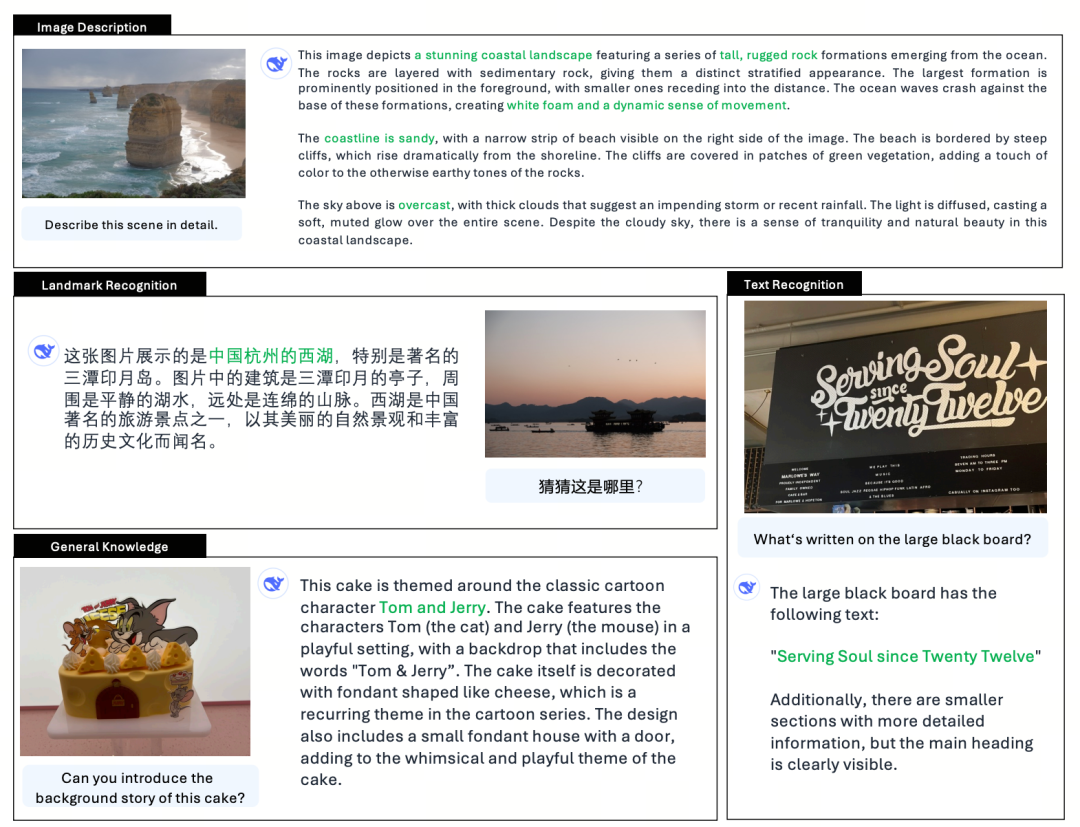
春節前夕,DeepSeek-R1機型正式發布。憑藉其純 RL 架構,它汲取了 CoT 的偉大創新,並超越了 聊天GPT 數學、編碼和邏輯推理。
此外,其開源模型權重、低訓練成本以及便宜的 API 價格,也讓 DeepSeek 在網路上大受歡迎,甚至讓 NVIDIA 和 ASML 的股價一度暴跌。
在爆红的同时,DeepSeek还发布了多模态大模型Janus(简纳斯)的升级版本Janus-Pro,继承了上一代多模态理解和生成的统一架构,优化了训练策略,扩展了训练数据和模型规模,带来了更强的性能。

Janus-Pro
Janus-Pro 是一個統一的多模態語言模型 (MLLM),可以同時處理多模態理解任務和產生任務,即可以理解圖片內容,也可以產生文字。
它解耦了多模態理解和生成的視覺編碼器(即圖像理解的輸入以及圖像生成的輸入和輸出使用不同的標記器),並使用統一的自回归變換器進行處理。
作為先進的多模態理解和生成模型,它是之前 Janus 模型的升級版。
在羅馬神話中,Janus (傑納斯) 是一個雙面的守護神,象徵著矛盾和轉換。他有兩張臉,這也暗示 Janus 模型可以理解並產生影像,非常貼切。那麼 PRO 究竟升級了什麼?
