

分享GPT-4o-Image 是一個大規模、高品質的影像生成資料集,其中所有影像均使用 GPT-4o 的影像生成功能產生。
該資料集旨在將開源多模態模型的優勢與 GPT-4o 在視覺內容創作方面的優勢結合。
它包含 45,000 個文字到圖像和 46,000 個圖像到文字的樣本,使其成為增強圖像生成和編輯任務中的多模式模型的實用資源。

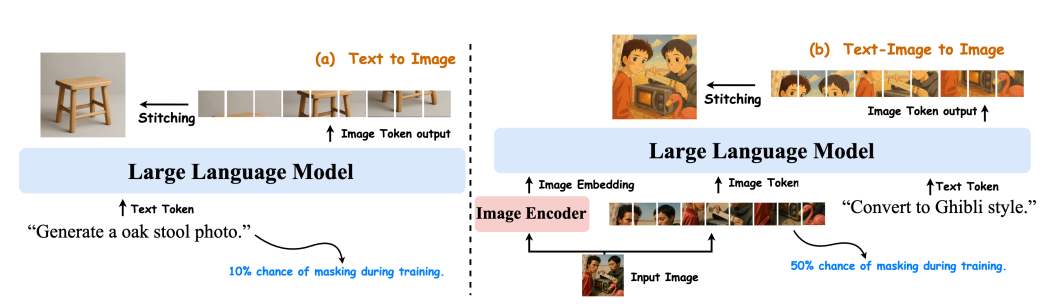
Janus-4o 是一個多模態 LLM,能夠進行文字轉圖像和文字+圖像轉圖像的生成。它基於 Janus-Pro,並使用 ShareGPT-4o-Image 資料集進行了微調。與 Janus-Pro 相比,Janus-4o 引入了文字+影像轉影像的生成功能,並在文字轉影像生成方面取得了顯著的改進。
數據集概述
ShareGPT-4o-Image 資料集包含 91,000 個 GPT-4o 影像產生樣本,分類如下:
- 文字轉圖片:45,717
- 文字加圖片轉圖片:46,539
相關連結
代碼: github點這裡
紙: 按這裡
論文介紹
多模態生成模型的最新進展已開啟逼真的、指令對齊的影像生成。然而,像 GPT-4o-Image 這樣的領先系統仍然是專有的,無法存取。
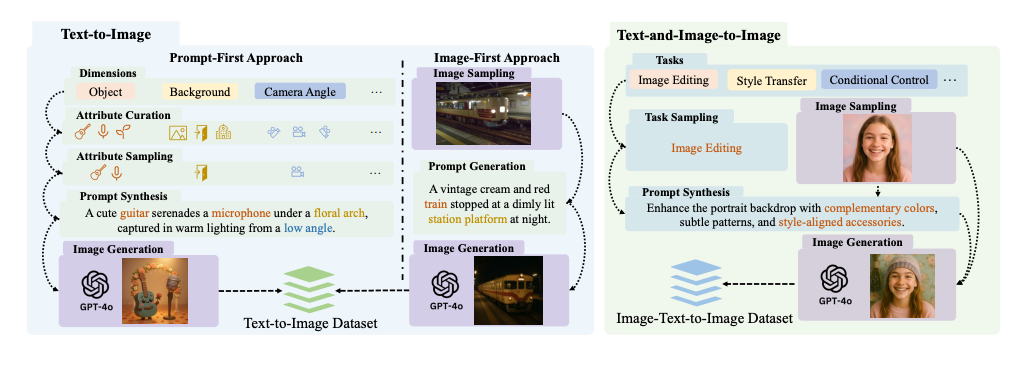
為了讓公眾能夠使用這些功能,本文推出了 ShareGPT-4o-Image,這是第一個包含 45,000 個文本到圖像和 46,000 個文本加圖像到圖像示例的數據集,所有這些示例都是使用 GPT-4o 的圖像生成功能合成的,以完善其高級圖像生成能力。利用該資料集,本文開發了 Janus-4o,這是一種能夠進行文字到圖像和文字加圖像到圖像生成的多模態大型語言模型。
