DeepSeek 已更新其網站。
除夕凌晨,DeepSeek突然在GitHub上宣布Janus專案空間開源了Janus-Pro模型和技術報告。
首先,讓我們強調幾個重點:
- 的 Janus-Pro 機型 這次推出的是多模式機型,可 可以同時執行多模態理解和影像產生任務。它共有兩個參數版本、 Janus-Pro-1B 和 Janus-Pro-7B.
- Janus-Pro 的核心創新在於將 多模態理解和生成這兩項不同的任務。這可讓這兩項任務在同一個模型中有效率地完成.
- Janus-Pro與DeepSeek去年10月發布的Janus模型架構一致,但當時Janus的量並不多。視覺領域的演算法專家 Charles 博士告訴我們,之前的 Janus「一般」,「比不上 DeepSeek 的語言模型」。

它旨在解決業界的難題:平衡多模態理解與影像生成
根據 DeepSeek 的官方介紹、 Janus-Pro 不僅可以理解圖片,提取並理解圖片中的文字,還可以同時生成圖片。
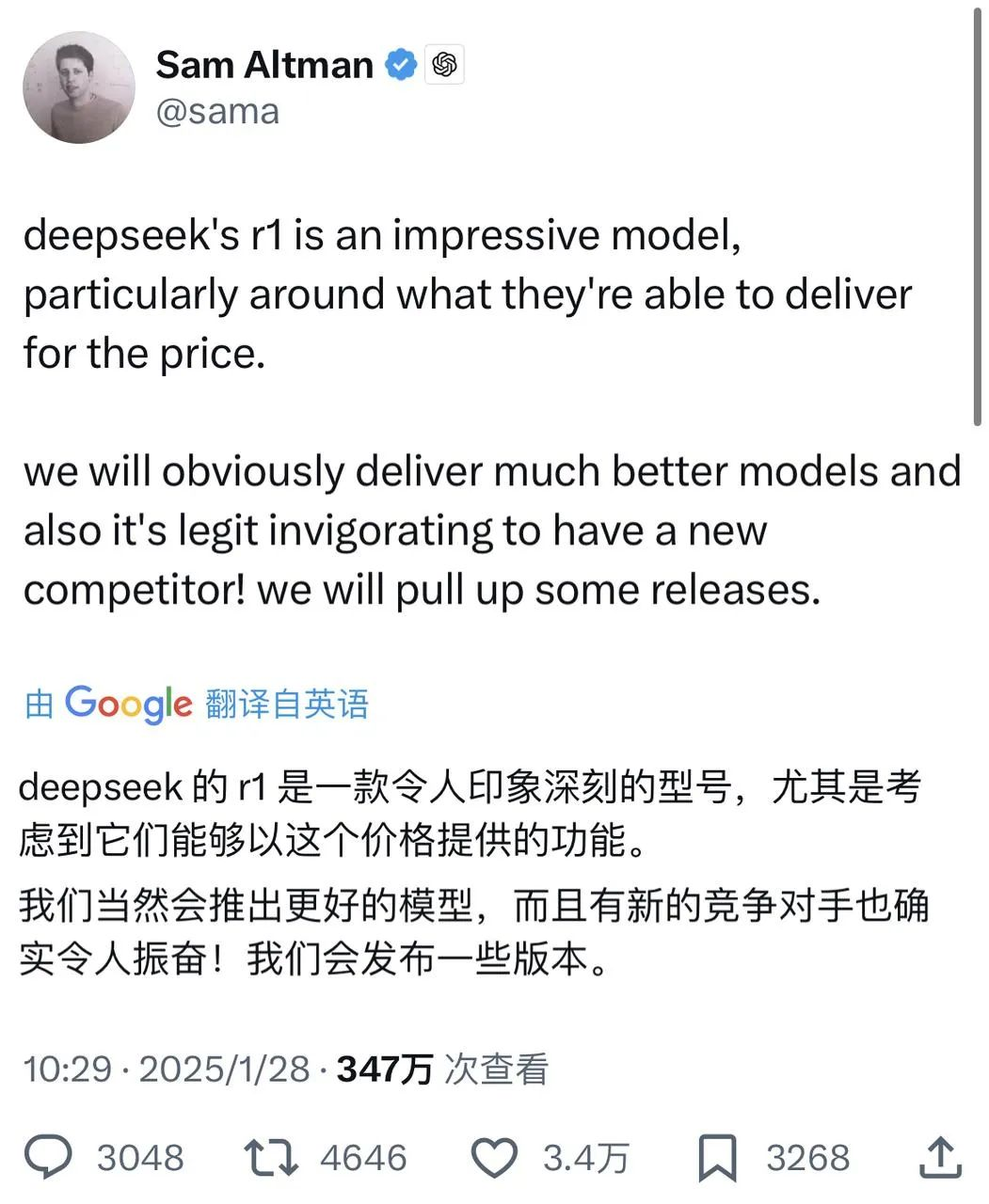
該技術報告提到,與其他同類型和等級的機型相比,Janus-Pro-7B 在 GenEval 和 DPG-Bench 測試集上的分數 超過 SD3-Medium 和 DALL-E 3 等其他機型。
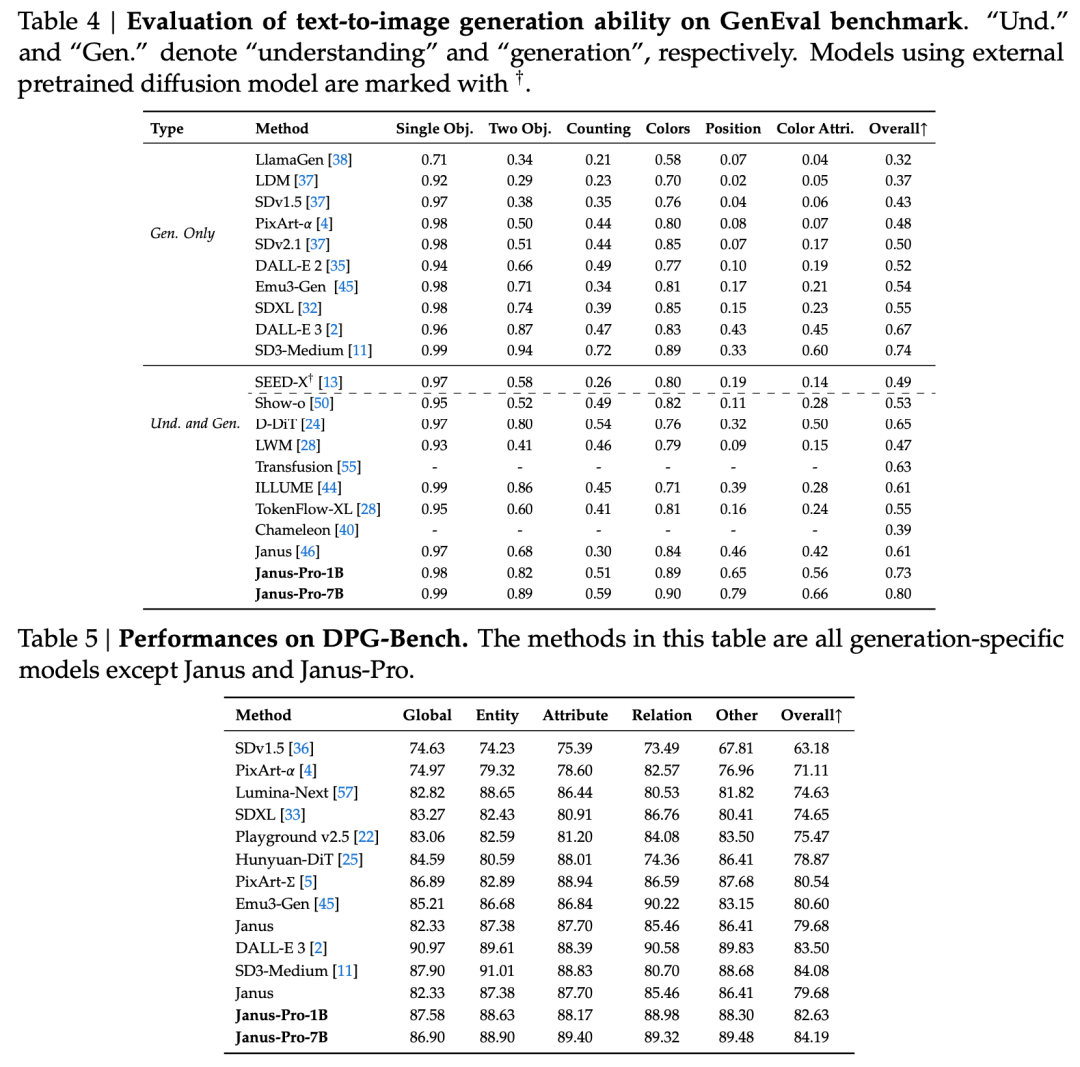
官方也舉例說明👇:
X 上也有許多網友在嘗試新功能。

但偶爾也會發生崩潰。
請參閱下列技術文件 深度搜尋, 我們發現 Janus Pro 是基於 Janus 的最佳化,而 Janus 是在三個月前發佈的。
本系列機型的核心創新在於 將視覺理解任務與視覺生成任務分開,以便平衡兩項任務的效果。
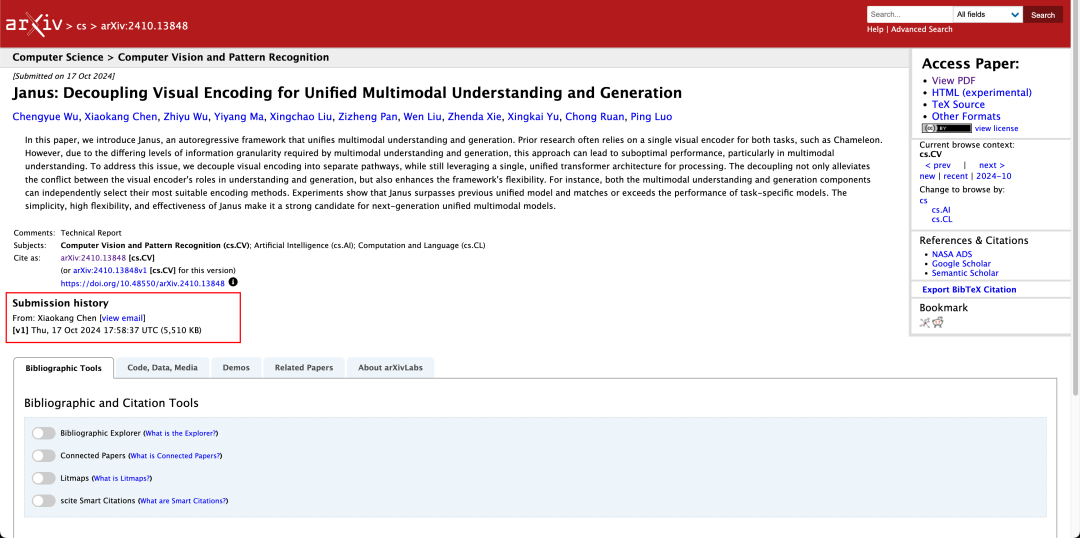