Janus 作為 1.3B 的小模型,與其說是正式版本,不如說是預覽版本。它探索的是統一的多模態理解和生成,但存在很多問題,例如圖像生成效果不穩定、與用戶指令偏差大、細節不足等。
Pro 版本優化了訓練策略,增加了訓練資料集,並在提供 1B 模型的同時,提供更大的模型 (7B) 供選擇。
模型架構
Jaus-Pro 和 Janus 在模型架構方面完全相同。(僅 1.3B!Janus 統一了多模態理解和生成)
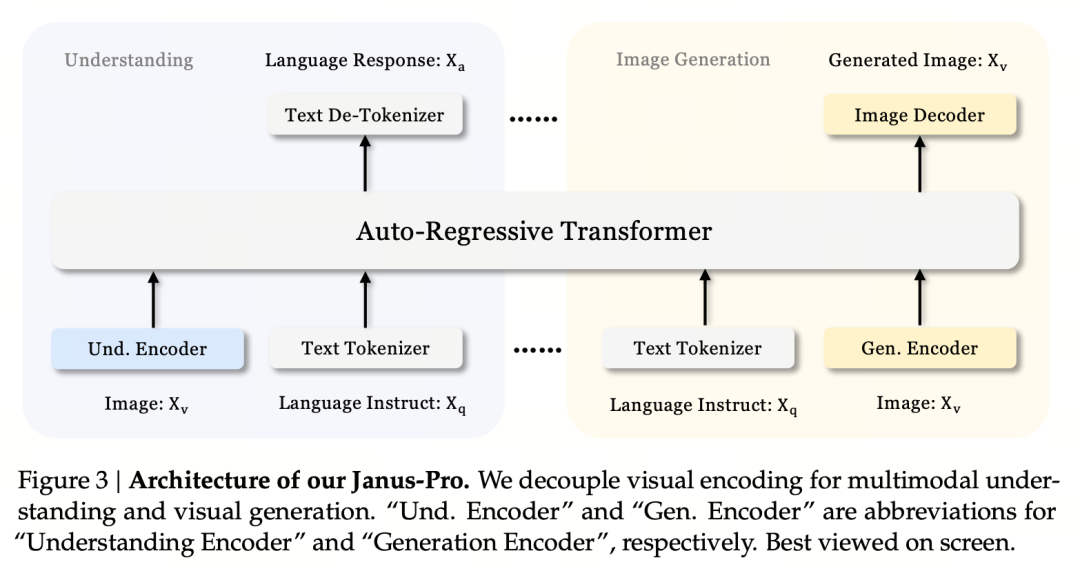
其核心設計原則是解耦視覺編碼,以支援多模態理解和生成。Janus-Pro 分別對原始圖像/文字輸入進行編碼、擷取高維特徵,並透過統一的自回歸變形器進行處理。
多模態影像理解使用 SigLIP 對影像特徵進行編碼(上圖中藍色編碼器),而生成任務則使用 VQ tokenizer 對影像進行離散化(上圖中黃色編碼器)。最後,所有的特徵序列都會輸入到 LLM 進行處理
訓練策略
在訓練策略方面,Janus-Pro 做了更多的改進。舊版的 Janus 採用了三階段的訓練策略,第一階段訓練輸入適配器和影像產生頭進行影像理解和影像產生,第二階段進行統一的預訓練,第三階段在此基礎上微調理解編碼器。(Janus 訓練策略如下圖所示)。
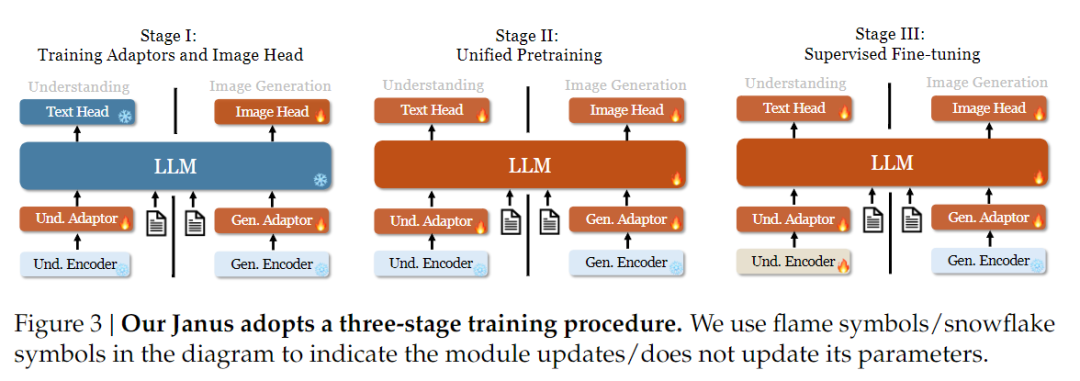
然而,此策略在第二階段使用 PixArt 方法將文字轉換成影像的訓練分割,導致計算效率偏低。
