

Aspectos más destacados
🔹 Arquitectura unificada de transformadores: Un único modelo se encarga de la comprensión de las imágenes y eliminando la necesidad de sistemas separados.
🔹 Escalable y de código abierto: Disponible en 1B y 7B versiones paramétricas (con licencia MIT), optimizadas para diversas aplicaciones y uso comercial.
🔹 Rendimiento de vanguardia: Supera a DALL-E 3 de OpenAI y a Stable Diffusion en pruebas como GenEval y DPG-Bench.
🔹 Implantación simplificada: La arquitectura racionalizada reduce los costes de formación/información al tiempo que mantiene la flexibilidad.
Enlaces de modelos
- Janus-Pro-7B: HuggingFace
- Janus-Pro-1B: HuggingFace
- GitHub: Código y documentos
Por qué destaca Janus-Pro
1. Dos superpoderes en un solo modelo
- Entender el modo: Utiliza SigLIP-L (las "supergafas") para analizar imágenes (de hasta 384×384) y texto.
- Modo de generación: Aprovecha Flujo rectificado + SDXL-VAE (el "pincel mágico") para crear imágenes de alta calidad.
2. Cerebro y formación
- LLM básico: Construido sobre el potente modelo de lenguaje de DeepSeek (1,5B/7B parámetros), destacando en el razonamiento contextual.
- Formación: Preentrenamiento en conjuntos de datos masivos → Ajuste fino supervisado → Optimización EMA para obtener el máximo rendimiento.
3. ¿Por qué sobredifusión en el transformador?
- Versatilidad de tareas: Prioriza la comprensión unificada + la generación, mientras que los modelos de difusión se centran únicamente en la calidad de la imagen.
- Eficacia: Generación autorregresiva (un solo paso) frente a la eliminación de ruido iterativa de la difusión (por ejemplo, 20 pasos para la difusión estable).
- Relación coste-eficacia: Una única red troncal Transformer simplifica la formación y el despliegue.
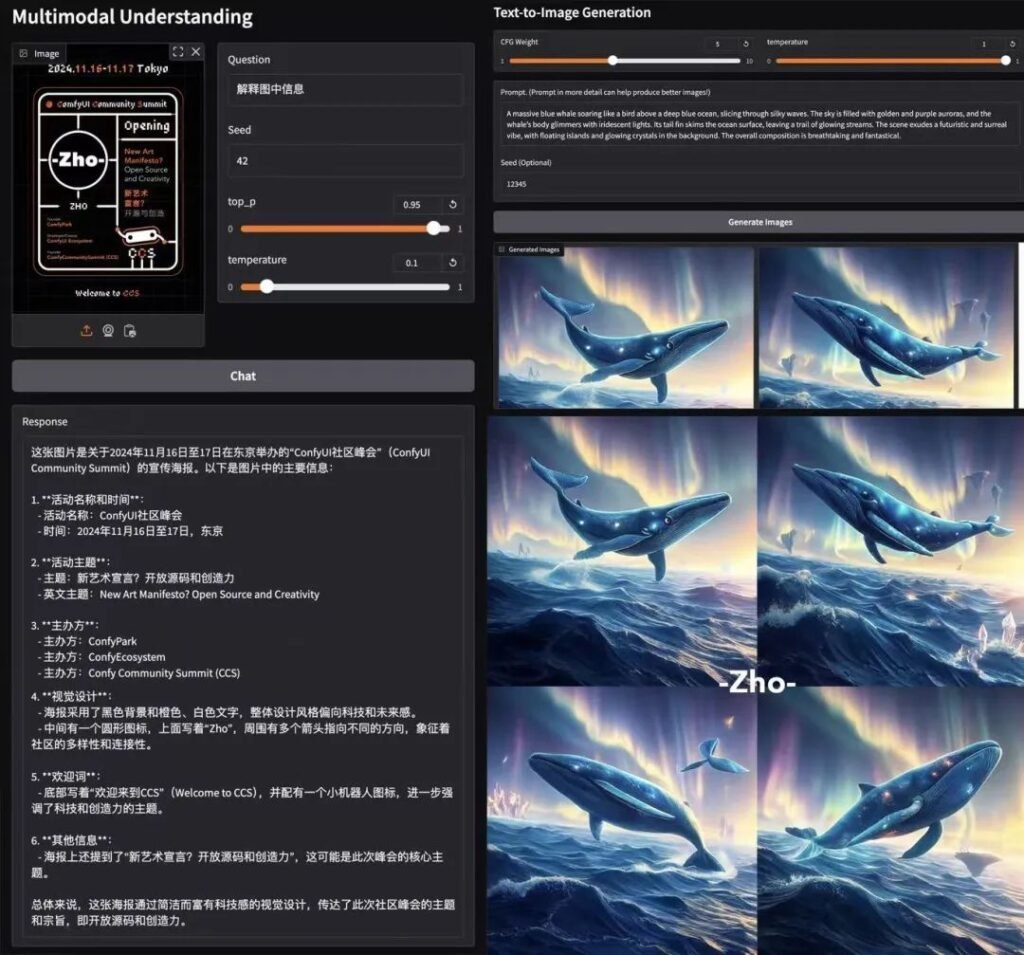
Dominio de las referencias
📊 Comprensión multimodal
Janus-Pro-7B supera a los modelos especializados (por ejemplo, LLaVA) en cuatro pruebas de referencia clave, escalando suavemente con el tamaño de los parámetros.