一個模型同時執行多模態理解與產生是很常見的。本測試集的 D-DiT 與 TokenFlow-XL 都具備此能力。
然而,Janus 的特點是 透過解耦處理,可執行多模態理解與產生的模型可平衡兩項任務的效能。
平衡兩項任務的成效是業界的難題。 以前的想法是盡可能使用相同的編碼器來實現多模態理解和生成。
這種方法的優點是架構簡單、沒有多餘的部署,而且與文字模型(也是使用相同的方法來達成文字產生與文字理解)一致。另一個論點是,這種融合多種能力的方式可以帶來一定程度的突現。
但事實上,將產生與理解融合後,兩者的任務會有衝突--圖像理解需要模型進行高維度抽象,萃取出圖像的核心語意,偏向於宏觀。而圖像產生則著重於像素層級局部細節的表達與產生。
業界的慣常做法是以影像產生能力為優先。這導致多模態模型 可以產生品質較高的影像,但影像理解的結果往往平平無奇。
Janus 的解耦架構和 Janus-Pro 的最佳化訓練策略
Janus 的解耦架構允許模型自行平衡理解和產生的任務。
根據官方技術報告的結果,不論是多模態理解或影像產生,Janus-Pro-7B 在多個測試集上都有良好的表現。

用於多模態理解、 Janus-Pro-7B 在七個評估資料集中的四個取得第一名,在其餘三個取得第二名,略微落後於排名第一的模型。
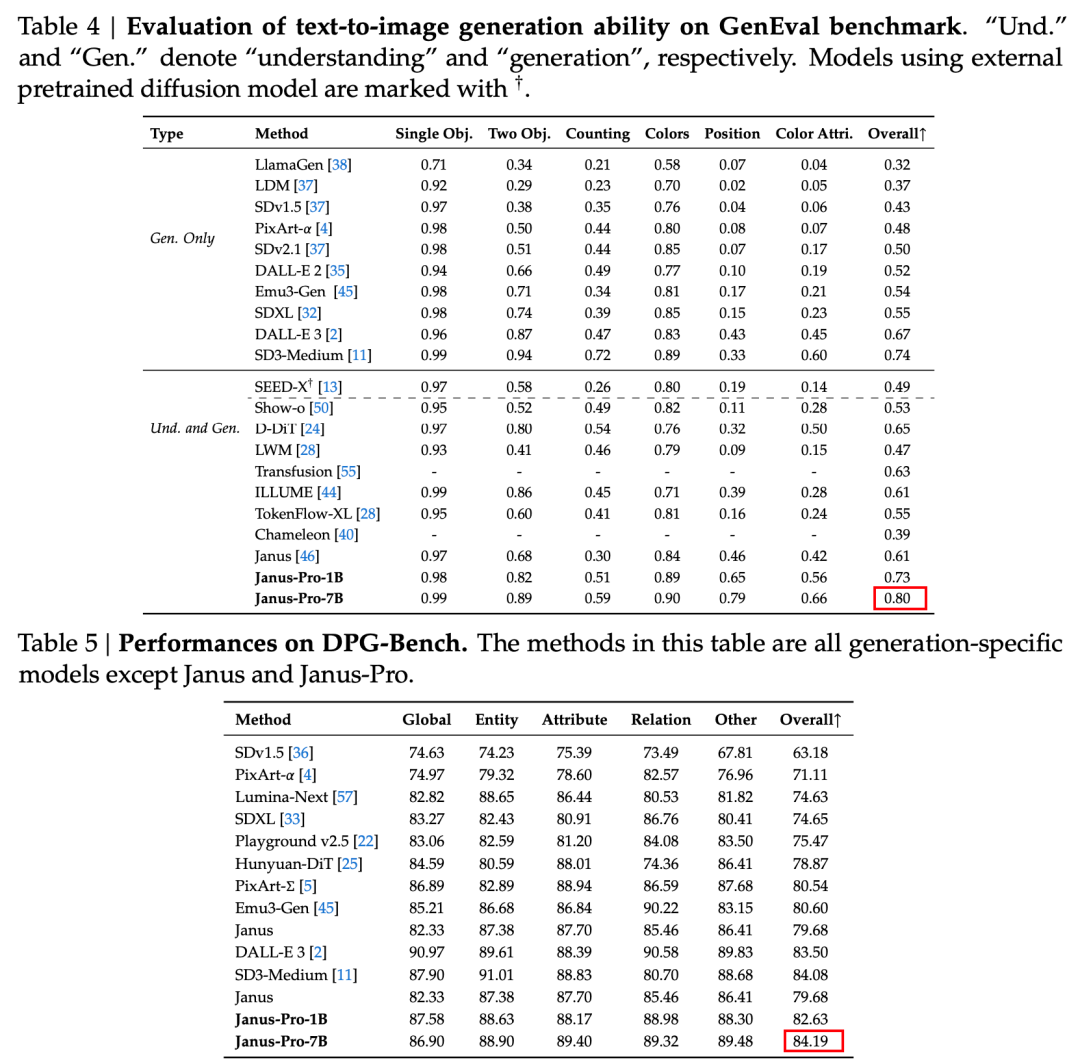
用於影像產生、 Janus-Pro-7B 在 GenEval 和 DPG-Bench 評估資料集上的總分都取得第一名。
這種多重任務的效果主要是由於 Janus 系列使用兩個視覺編碼器來處理不同的任務:
- 瞭解編碼器: 用於擷取影像中的語意特徵,以執行影像理解任務 (例如影像問答、視覺分類等)。
- 生成式編碼器: 將影像轉換為離散的表示方式 (例如使用 VQ 編碼器),以執行文字到影像的產生任務。