為此,我們延長了 Stage I 的訓練時間,並加入使用 ImageNet 資料的訓練,使模型能在固定 LLM 參數的情況下,有效地建立像素依賴關係的模型。在 Stage II 中,我們捨棄 ImageNet 資料,直接使用文字圖像對資料進行訓練,提高了訓練效率。此外,我們調整了第三階段的資料比例(多模態:純文字:視覺語義圖表資料從 7:3:10 調整為 5:1:4),在維持視覺生成能力的同時,提升了多模態理解能力。
訓練資料縮放
Janus-Pro 也在多模態理解和視覺生成方面擴展了 Janus 的訓練資料。
多模態理解:第二階段預訓資料以 DeepSeek-VL2 為基礎,包含約 9000 萬個新樣本,包括影像標題資料 (例如 YFCC) 以及表格、圖表和文件理解資料 (例如 Docmatix)。
StageⅢ的監督微調階段則進一步引入MEME理解、中文對話資料等,以提升模型在多任務處理與對話能力上的表現。
視覺生成:先前的版本使用低品質、高雜訊的真實資料,影響文字產生影像的穩定性與美感。
Janus-Pro 引入了約 7,200 萬個合成美學資料,使得真實資料與合成資料的比例達到 1:1。實驗顯示,合成資料可加速模型收斂,並顯著改善生成影像的穩定性和美學品質。
模型縮放
Janus Pro 將模型大小擴展到 7B,而之前版本的 Janus 使用 1.5B 的 DeepSeek-LLM 來驗證解耦(decoupling)視覺編碼的有效性。實驗顯示,更大的 LLM 能顯著加速多模態理解和視覺生成的收斂速度,進一步驗證了該方法的強大可擴展性。

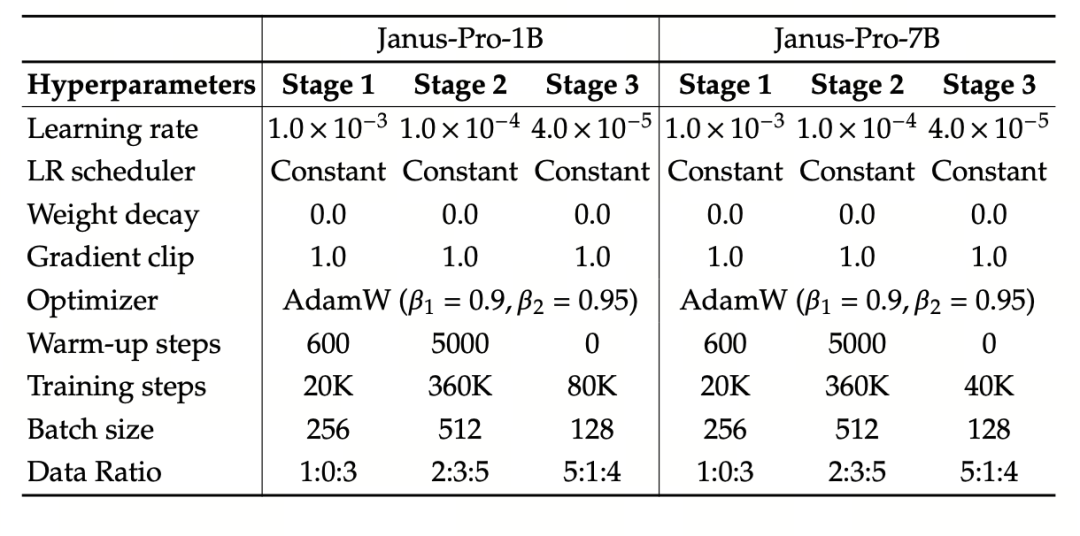