Janus-4o 不僅在前代 Janus-Pro 的基礎上大幅提升了文字轉圖像的生成能力,還引入了文本加圖像轉圖像的生成能力。值得一提的是,它只使用 91K 合成樣本,在 8×A800 GPU 機器上訓練 6 小時,就從文字和圖像從頭生成圖像,取得了令人印象深刻的性能。
我們希望 ShareGPT-4o-Image 和 Janus-4o 的發布能促進照片般逼真、指令對齊影像產生的開放研究。
方法概述
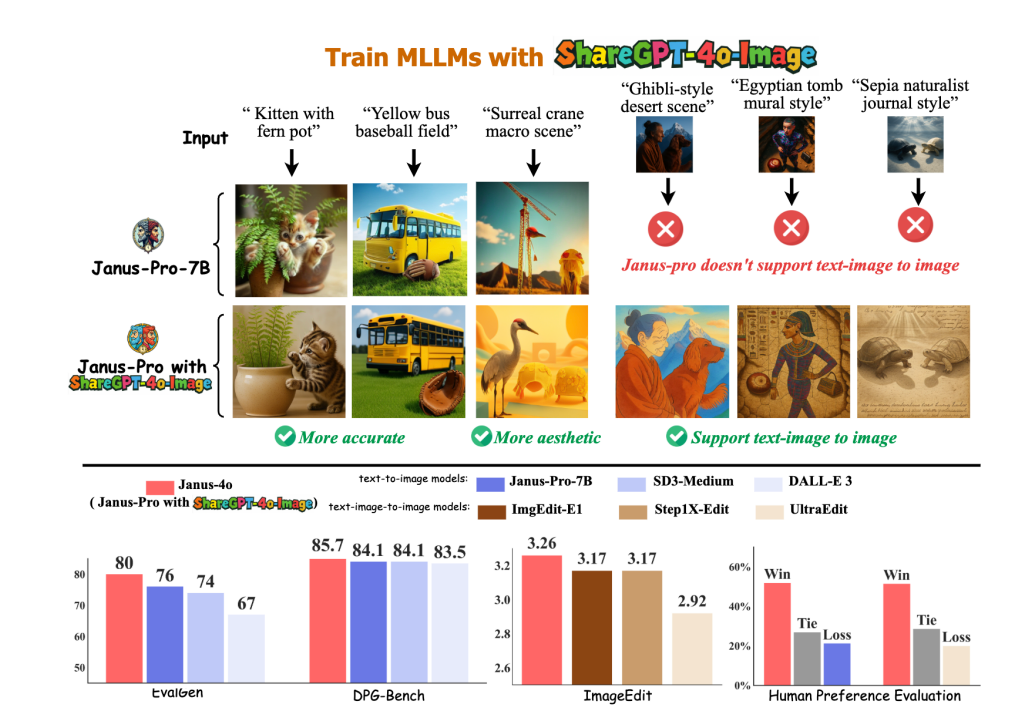
ShareGPT-4o-Image 增強了影像生成效能。 透過使用 ShareGPT-4o-Image 對 Janus-Pro 進行微調,我們產生了 Janus-4o,其影像生成效能顯著提升。 Janus-4o 也支援文字轉圖像和圖像轉圖像的生成,僅用 91,000 個訓練樣本就超越了其他基準測試。
Janus-4o 模型概述。 該模型基於 Janus-Pro,並透過在 ShareGPT-4o-Image 上進行微調而建構。它包含增強功能,以支援文字轉圖像和圖像轉圖像的生成。文字轉圖像和文字轉圖像任務均採用聯合訓練。
實驗結果

結論
ShareGPT-4o-Image 是首個能夠捕捉 GPT-4o 在文字轉影像和文字轉影像產生方面先進影像產生能力的大規模資料集。基於此資料集,本文開發了 Janus-4o,這是一種機器學習模型 (MLLM),能夠從純文字或圖文組合生成高品質圖像。
Janus-4o 在文字轉圖像生成方面取得了顯著的提升,並在文字轉圖像任務中取得了極具競爭力的成績,展現了 ShareGPT-4o-Image 的高品質和實用性。
得益於基於MLLM的自回歸影像產生的高效性,Janus-4o 僅需6小時便可在8×A800 GPU 機器上完成訓練,並以極低的運算需求實現顯著的效能提升。