使用此架構、 該模型可獨立優化每個編碼器的性能,使多模態理解和生成任務各自達到最佳性能。
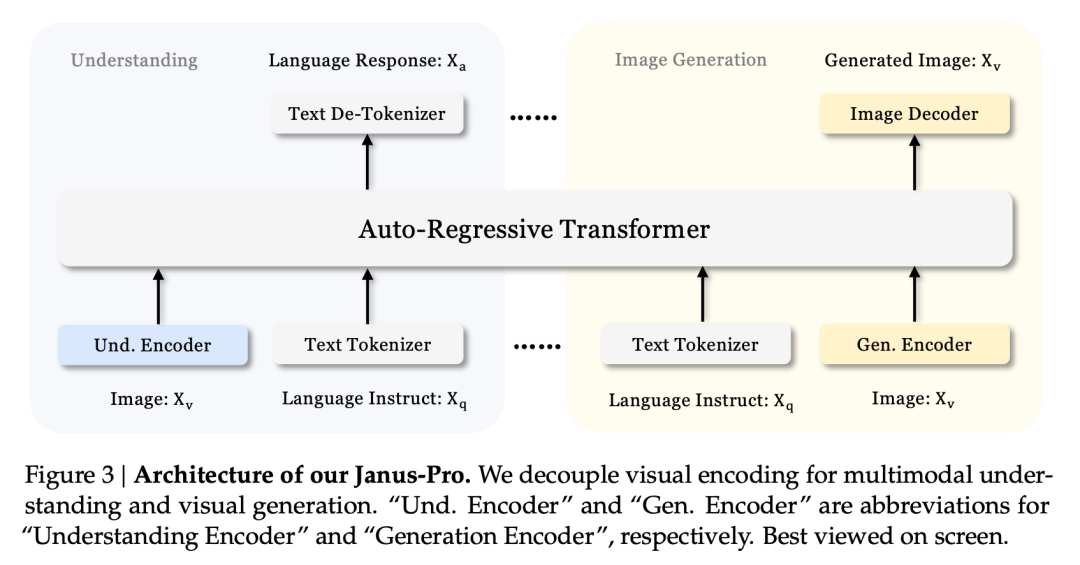
這種解耦架構是 Janus-Pro 和 Janus 的共通點。那麼,Janus-Pro 在過去幾個月有哪些迭代呢?
從評估集的結果可以看出,目前發行的 Janus-Pro-1B 與之前的 Janus 相比,在不同評估集的分數上有約 10% 到 20% 的改善。Janus-Pro-7B 在擴充參數後,相較於 Janus 有最高約 45% 的改善。

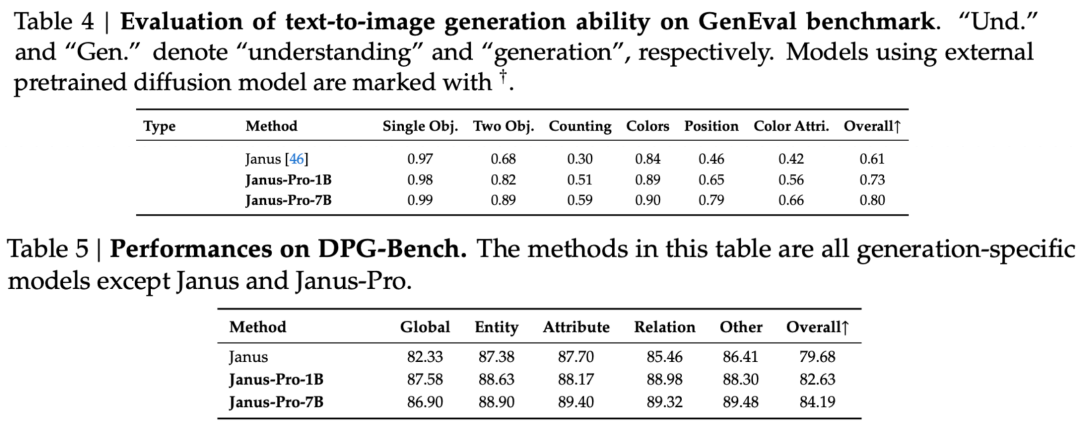
就訓練細節而言,技術報告指出,目前發行的 Janus-Pro 與先前的 Janus 機型相比,保留了核心的解耦架構設計,另外還迭代了 參數大小、訓練策略和訓練資料。
首先,我們來看看參數.
Janus 的第一個版本只有 1.3B 參數,目前發行的 Pro 包含 1B 和 7B 參數的模型。
這兩種尺寸反映了 Janus 架構的可擴展性。1B 機型是最輕的,外部使用者已經使用 WebGPU 在瀏覽器中執行。
還有 的 訓練策略。
依照 Janus 的訓練階段分法,Janus Pro 共有三個訓練階段,本文直接將它們分為階段 I、階段 II 和階段 III。
在保留各階段基本培訓思路和培訓目標的基礎上,Janus-Pro對三個階段的培訓時間和培訓數據進行了改進。以下是三個階段的具體改進:
第一階段 - 訓練時間較長
相較於 Janus,Janus-Pro 延長了第一階段的訓練時間,尤其是在視覺部分的適配器與影像頭的訓練。這表示視覺特徵的學習得到了更多的訓練時間,希望模型能夠充分理解圖像的細部特徵(例如像素到語義的映射)。
這種延伸訓練有助於確保視覺部分的訓練不會受到其他模組的干擾。
第二階段 - 移除 ImageNet 資料並加入多模式資料
在第二階段,Janus 先前參考了 PixArt,並分為兩部分進行訓練。第一部分使用 ImageNet 數據集進行圖像分類任務的訓練,第二部分則使用一般的文字到圖像資料進行訓練。第二階段約有三分之二的時間用在第一部分的訓練。
Janus-Pro 移除了第二階段的 ImageNet 訓練。此設計可讓模型在第二階段訓練時專注於文字到影像的資料。根據實驗結果,這可以大幅提高文字到影像資料的利用率。
除了訓練方法設計的調整之外,第二階段所使用的訓練資料集也不再僅限於單一的影像分類任務,而是加入了更多其他類型的多模態資料,例如影像描述、對話等,進行聯合訓練。
第三階段 - 優化資料比率
在第三階段訓練中,Janus-Pro 會調整不同類型訓練資料的比例。
之前,Janus 在第三階段使用的訓練資料中,多模態理解資料、純文字資料、文字對圖像資料的比例為 7:3:10。Janus-Pro 降低了後兩類資料的比例,並將三類資料的比例調整為 5:1:4,也就是更加重視多模態理解任務。
讓我們來看看訓練資料。
與 Janus 相比,Janus-Pro 這次大幅增加了高品質的 合成資料。
它擴大了多模態理解和影像產生的訓練資料數量和種類。
擴展多模態理解資料:
Janus-Pro 在訓練時會參考 DeepSeek-VL2 資料集,並額外增加約 9000 萬個資料點,不僅包括影像描述資料集,還包括表格、圖表和文件等複雜場景的資料集。
在有監督的微調階段(Stage III),繼續增加與 MEME 理解和對話(包括中文對話)經驗改善相關的資料集。
擴充視覺生成資料:
原始的真實世界資料品質不佳且雜訊程度高,導致模型產生的輸出不穩定,在文字轉影像的任務中,影像的美學品質不足。
Janus-Pro 在訓練階段增加了約 7,200 萬筆新的高美感合成資料,使得預訓階段的真實資料與合成資料比例達到 1:1。
合成資料的提示全部取自公共資源。實驗顯示,加入這些資料後,模型的收斂速度更快,產生的影像在穩定性和視覺美感上都有明顯的改善。
效率革命的延續?
總的來說,DeepSeek 這個版本為視覺化模型帶來了效率革命。
與著重於單一功能的視覺模型或偏重於特定任務的多模態模型不同,Janus-Pro 在同一模型中平衡了影像產生和多模態理解這兩項主要任務的效果。
此外,儘管參數較小,它仍在評估中勝過 OpenAI DALL-E 3 和 SD3-Medium。
延伸到地面,企業只需要部署一個模型,就可以直接實現圖像產生和理解這兩個功能。再加上只有 7B 的大小,部署的難度和成本都大大降低。
與之前發佈的 R1 和 V3 相連,DeepSeek 正以下列方式挑戰現有的遊戲規則 「精巧的架構創新、輕量化機型、開放源碼機型,以及超低的訓練成本」.這就是西方科技巨頭甚至華爾街恐慌的原因。
就在剛剛,被輿論橫掃多日的 Sam Altman 終於正面回應了 DeepSeek on X 的相關資訊--在稱讚 R1 的同時,他表示 OpenAI 將會發布一些消息。