實驗使用 DeepSeek-LLM (1.5B 和 7B,支援最大序列為 4096) 作為基本語言模型。在多模態理解任務中,使用 SigLIP-Large-Patch16-384 作為視覺編碼器,編碼器的字典大小為 16384,圖像降取樣倍數為 16,理解適配器和生成適配器均為雙層 MLP。
第二階段訓練使用 270K 早期停止策略,所有影像均勻調整為 384×384 解析度,並使用序列包裝來提高訓練效率。Janus-Pro 使用 HAI-LLM 進行訓練與評估。1.5B/7B 版本分別在 16/32 節點 (8×Nvidia A100 每節點 40GB)上訓練了 9/14 天。
模型評估
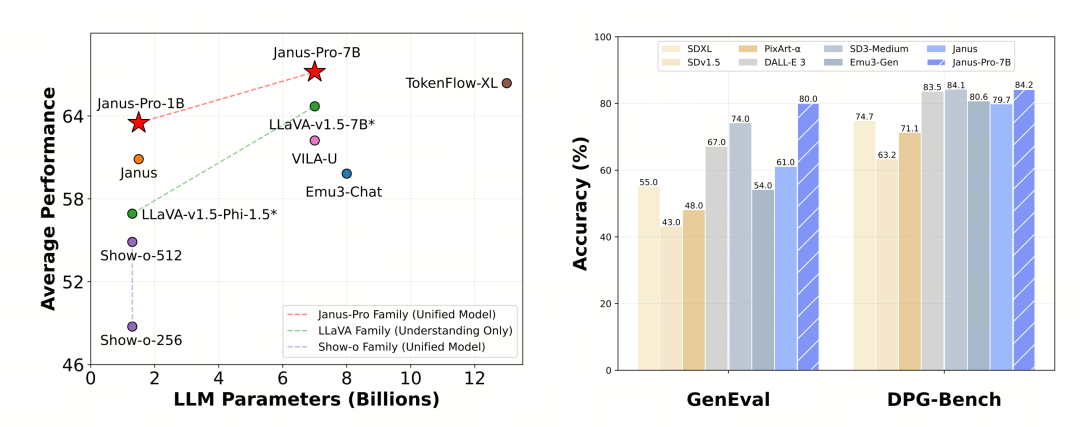
Janus-Pro 在多模態理解和生成方面分別進行了評估。總體而言,其理解能力可能稍弱,但在相同大小的開放原始碼模型中算是優異(猜想主要受限於固定的輸入解析度與 OCR 能力)。
Janus-Pro-7B 在 MMBench 基準測試中獲得 79.2 分,接近第一線開放原始碼機種的水準 (相同大小的 InternVL2.5 與 Qwen2-VL 約為 82 分)。不過,相較於上一代的 Janus,已有不錯的進步。
在圖像製作方面,相較於前一代的進步更為顯著,在開放原始碼機型中算是相當優秀的水準。Janus-Pro 在 GenEval 基準測試中的得分 (0.80) 也超過 DALL-E 3 (0.67) 和 Stable Diffusion 3 Medium (0.74) 等機種。