🎨 Generación de texto a imagen
- GenEval: Coincide con SDXL y DALL-E 3.
- DPG-Bench: 84.2% precisión (Janus-Pro-7B), superando a todos los competidores.
Pruebas en el mundo real
- Velocidad: ~15 segundos/imagen (GPU L4, 22GB VRAM).
- Calidad: Cumplimiento estricto de los plazos, aunque hay que pulir pequeños detalles.
- Demostración Colab: Prueba Janus-Pro-7B (Se requiere nivel Pro).
Desglose técnico
Arquitectura
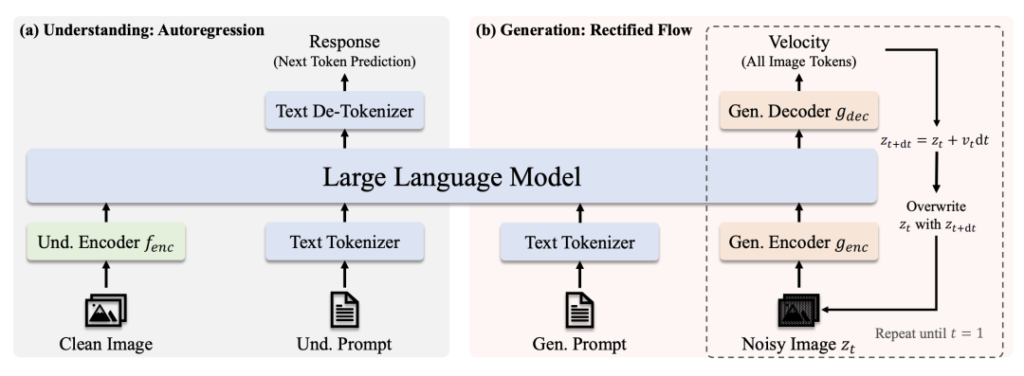
- Comprender el camino: Imagen limpia → Codificador SigLIP-L → LLM → Respuesta de texto.
- Ruta de generación: Imagen ruidosa → Decodificador de flujo rectificado + LLM → Eliminación de ruido iterativa.
Innovaciones clave
- Codificación visual desacoplada: Las vías separadas para la comprensión/generación evitan el "conflicto de roles" en los módulos de visión.
- Núcleo de transformador compartido: Permite la transferencia de conocimientos entre tareas (por ejemplo, el aprendizaje de los conceptos de "gato" ayuda tanto al reconocimiento como al dibujo).
Comunidad
AK (Investigador de IA): "La sencillez y flexibilidad de Janus-Pro lo convierten en un candidato ideal para los sistemas multimodales de nueva generación. Al desacoplar las vías de visión y mantener un Transformer unificado, equilibra la especialización con la generalización, algo poco frecuente".
Por qué es importante la licencia MIT
- Libertad: Utilizar, modificar y distribuir comercialmente con restricciones mínimas.
- Transparencia: El acceso total al código acelera las mejoras impulsadas por la comunidad.
Conclusión
Janus-Pro de DeepSeek no es sólo otro modelo de IA: es un cambio de paradigma. Al unificar la comprensión y la generación bajo un mismo techo, abre las puertas a herramientas creativas más inteligentes, aplicaciones en tiempo real y despliegues rentables. Con acceso a código abierto y licencia del MIT, podría ser el catalizador de la próxima ola de innovación multimodal. 🚀
Para desarrolladores: Echa un vistazo a la Nodos ComfyUI ¡y únete a la ola de la experimentación!
este post está patrocinado por:


