
Ⅰ. ¿Qué es la destilación de conocimientos?
La destilación de conocimientos es una técnica de compresión de modelos utilizada para transferir conocimientos de un modelo grande y complejo (el modelo del profesor) a un modelo pequeño (el modelo del alumno).
El principio básico es que el modelo del profesor enseña al modelo del alumno mediante la predicción de resultados (como distribuciones de probabilidad o procesos de inferencia), y el modelo del alumno mejora su rendimiento aprendiendo de estas predicciones.
Este método es especialmente adecuado para dispositivos con recursos limitados, como teléfonos móviles o dispositivos integrados.
II.Conceptos básicos
2.1 Diseño de plantillas
- Plantilla: Formato estructurado utilizado para normalizar la salida del modelo. Por ejemplo
- : Marca el inicio del proceso de razonamiento.
- : Marca el final del proceso de razonamiento.
- : Marca el inicio de la respuesta final.
- : Marca el final de la respuesta final.
- Función:
- Claridad: Al igual que las "palabras clave" de una pregunta para rellenar un espacio en blanco, indica al modelo "el proceso de pensamiento va aquí, y la respuesta va allí".
- Coherencia: Garantiza que todos los resultados sigan la misma estructura, lo que facilita su posterior tratamiento y análisis.
- Legibilidad: los seres humanos pueden distinguir fácilmente entre el proceso de razonamiento y la respuesta, lo que mejora la experiencia del usuario.
2.2 Trayectoria de razonamiento: La "cadena de pensamiento" de la solución del modelo
- Trayectoria de razonamiento: Los pasos detallados generados por el modelo al resolver un problema muestran la cadena lógica del modelo.
- Por ejemplo:
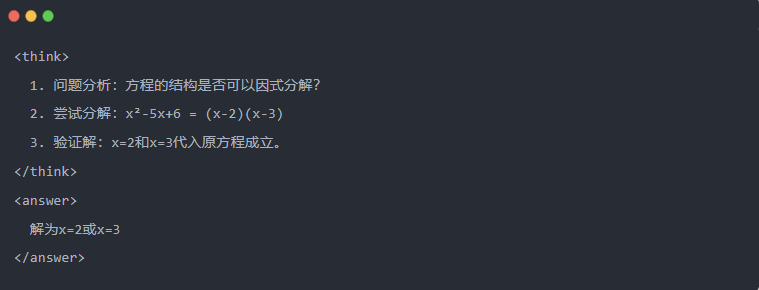
2.3 Muestreo de rechazo: Filtrar los datos buenos de "prueba y error
- Muestreo de rechazo: Generar múltiples respuestas de candidatos y quedarse con las buenas, de forma similar a cuando se escribe un borrador y luego se copia la respuesta correcta en un examen.
Ⅲ.Generación de datos destilados
El primer paso en la destilación de conocimientos es generar "datos didácticos" de alta calidad para que los pequeños modelos aprendan de ellos.
Fuentes de datos:
- 80% a partir de los datos de razonamiento generados por DeepSeek-R1
- 20% de los datos de tareas generales de DeepSeek-V3.
Proceso de generación de datos de destilación:
- Filtrado de reglas: comprueba automáticamente la corrección de la respuesta (por ejemplo, si la respuesta matemática se ajusta a la fórmula).
- Control de legibilidad: elimina las lenguas mixtas (por ejemplo, chino e inglés mezclados) o los párrafos largos.
- Generación guiada por plantillasrequiere que DeepSeek-R1 genere trayectorias de inferencia de acuerdo con la plantilla.
- Filtrado de muestreo de rechazo:
- Integración de datosFinalmente se generaron 800.000 muestras de alta calidad, incluidos unos 600.000 datos de inferencia y unos 200.000 datos generales.
Ⅳ.Proceso de destilación
Funciones del profesor y del alumno:
- DeepSeek-R1 como modelo de profesor;
- Modelos de la serie Qwen como modelo de estudiante.
Etapas de formación:
En primer lugar, la introducción de datos: hay que introducir la parte de la pregunta de las 800.000 muestras en el modelo Qwen y pedirle que genere una trayectoria de inferencia completa (proceso de pensamiento + respuesta) de acuerdo con la plantilla. Este es un paso muy importante
A continuación, cálculo de pérdidas: comparar la salida generada por el modelo del alumno con la trayectoria de inferencia del modelo del profesor, y alinear la secuencia de texto mediante ajuste fino supervisado (SFT). Si no está seguro de lo que es el SFT, espero que busque esta palabra clave para saber más
Completar las actualizaciones de parámetros para el modelo mayor del alumno: Optimizar los parámetros del modelo Qwen mediante retropropagación para aproximar la salida del modelo del profesor.
Repitiendo este proceso de formación varias veces se garantiza que los conocimientos se transfieren suficientemente. De este modo se alcanza el objetivo original de la formación. Le daremos un ejemplo para demostrarlo, y esperamos que lo entienda
Ⅴ. Ejemplo de demostración
El artículo demuestra el efecto de destilación a través de una tarea específica de resolución de ecuaciones (resolver ecuación):
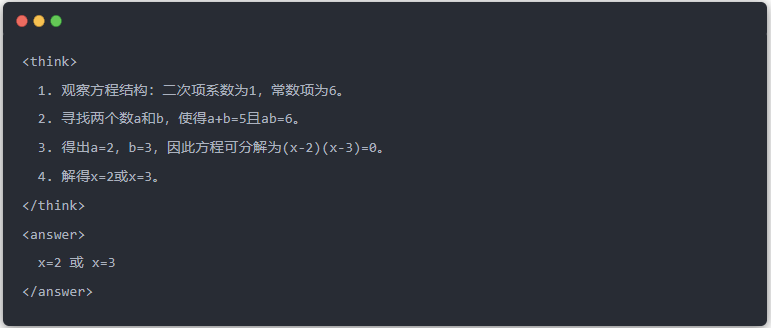
- Salida estándar del modelo de profesor:
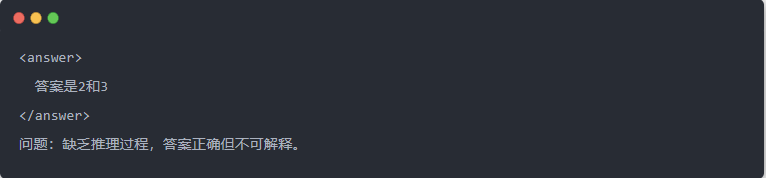
- Salida de Qwen-7B antes de la destilación:
- Salida de Qwen-7B tras la destilación:
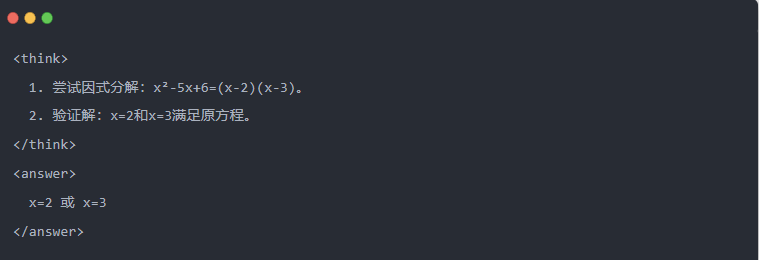
- Solución optimizada: Se genera un proceso de inferencia estructurado y la respuesta es la misma que el modelo del profesor.
Ⅵ. Resumen
Mediante la destilación de conocimientos, la capacidad de inferencia de DeepSeek-R1 se migra de forma eficiente a la serie Qwen de modelos pequeños. Este proceso se centra en la salida templada y el muestreo de rechazo. Mediante la generación de datos estructurados y un entrenamiento refinado, los modelos pequeños también pueden realizar tareas de inferencia complejas en escenarios con recursos limitados. Esta tecnología proporciona una referencia importante para el despliegue ligero de modelos de IA.



