはマルチモーダル理解と視覚生成の収束を大幅に加速し、この手法の強力なスケーラビリティをさらに検証している。

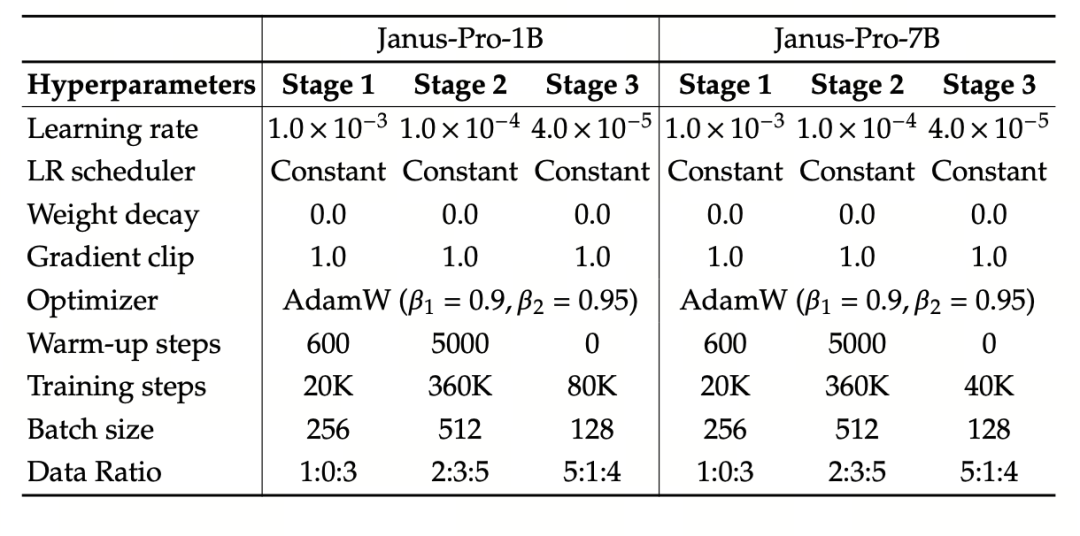
実験では、基本言語モデルとしてDeepSeek-LLM(1.5Bと7B、最大4096シーケンスをサポート)を使用。マルチモーダル理解タスクでは、視覚エンコーダとしてSigLIP-Large-Patch16-384を使用し、エンコーダの辞書サイズは16384、画像のダウンサンプリング倍率は16、理解および生成アダプタはともに2層MLPである。
StageIIの学習は270Kの早期停止ストラテジーを使用し、全ての画像は384×384の解像度に均一に調整され、学習効率を向上させるためにシーケンスパッケージが使用される。Janus-ProはHAI-LLMを用いて学習・評価される。1.5B/7Bバージョンはそれぞれ16/32ノード(ノードあたり8×Nvidia A100 40GB)で9/14日間学習された。
モデル評価
Janus-Proはマルチモーダル理解と生成で別々に評価された。全体として、理解力はやや弱いかもしれないが、同じサイズのオープンソースモデルの中では優れていると考えられる(固定された入力解像度とOCR機能によって大きく制限されていると推測される)。
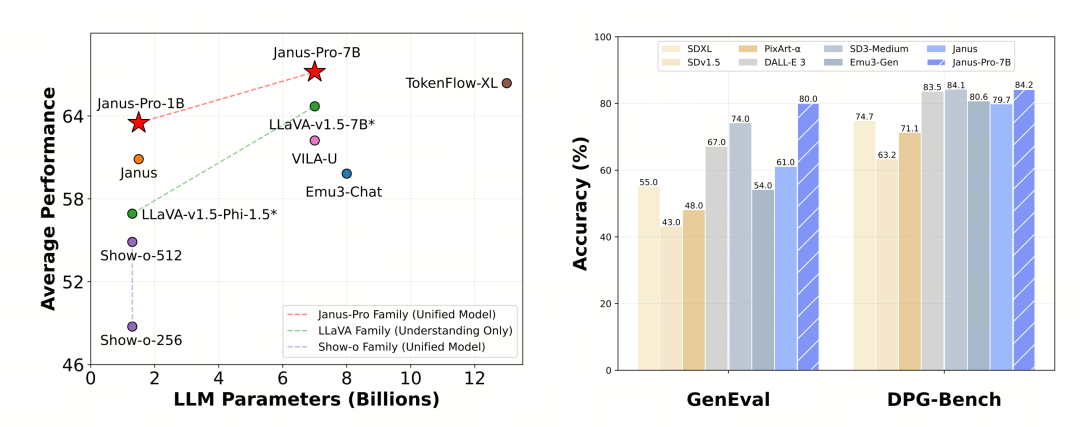
Janus-Pro-7BはMMBenchベンチマークテストで79.2点を記録し、オープンソースの一流モデル(同規模のInternVL2.5やQwen2-VLは82点前後)に近いレベルだ。しかし、前世代のJanusに比べれば、十分な改善である。
画像生成に関しては、前世代からの改善がさらに顕著で、オープンソースのモデルの中では優秀なレベルと考えられる。GenEvalベンチマークテストにおけるJanus-Proのスコア(0.80)も、DALL-E 3(0.67)やStable Diffusion 3 Medium(0.74)といったモデルを上回っている。